Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
ongoing by Tim Bray
ongoing fragmented essay by Tim BrayCoachella 2025 14 Apr 2025, 9:00 pm
Last weekend I spent a few hours watching Coachella on YouTube. The audio and video quality are high. It’s free of ad clutter, but maybe that’s because I pay for Google Music? The quality of the music is all over the map. If I read the schedule correctly, they’ll repeat the exercise next weekend, so I thought a few recommendations might be helpful. Even if it’s not available live, quite a few captures still seem to be there on YouTube, so check ’em out.
I tried sorting these into themes but that tied me in knots, so you get alphabetical order.

Lady Gaga brings it.
Blonde Redhead
Not sure what kind of music to call this, but the drums and guitar (played by identical twins Simone and Amedeo Pace) are both hot, and Kazu Makino on everything else has loads of charisma, and they all sang well. Didn’t regret a minute of my time with this one.
Ben Böhmer
I have no patience whatsoever for EDM. Deadmau5 and Zedd and their whole tribe should go practice goat-herding in Bolivia or anything else that’ll keep them away from audiences who want to hear music played by musicians. But there were multiple artists this year you could describe as X+EDM for some value of X, and much to my surprise a few of them worked.
(One that notably didn’t was Parcels, whose genius idea is EDM+Lightweight Aussie pretty-boy pop. On top of which, every second of their performance featured brilliant lights strobing away, shredding my retinas and forebrain. I say it’s EDM and I say to hell with it. Go back to Australia and stay.)
But Mr Böhmer not only held my attention but had my toes tappin’. His stuff isn’t just hot dance moves against recorded tracks, it’s moody and cool and phase-shifty and dreamy. It helps that he plays actual musical notes on actual keyboards.
Beth Gibbons
I thought “I remember that name.” (Sadly, on first glance at the schedule I did not in fact recognize many names.) Ms Gibbons was the singer for Portishead, standard-bearers of Trip-hop back in the day. Her voice sounds exactly the same today as it did three decades ago, which is to say vulnerable and lovely.
The songs were all new (aside from Portishead’s Glory Box) and good. Beth never had any stage presence and still doesn’t, draped motionless over the mike except when she turns away from the crowd to watch someone soloing.
What made the show a Coachella highlight was the band, who apparently had just arrived from another planet. It was wonderfully strange as in I didn’t even know what some of the instruments were. Anyhow it all sounded great albeit weird, the perfect complement to Beth’s spaced-out (I mean that in the nicest way) vocal arcs.
Go-Gos
This posse of sixtysomething women won my heart in the first three seconds of their set with a blast of girl-group punk/surf guitar noise and a thunderous backbeat. The purest rock-&-roll imaginable, played with love and bursting with joy. They can sing, they can play, they still have plenty of moves. It‘s only rock and roll but I like it, like it, yes I do.
HiTech
OK, this is another X+EDM, where the X is “Ghettotech, house, Rap & Miami base” (quoting their Web site). I have no idea what “Miami base” is but I guess I like it, because they’re pretty great. Outta Detroit.
Their set was affably chaotic, the rapping part sharp-edged and hot, and they had this camera cleverly mounted on the DJ deck giving an intense close-up of whichever HiTech-ers were currently pulling the levers and twisting the knobs. Sometimes it was all three of them and that was great fun to watch.
I’m an elderly well-off white guy and am not gonna pretend to much understanding of any of HiTech’s genres, but I’m pretty confident that a lot of people would be entertained.
Kraftwerk sigh
They are historically important but the show, I dunno, I seem to recall being impressed in 1975 but it felt kinda static and tedious. The only reason I mention them is that a few of their big video-backdrop screens, near the start of the set, were totally Macrodata Refinement, from Severance. I wonder if any of the showrunners were Kraftwerk fans?
LA Phil, conducted by Gustavo Dudamel
Give Coachella credit for giving this a try. Dudamel is a smart guy and put together a program that wasn’t designed to please a heavy classics consumer like me. I mean, opening with Ride of the Valkyries? But there were two pieces of Bach and the orchestra turned into a backup band for Laufey, an Icelandic folk/jazz singer, a Gospel singer/choir, and some other extremely random stuff. If you’re not already a classics fan, this might open your eyes a bit.
Lady Gaga
I’m sure you’ve already read one or two rave write-ups about this masterpiece. It’s going to be one of the performances remembered by name forever, like Prince at the Superbowl or Muddy Waters at the Last Waltz. They built a freaking opera house in the desert, and that makes me wonder what the Coachella economics are; someone has to pay for this stuff, do Gaga and Coachella split it or is it the price of getting her to come and play?
To be fair, as the review in Variety accurately noted, it was pretty well New-York-flavored hoofing and belting wrapped in a completely incomprehensible Goth/horror narrative. So what?! The songs were great. The singing was fantastic and the dancing white-hot, plus she had a pretty hard-ass live metal-adjacent band and an operatic string section, and she brought her soul along with her and unwrapped it. It was easy to believe she loved the audience just as much as she said. She didn’t leave anything on the stage. They should make it into a big-screen movie.
I did feel a little sorry for the physical audience, quite a bit of the performance seemed to be optimized for couch potatoes with big screens like for example me. Anyhow, if you get a chance to see this one don’t miss it.
Other headliners?
There were three nights and thus three headliners. You’ll notice that I only talked up Friday night’s Lady-Gaga set. That’s because the other two were some combination of talentless and uninspired and offensive. Obviously I’m in a minority here, they wouldn’t get the big slots if millions didn’t love ’em. And I like an unusually wide variety of musical forms. But not that shit.
The CoSocialist Future 5 Apr 2025, 9:00 pm
This week marks the second anniversary of the launch of the CoSocial.ca Mastodon server, which is one leg of my online presence (the other is this blog.) I’ve never been more convinced that online social interaction has to change paths and take a new direction. And I think CoSocial has lessons to teach about that direction. Here are some.
A personal note: I’ve been fortunate in that bits and pieces of my career have felt like building the future. For example, right now, about the Fediverse generally and CoSocial in particular. In this essay I’ll try to explain why. But it’s a fine feeling.
Decentralized
This is maybe the biggest thing. The Web, by design, is decentralized. You don’t need permission to put up any kind of Web server or service. Social media should follow the decentralized path blazed by the Web and by the world’s oldest and most successful conversational app, namely email.
It seems painfully obvious that a network of thousands or millions of servers, independently operated, sizes ranging from tiny to huge, is inherently more flexible and resilient than having all the conversations owned and operated by one globally-centralized business empire.
To be decentralized, you need a protocol framework so the servers can talk to each other. CoSocial uses ActivityPub, which at the moment I think is the best choice.
Some smart people who like the Bluesky experience are trying to make its AT Protocol work in a way that’s as demonstrably decentralized as ActivityPub is today. Maybe they’ll succeed; then operations like CoSocial should maybe consider it as an alternative. We’ll see.
Not for profit
Our goals do not include enriching any investors. We plan to pay the people who do the work and have just advertised for our first paid position.
We’re not-for-profit because the goals of the investor community are incompatible with a healthy online experience. In 2025, companies are judged on profit growth; everything else is secondary. If you can grow your audience organically, good, but the world is finite, so when you’ve attracted everyone you’re going to, you’re going to have to focus on raising prices and reducing costs. Which is likely to produce an unpleasant experience for the people you serve.
Cory Doctorow aptly uses “enshittification” to describe this often-observed pattern.
A registered co-operative
There are a lot of different ways to set up a not-for-profit. The simplest organization is no organization: Someone buys a domain name, puts up a server, invites people on board, and uses Patreon donations to keep the lights on.
Which is exactly what Chad did at Mstdn.ca, and it seems to be working OK. It’s a testament to the strong fibres of the Web, still there after all these decades of corrupting big money, that you can just do this without asking anyone’s permission, and get away with it.
But we didn’t. We are a registered co-operative in BC, Canada’s westernmost province. It took us a couple of months to pull together the Board and constitution and bylaws. We have to file annual reports and comply with governing legislation.
I am absolutely not going to suggest that a cooperative is the optimal not-for-profit approach. But I am pretty convinced that if you want to be treated as an organic component of civil society, you should work within its frameworks. Plus, it seems to me, on the evidence, that member-owned cooperatives are a pretty great way to organize human activities.
More than a click to join
As I write this, most modern social-media products let you just roll up to the Web site and say “I wanna join”, and they say “click here”. Or even just make a couple of API calls.
We’re not like that. You have to apply for membership and offer a few words about why. Then you have to [*gasp*] pay. A big fifty Canadian dollars a year buys a co-op membership and a Fediverse account. The first year of Fediverse is $40 so we can book $10 of your initial payment as payment for a CoSocial share (refundable if you later cancel).
When you apply, we check that you did so from an IP address in Canada, we glance at your reasons for wanting to join, then if you haven’t already contributed, we send you an email asking you to pony up and, once you have, we let you in.
The whole thing takes maybe five minutes of effort from the new member and a CoSocial moderator.
What matters about this process? The fact that it exists. Nicole the Fediverse Chick can’t get a CoSocial account, nor can any other flavor of low-rent griefer or channer or MAGA chud. Just the fact that you can’t join by calling a few APIs filters out most of the problems, and then being asked to, you know, pay a little money, takes care of the rest.
Which is to say, being a CoSocial moderator is dead easy. Sure, we get reports on our members from time to time. So far, zero have been really worrying. On a small single-digit-number of times, we’ve asked a member to consider the fact that they seem to be irritating some people.
And we throw reports from Hasbara keyboard warriors and similarly non-credible sources on the floor.
The key take-away: Imposing just a little teeny-tiny bit of friction on the onboarding process seems to achieve troll-resistance in one easy step.
Transparent
We have a bank account and credit cards and so on, but we run all our finances through a nice service called OpenCollective. Which makes all our financial moves 100% transparent: Here they are.
No Advertising
CoSocial has none, and never will.
It is a repeating pattern that advertising-supported social-media products offered by for-profit enterprises become engulfed in a tempest of controversy and litigation.
Since it’s axiomatic that centralized social media has to be free to use, ads are required, which means the advertisers are the customers. Those customers will continuously agitate for more intrusive advertising capabilities and for brand protection by avoiding sex, activism, or anything that might make anyone uncomfortable.
I don’t know about you, but I’m interested in sex and activism.
Intellectually, I appreciate that advertising should be a normal facet of a functional economy. How else am I going to find out what’s for sale? But empirically, advertising as it’s done now seems to exert a powerfully corrupting influence.
The only way forward?
I’m not claiming that CoSocial is. But I am arguing strongly for the combination of decentralization, not-for-profit, legal registration, non-zero onboarding friction, transparency, and advertising rejection. There are lots of ways to shape resilient social-media products that do these things. There are other legally regulated non-profit structures that aren’t co-ops.
Also, there are plenty of other organizations that would benefit from hosting social-media voices: Government departments, academic institutions, sports teams, fan clubs, marketing groups, professional societies, videogame platforms, and, well, the list is long.
How’s CoSocial doing?
Slow and steady. We’re tiny, less than 200 strong, but we get a few new members every month. Two years in, a grand total of two members have decided not to renew.
We’ve got a modestly pleasing buildup of money in the bank account, which means that we need to get serious about becoming less volunteer-centric, and thus more resilient.
The service is fun to use, it’s reliable, and about as troll-free as can be. Come on in!
(But only if you’re in Canada and willing to pay a bit.)
Latest Music (feat. Qobuz) 27 Mar 2025, 8:00 pm
I’ve written a lot about ways of listening to music; in the current decade about liking YouTube Music but then about de-Googling. What’s new is that I’m spending most of my time with Plexamp and Qobuz. The trade-offs are complicated.
YouTube Music
I liked YTM because:
It let me upload my existing ten thousand tracks or so, which include many oddities that aren’t on streamers.
It did a good job of discovering new artists for me.
The Android Auto integration lets me say “Play Patti Smith” and it just does the right thing.
But the artist discovery has more or less ran out of gas. I can’t remember the last time I heard something new that made me want more, and when I play “My Supermix”, it seems to always be the same couple of dozen songs, never anything good and new.
Also: Bad at classical.
I think I might keep on paying for YTM for the moment, because I really like to watch live concerts before I go to bed, and it seems like YTM subscribers never see any ads, which is worth something.
Plexamp
I wrote up what it does in that de-Googling link. Tl;dr: Runs a server on a Mac Mini at home and lets me punch through to it from anywhere in the world. I’ve been listening to it a lot, especially in the car, since YTM got boring.
My back inventory of songs contains many jewels from CDs that I bought and loved in like 1989 or 2001 and subsequently forgot all about, and what a thrill when one of them lights up my day.
I still feel vaguely guilty that I’m not paying Plex anything, but on the other hand what I’m doing costs them peanuts.
But, I still want to hear new stuff.
Qobuz
I vaguely knew it was out there among the streamers, but I got an intense hands-on demonstration recently while shopping for new speakers; Phil at audiofi pulled up all my good-sound demo tracks with a couple of taps each, in what was apparently CD quality. Which opened my eyes.
What I like about Qobuz:
It pays artists more per stream than any other service, by a wide margin.
It seems to have as much music as anyone else.
It’s album-oriented, and I appreciate artists curating their own music.
Classical music is a first-class citizen.
While it doesn’t have an algorithm that finds music it thinks I’ll like, it is actively curated and they highlight new music regularly, and pick a “record of the week”. This week’s, for example, is For Melancholy Brunettes (& Sad Women) by Japanese Breakfast. It’s extremely sweet stuff, maybe a little too low-key for me, but I still enjoyed it. They’re coming to town, I might go.
This isn’t the only weekly selection that I’ve enjoyed. Qobuz gives evidence of being built by people who love music.
What don’t I like about Qobuz? The Mac app is kinda dumb, I sometimes can’t figure out how to do what I want, and for the life of me I can’t get it to show a simple full-screen display about the current song. But the Android app works OK.
As for Qobuz’s claim to offer “Hi-Res” (i.e. better than CD) sound, meh. I’m not convinced that this is actually audible and if it in principle were, I suspect that either my ears or my stereo would be a more important limiting factor.
Records!
Yep, I still occasionally drop the needle on the vinyl on the turntable, and don’t think I’ll ever stop.
And a reminder
If you really want to support artists, buy concert tickets. That thrill isn’t gone at all.
Long Links 17 Mar 2025, 8:00 pm
This will be the 30th “Long Links” post. The frequency has fallen off over the years; perhaps my time for long-form pieces has decreased or, just as likely, I protect my sanity in these dark days by consuming less. No, I don’t filter out Fascist Craziness, because it’s a thing that needs to be understood to be resisted. Thus, today’s Long Links does contain “the world is broken” pieces.” But not only; there’s good news here too, including fine typography and music.
Let’s start with music.
Music
“All of Bach is a project of the Netherlands Bach Society with the aim to perform and record all of Bach's works and share them online with the world for free.” The project manifests on YouTube and I have spent a lot of hours enjoying it. The performances are all competent and while I disagree with an artistic choice here or there, I also think that many of these are triumphs.
One such triumph, and definitely a Long link, is Bach’s last work, The Art of Fugue, BWV 1080. Bach didn’t say which order the many parts of the piece should be performed in, or what instruments should be used, so there’s a lot of scope for choice and creativity in putting together a performance. This one is by Shinsuke Sato, the maestro of the Netherlands Bach Society. It is clever, unfancy, and its ninety or so minutes are mostly exquisite.
Vi Hart, mathemusician is now a Microsoftie, but has been one of my intellectual heroes. Get a comfy chair and pull up Twelve Tones, which addresses profound themes with a combination of cynicism, fun, music, and laserbats. You will need a bit of basic music literacy and intellectual flexibility, but you’ll probably end up smarter.
IsraPal
On the “everything is broken” front, Israel/Palestine looms large. Here are two New York Times gift links that face the ugliness with clear eyes. First, ‘No Other Land’ Won an Oscar. Many People Hope You Don’t See It is what the title says. Second, it’s bad that criticism of Israel has become Thoughtcrime, and worse when AI is weaponized to look for it.
Tchaikovsky Opera
Adrian not Pyotr, I mean, and space opera not musical costume drama. In particular, The Final Architecture series. It’s ultra-large-scale space opera in three big fat volumes. I would say it’s mining the same vein as The Expanse and while it didn’t hit me nearly as hard as that did, it’s fun, will keep you turning pages.
Photography
I’m a photography enthusiast and as a side-effect am gloomy about pro photogs’ increasing difficulty in making a living. I also buy a lot of stuff online. For both these reasons, What WhiteWall’s New Shopify Integration Means to Photographers caught my eye. First of all, it’s generally cool that someone’s offering a platform to help photogs get online and sell their wares.
Second, I can’t help but react to Shopify’s involvement. This gets complicated. First of all, Shopify is Canadian, yay. But, CEO Tobi Lütke is a MAGA panderer and invites wastrels like Breitbart onto the platform. And having said all that, speaking as a regular shopper, the Shopify platform is freaking excellent.
Whenever I’m on a new online merchant and I see their distinctive styling around the “Proceed to payment” button, I know this thing is gonna Just Work. A lot of times, once I’ve typed in my email address, it says “OK, done”, because it shares my payment data from merchant to merchant. Occasionally it’ll want me to re-authenticate or send a security code to my phone or or whatever.
If I were setting up an online store to sell anything, that’s what I’d use. I mean, I’d hold my nose and let the company know that they need to fire their CEO for treason, but it’s still what I’d probably use.
Speaking of photography, I’ve repeatedly written about “C2PA”, see On C2PA and C2PA Progress. I’m not going to explain once again what it is, but for those who know and care, it looks like Sony is doubling down on it, yay Sony!
Vancouver
Vancouver residents who know the names “Concord Pacific” or “Terry Hui”, or who have feelings about False Creek, will probably enjoy Terry Hui’s Hole in Vancouver’s Heart. You will have noticed some of the fragments of this bit of history going by, but Geoff Meggs puts it all together on a large vivid canvas that will you better informed and probably somewhat mind-boggled.
Let’s talk about TV!
By which I mean a video screen used recreationally. Check out Archimago’s HDMI Musings: high speed cables, data rates, YCbCr color subsampling, Dolby Vision MEL/FEL, optical cables and +5V injection. Yes, that’s a long title, and it’s a substantial piece, because HDMI is increasingly how you connect any two video-centric pieces of technology.
From which I quote: “This recent update makes HDMI the fastest of all currently-announced consumer Audio-Video connection standards, the one wire that basically does it all”. I’m not going to try to summarize, but if you plow through this one you’ll know a lot more about those black wires all over your A/V setup. There’s lots of practical advice; it turns out that if you’re going to run an HDMI cable further than about two meters, certification matters.
Life online
Where do people learn about the world from? The Pew Research Center investigated and published Social Media and News Fact Sheet. I suspect the results will surprise few of you, but it’s nice to have quantitative data. I would hope that a similar study, done next year not last year, would include decentralized social media, which this doesn’t.
I know that Ed Zitron’s Never Forgive Them went viral, and I bet a lot of you saw it go by, or even started reading then left it parked in a tab you meant to get back to, because it’s so long. Yeah; it’s arguably too long and too shrill, but on the other hand it is full of truth and says important things I’ve not seen elsewhere.
For example, I suspect most people reading this are angry about the ubiquitous enshittification of the online, but Zitron points out that people like us suffer much less because we have the money and the expertise to dodge and filter and route around a lot of the crap. Zitron actually purchased one of the most popular cheap Windows PCs — the kind of device ordinary people can afford — and reports from the front lines of what is in part a class war. The picture is much worse than you thought it was.
Here are a few bangers:
“It isn’t that you don’t ’get‘ tech, it’s that the tech you use every day is no longer built for
you, and as a result feels a very specific kind of insane.”
“almost every single interaction with technology, which is required to live in modern society, has become actively
adversarial to the user”.
“The average person’s experience with technology is one so aggressive and violative that I believe it
leaves billions of people with a consistent low-grade trauma.”
Publishing tech
It’s where I got my start. Two of the most important things are typography and color. And there’s good news!
The Braille Institute offers Read Easier With Our Family of Hyperlegible™ Fonts, which begins “Is this font easy for you to read? Good—that’s the idea.” Like! Would use. And in an era where the Web is too much infested by teeny-tiny low-contrast typography, it’s good to have alternatives.
Now, as for color: It is a sickeningly complex subject, both at the theory level and in the many-layered stack of models and equations and hardware and software that cause something to happen on a screen that your brain perceives as color. Bram Cohen, best-known for inventing BitTorrent, has been digging in, and gives us Color Theory and A Simple Color Palette. I enjoyed them.
Geekery
If you know what “IPv6” is, then Geoff Huston’s The IPv6 Transition will probably interest you. Tl;dr: Don’t hold your breath waiting for an all-IPv6 Internet.
And, much as I’d like to, it’s difficult to avoid AI news. So here is plenty, from Simon Willison, who has no AI axe to grind nor product to sell: Things we learned about LLMs in 2024.
Business
I can testify from personal experience that Andy Jassy is an extremely skilled manager, but I found Amazon and the endangered future of the middle manager, from CNBC, unconvincing. The intro: “Jassy's messaging on an increased ratio of individual contributors to managers raises a much bigger question about organizational structure: What is the right balance between individual workers and managers in overall headcount?” There’s talk of laying off many thousands of managers.
Before I worked at Amazon I was at Google, which has a much higher IC/manager ratio. Teams of 20 were not uncommon, and as a result, there was both a manager and a Tech Lead, which meant the manager was basically an HR droid. Amazon always insisted that the manager sweat the details of what their team was working on, deeply understand the issues they were facing and what they were building. I don’t see how that’s compatible with increasing the ratio.
And, Google management was way weaker than Amazon’s, not even close. So I’d have to say that the evidence is against Andy on this one.
Art island
Japan has one. It’s called Naoshima. Great idea. I’d go.
Totem Tribe Towers 7 Mar 2025, 9:00 pm
I bought new speakers. This story combines beautiful music with advanced analogue technology and nerdy obsession. Despite which, many of you are not fascinated by high-end audio; you can leave now. Hey, this is a blog, I get to write about what excites me. The seventeen of you who remain will probably enjoy the deep dive.

Totem Tribe Tower loudspeakers, standing on a subwoofer.
This picture makes them look
bigger than they really are. They come in black or white, satin or gloss finish.
Prettier with the grille on, I think.
Why?
My main speakers were 22 years old, bore scars from toddlers (now grown) and cats (now deceased). While they still sounded beautiful, there was loss of precision. They’d had a good run.
Speakers matter
Just in the last year, I’ve become convinced, and argued here, that both DACs and amplifiers are pretty well solved problems, that there’s no good reason to spend big money on them, and that you should focus your audio investments on speakers and maybe room treatment. So this purchase is a big deal for me.
How to buy?
The number of boutique speaker makers, from all over the world, is mind-boggling; check out the Stereophile list of recommendations. Here’s the thing: Pretty well all of them sound wonderful. (The speakers I bought haven’t been reviewed by Stereophile.)
So there are too many options. Nobody could listen to even a small proportion of them, at any price point. Fortunately, I had three powerful filters to narrow down the options. The speakers had to (1) look nice, and (2) be Canadian products, probably (3) from Totem Acoustic.
Decor?
I do not have, nor do I want, a man-cave. I’ve never understood the concept.
And you have to be careful. There are high-end speakers, some very well-reviewed, with design sensibilities right out of Mad Max or Brazil. And then a whole bunch that are featureless rectangles with drivers on the front.
Ours have to live in a big media alcove just off the kitchen; they are shared by the pure-audio system and the huge TV. The setup has to please the eyes of the whole family.
Canadian?
At this point in time, a position of “from anywhere but the US, the malignant force threatening our sovereignty” would be unsurprising in a Canadian. But there are unsentimental reasons, too. It turns out Canadian speaker makers have had an advantage stretching back many decades.
This is mostly due to the work of Floyd Toole, electrical engineer and acoustician, once an employee of Canada’s National Research Council, who built an anechoic chamber at the NRC facility, demonstrated that humans can reliably detect differences in speaker accuracy, and made his facility available to commercial speaker builders. So there have been quite a few good speakers built up here over the years.
Totem?
What happened was, in 1990 or so I went to an audio show down East somewhere and met Vince Bruzzese, founder of Totem Acoustic, who was showing off his then-brand-new “Model One” speakers. They were small, basic-black, and entirely melted my heart playing a Purcell string suite. They still sell them, I see. Also, the Totem exhibit was having a quiet spell so there was time to talk, and it turned out that Bruzzese and I liked a lot of the same music.
So I snapped up the Model Ones and that same set is still sounding beautiful over at our cabin. And every speaker I’ve bought in the intervening decades has come from Totem or from PSB, another excellent Toole-influenced Canadian shop. I’ve also met and conversed with Paul Barton, PSB’s founder and main brain. Basically, there’s a good chance that I’ll like anything Vince or Paul ship.
My plan was to give a listen to those two companies’ products. A cousin I’d visited last year had big recent PSB speakers and I liked them a whole lot, so they were on my menu. But PSB seems to have given up on audio dealers, want to sell online. Huh?! Maybe it’ll work for them, but it doesn’t work for me.
So I found a local Totem dealer; audiofi in Mount Pleasant.
Auditioning
For this, you should use some of your most-listened-to tracks from your own collection. I took my computer along for that purpose, but it turned out that Qobuz had ’em all. (Hmm, maybe I should look closer at Qobuz.)
Here’s what was on my list. I should emphasize that, while I like all these tracks, they’re not terribly representative of what I listen to. They’re selected to stress out a specific aspect of audio reproduction. The Americana and Baroque and Roots Rock that I’m currently fixated on are pretty easy to reproduce.
200 More Miles from the Cowboy Junkies’ Trinity Session. Almost any track from this record would do; they recorded with a single ambiphonic microphone and any competent setup should make it feel like you’re in the room with them. And Margo’s singing should make you want to cry.
The Longships, from Enya’s Watermark album. This is a single-purpose test for low bass. It has these huge carefully-tuned bass-drum whacks that just vanish on most speakers without extreme bass extension, and the music makes much less sense without them. You don’t have to listen to the whole track; but it’s fine music, Enya was really on her game back then.
The opening of Dvořák’s Symphony #9, “From the New World”. There are plenty of good recordings, but I like Solti and the Chicago Symphony. Dvořák gleefully deploys jump-scare explosions of massed strings and other cheap orchestration tricks in the first couple of minutes to pull you into the symphony. What I’m looking for is the raw physical shock of the first big full-orchestra entrance.
Death Don’t Have No Mercy from Hot Tuna’s Live At Sweetwater Two. Some of the prettiest slide guitar you’ll hear anywhere from Kaukonen, and magic muscle from Casady. And then Jorma’s voice, as comfortable as old shoes and full of grace. About three minutes in there’s an instrumental break and you want to hear the musical lines dancing around each other with no mixups at all.
First movement of Beethoven’s Sonata #23, “Appassionata”, Ashkenazy on London. Pianos are very difficult; two little speakers have a tiny fraction of the mass and vibrating surface of a big concert grand. It’s really easy for the sound to be on the one hand too small, or on the other all jumbled up. Ashkenazy and the London engineers do a fine job here; it really should sound like he’s sitting across the room from you.
Cannonball, the Breeders’ big hit. It’s a pure rocker and a real triumph of arrangement and production, with lots of different guitar/keys/drum tones. You need to feel it in your gut, and the rock & roll edge should be frightening.
Identikit from Radiohead’s A Moon Shaped Pool. This is mostly drums and voice, although there are eventually guitar interjections. It’s a totally artificial construct, no attempt to sound like live musicians in a real space. But the singing and drumming are fabulous and they need to be 100% separated in space, dancing without touching. And Thom Yorke in good voice had better make you shiver a bit.
Miles Runs The Voodoo Down from Bitches Brew. This is complex stuff, and Teo Macero’s production wizardry embraces the complexity without losing any of that fabulous band’s playing. Also Miles plays two of the greatest instrumental solos ever recorded, any instrument, any genre, and one or two of the ascending lines should feel like he’s pulling your whole body up out of your chair.
Emmylou Harris. This would better be phrased as “Some singer you have strong emotional reactions to.” I listened to the title track and Deeper Well from the Wrecking Ball album. If a song that can make you feel that way doesn’t make you feel that way, try different speakers.
The listening session
I made an appointment with Phil at Audiofi, and we spent much of an afternoon listening. I thought Audiofi was fine, would go back. Phil was erudite and patient and not pushy and clearly loves the technology and music and culture.
I was particularly interested in the Element Fire V2, which has been creating buzz in online audiophile conversation. They’re “bookshelf” (i.e. stand-mounted) rather than floorstanders, but people keep saying they sound like huge tower speakers that are taller than you are. So I was predisposed to find them interesting, and I listened to maybe half of the list above.
But I was unhappy, it just wasn’t making me smile. Sure, there was a stereo image, but at no point did I get a convincing musicians-are-right-over-there illusion. It was particularly painful on the Cowboy Junkies. It leapt satisfactorily out of the speakers on the Dvořák and was brilliant on Cannonball, but there were too many misses.
Also, the longer I looked at it the less it pleased my eyes.
“Not working, sorry. Let’s listen to something else” I said. I’d already noticed the Tribe Towers, which even though they were floorstanders, looked skinny and pointy compared to the Elements. I’d never read anything about them but they share the Element’s interesting driver technology, and are cheaper.
So we set them up and they absolutely aced everything the Elements had missed. Just vanished, I mean, and there was a three-dimensional posse of musicians across the room, filling the space with three-dimensional music. They flunked the Enya drum-thwack test but that’s OK because I have a subwoofer (from PSB) at home. In particular, they handled Ashkenazy pounding out the Beethoven just absolutely without effort. I’m not sure I’ve ever heard better piano reproduction.
And the longer I looked at them the more my thinking switched from “skinny and pointy” to “slender and elegant”.
A few minutes in and, I told Phil, I was two-thirds sold. He suggested I look at some Magico speakers but they were huge and like $30K; as an audiophile I’m only mildly deranged. And American, so no thanks.
I went home to think about it. I was worried that I’d somehow been unfair to the Elements. Then I read the Stereophile review, and while the guy who did the subjective listening test loved ’em, the lab measurements seemed to show real problems.
I dunno. Maybe that was the wrong room for them. Or the wrong amplifier. Or the wrong positioning. Or maybe they’re just a rare miss from Totem.
My research didn’t turn up a quantitative take on the Tribes, just a lot of people writing that they sound much bigger than they really are, and that they were happy they’d bought them.
And I’d been happy listening to them. So I pulled the trigger. My listening space is acoustically friendlier than the one at Audiofi and if they made me happy there, they’d make me happy at home.
And they do. Didn’t worry too much about positioning, just made sure it was symmetric. The first notes they played were brilliant.
But how does it sound?
See all those auditioning tracks up above, where it says what speakers “should” do? They do, that’s what they sound like.
I’ve been a little short on sleep, staying up late to listen to music.
Follow-up: Customer service
As noted above I have a subwoofer, and my preamp lets you configure where to roll off the bass going to the main speakers and hand off to the subwoofer. I wrote off to Totem’s customer-support email address wondering if they had any guidance on frequency. They got back to me with specific advice, and another couple of things to double-check.
High-end audio. Simpatico salespeople. The products last decades. The vendors answer emails from random customers. Businesses it’s still possible to like.
Bye, Prime 6 Mar 2025, 9:00 pm
Today I canceled my Amazon Prime subscription.

Why?
As I wrote in Not an Amazon Problem (and please go read that if you haven’t) I don’t see myself as an enemy of Amazon, particularly. I think the pressures of 21st-century capitalism have put every large company into a place where they really can’t afford to be ethical or the financial sector will rip them to shreds then replace the CEO with someone who will maximize shareholder return at all costs, without any of that amateurish “ethics” stuff.
To the extent that Amazon is objectionable, it’s a symptom of those circumstances.
I’m bailing out of Prime not to hurt Amazon, but because it doesn’t make commercial or emotional sense for me just now.
Commercial?
Yes, free next-day delivery is pretty great. In fact, in connection with our recent move, I’ve been ordering small cheap stuff furiously: (USB cables, light switches, closet organizers, a mailbox, a TV mount, WiFi hubs, banana plugs, you name it).
But the moving operations are mostly done, and there are few (any?) things we really need the next day, and we’re fortunate, living in the center of a 15-minute city. So getting my elderly ass out of my chair and going to a store is a good option, for more than one reason.
Second, for a lot of things you want to order, the manufacturer has its own online store these days and a lot of them are actually well-built, perfectly pleasant to use.
Third, Amazon’s prices aren’t notably cheaper than the alternatives.
Emotional?
Amazon is an US corporation and the US is now hostile to Canada, repeatedly threatening to annex us. So I’m routing my shopping dollars away from there generally and to Canadian suppliers specifically. Dumping Prime is an easy way to help that along.
Second, shopping on Amazon for the kinds of small cheap things listed above is more than a little unpleasant. The search-results page is a battle of tooth and claw among low-rent importers. Also it’s just really freaking ugly, hurts my eyes to look at it.

Really? I have no idea what they were.
Finally, one of Prime’s big benefits used to be Prime Video, but no longer. There was just no excuse for greenlighting that execrable Rings of Power show, and I’m not aware of anything else I want to watch.
Amazon is good at lots of things, but has never been known for good taste. I mean, look at that search-results page.
Yep.
Is it easy?
Yep, no complaints. There were only two please-don’t-go begs and neither was offensive.
No hard feelings.
Moved 28 Feb 2025, 9:00 pm
It is traditional in this season in this space to tickle your eyes with pictures of our early spring crocuses, while gently dunking a bit on our fellow Canadians who, away from the bottom left corner of the country, are still snowbound. So, here you go. Only not really.

Yes, those are this spring’s crocuses. But they’re not our crocuses, they’re someone else’s. We don’t have any. Because we moved.
It’s a blog isn’t it? I’ve written up childbirths and pet news and vacations and all that stuff. So why not this?
What happened was, we bought a house in 1996 and then, after 27 years and raising two kids and more cats, it was, well, not actually dingy, but definitely tired. The floors. The paint. The carpet. The cupboards. So we started down two paths at once, planning for a major renovation on one side, and shopping for a new place on the other. Eighteen months later we hadn’t found anything to buy, and the reno was all planned and permitted and we were looking for rentals to camp out in.
Then, 72 hours from when we were scheduled to sign the reno contract, this place came on the market across our back alley and three houses over. The price was OK and it didn’t need much work and, well, now we live there.
I’m sweeping a lot of drama under the rug. Banking drama and real-estate drama and insurance drama and floor-finishing drama and Internet-setup drama and A/V drama and storage drama. And of course moving drama. Month after month now, Lauren and I have ended more days than not exhausted.
But here we are. And we’re not entirely without our plants.

This is Jason of Cycle Driven Gardening,who lent his expertise to moving our favorite rosebushes, whose history goes back decades. Of course, there could be no guarantee that those old friends would survive the process.
Today was unseasonably warm and our new back patio is south-facing, so we soaked up the sun and cleared it of leftover moving rubble. Then ventured into the back yard, much-ignored over winter.
Each and every rosebush has buds peeking out. So it looks, Dear Reader, like I’ll be able to inflict still more blossom pictures on you, come spring.
And we’ll be putting in crocuses, but those photos will have to wait twelve months or so.
See, even in 2025, there are stories with happy endings.
Safari Cleanup 26 Feb 2025, 9:00 pm
Like most Web-heads I spent years living in Chrome, but now feel less comfy there, because Google. I use many browsers but now my daily driver is Safari. I’m pretty happy with it but there’s ugly stuff hiding in its corners that needs to be cleaned up. This fragment’s mostly about those corners, but I include notes on the bigger browser picture and a couple of ProTips.
Many browsers?
If your life is complicated at all you need to use more than one. By way of illustration not recommendation, here’s what I do:
Safari is where I spend most of my time. As I write this I have 36 tabs, eight of them pinned. That the pinned number is eight is no accident, it’s because of the Tab Trick, which if you don’t know about, you really need to learn.
More on Safari later.
I use Chrome for business. It’s where I do banking and time-tracking and invoicing. (Much of this relies on Paymo, which is great. It takes seconds to track my time, and like ten minutes to do a super-professional monthly invoice.)
I use Firefox when I need to be @coop@cosocial.ca or go anywhere while certain that no Google accounts are logged in.
I use Chrome Canary for an organization I work with that has Chrome-dependent stuff that I don’t want to mix up with any of my personal business.
Safari, you say?
We inhabit the epoch of Late Capitalism. Which means there’s no reason for me to expect any company to exhibit ethical behavior. Because ethics is for amateurs.
So when I go looking for infrastructure that offers privacy protection, I look for a provider whose business model depends at least in part on it. That leaves Safari.
Yeah, I know about Cook kissing Trump’s ring, and detest companies who route billions of nominal profits internationally to dodge taxes, and am revolted at the App Store’s merciless rent-extraction from app developers who make Apple products better.
But still, I think their privacy story is pretty good, and it makes me happy when their marketing emphasizes it. Because if privacy is on their path to profit, I don’t have to mis-place my faith in any large 21st-century corporation’s “ethical values”.
Also, Safari is technically competent. It’s fast enough, and (unlike even a very few years ago) compatible with wherever I go. The number of Chome-only sites, thank goodness, seems to be declining rapidly.
So, a tip o’ the hat to the Safari team, they’re mostly giving me what I need. But there are irritants.
Tab fragility
This is my biggest gripe. Every so often, Safari just loses all my tabs when… well, I can’t spot a pattern. Sometimes it’s when I accidentally ⌘-Q it, sometimes it’s when I have two windows open for some reason and ⌘-W something. I think. Maybe. Sometimes they’re just gone.
Yes, I know about the “Reopen all windows from last session” operation. If it solved the problem I wouldn’t be writing this.
This is insanely annoying, and a few years back, more than once it seriously damaged my progress in multiple projects. Fortunately, I discovered that the Bookmarks menu has a one-click thing to create bookmarks for all my open tabs. So I hit that now and again and it’s saved me from tab-loss damage a couple of times now.
Someone out there might be thinking of suggesting that I not use browser tabs to store my current professional status. Please don’t, that would be rude.
Pin fragility
Even weirder, sometimes when I notice I’ve lost my main window and use the History menu to try to bring it back, I get a new window with all my tabs except for the pinned ones. Please, Safari.
Kill-pinned-tab theater
Safari won’t let me ⌘-W a pinned tab. This is good, correct where Chrome is wrong.
But when I try, does it quietly ignore me, or emit a gentle beep? No, it abruptly shifts to the first un-pinned tab. Which makes me think that I indeed killed the tab I was on, then I realize that no I didn’t, then I panic because obviously I killed something, and go looking for it. I try Shift-⌘-T to bring back most recently closed tab, realize I killed that an hour ago, and sit there blank-faced and worried.
New window huh?
When I’m in Discord or my Mail client or somewhere and I click on a link, sometimes it puts up a new Safari window. Huh? But usually not, I can’t spot the pattern. When I kill the new window, sometimes I lose all my tabs. Sigh.
Passive-aggressive refresh
When I have some tab that’s been around and unvisited for a while, sometimes there’s this tasteful decoration across the top.

I think that this used to say “significant memory” rather than “significant energy”? But really, Safari, try to imagine how little I care about your memory/energy problems, just do what you need to and keep it to yourself. And if you can’t, at least spruce up the typography and copy-editing.
Better back button
[This is partly a MacOS rather than Safari issue.] On my Android, I can click on something in Discord that takes me to the GitHub app, another click and I’m in the browser, then click on something there and be in the YouTube app, and so on and so on. And then I can use “Back” to retrace my steps from app to app. This is just incredibly convenient.
Safari’s memory of “how did I get here” apparently lives in the same evanescent place my tab configuration does, and usually vanishes the instant I step outside the browser. Why shouldn’t the Back operation always at least try to do something useful?
Hey Apple, it’s your operating system and your browser, why not catch up with Android in an area where you’re clearly behind?
I humbly suggest
… that Safari do these things:
Save my current-tabs setup every few seconds on something more robust than the current fabric of spider webs and thistledown. Offer a “Restore Tabs” entry in the History menu that always works.
Don’t just exit on ⌘-Q. Chrome gets this right, offering an option where I have to hold that key combo down for a second or two.
When I try to kill a pinned tab, just ignore me or beep or put up a little message or something.
Never create a new Safari window unless I ask for it.
Kill the dumb “this webpage was refreshed…”
Offer a “back” affordance that always works, even across applications.
Other browsers?
I already use Firefox every day and I know about Opera, Vivaldi, Brave, Arc, etc., and I’ve tried them, and none ever stuck. Or the experience was feeling good when something emerged about the provider that was scammy or scary or just dumb. (And the recent rumblings out of Mozilla are not reassuring.)
While it’d sure be nice for there to be a world-class unencumbered open-source browser from an organization I respect, I’m not holding my breath. So it’s Safari for me for now.
And it seems to me that the things that bother me should be easy to fix. Please do.
Posting and Fascism 8 Feb 2025, 9:00 pm
Recently, Janus Rose’s You Can’t Post Your Way Out of Fascism crossed my radar on a hundred channels. It’s a smart piece that says smart things. But I ended up mostly disagreeing. I’m not saying you can post your way out of Fascism, but I do think it’s gonna be hard to build the opposition without a lot of posting. The what and especially the where matter. But the “posting is useless” stance is dangerously reductive.
Before I get into my gripes with Ms Rose’s piece, let me highlight the good part: Use your browser’s search-in-page to scroll forward to “defend migrants”. Here begins a really smart and inspirational narrative of things people are doing to deflect and defeat the enemy.
But it ends with the observation that all the useful progressive action “arose from existing networks of neighbors and community organizers”. Here’s where I part ways. Sure, local action is the most accessible and in most cases the only action, but right now Fascism is a global problem and these fighters here need to network with those there, for values of “here” and “there” that are not local.
Which is gonna involve a certain amount of posting: Analyses, critiques, calls to action, date-setting, message-sharpening; it’s just not sensible to rely on networks of neighbors to accomplish this.
What to post about?
Message sharpening feels like the top of the list. Last month I posted In The Minority, making the (obvious I think) point that current progressive messaging isn’t working very well; we keep losing elections! What needs to be changed? I don’t know and I don’t believe anybody who says they do.
It’s not as simple as “be more progressive” or conversely “be more centrist”. I personally think the way to arrive at the right messaging strategies and wording is going to involve a lot of trial balloons and yes, local efforts. Since I unironically think that progressive policies will produce results that a majority of people will like, I also believe that there absolutely must be a way of explaining why and how that will move the needle and lead to victories.
Where to post it?
Short answer: Everywhere, almost.
Granted that TV, whatever that means these days, is useless. Anyone doing mass broadcasting is terrified of controversy and can’t afford to be seen as a progressive nexus.
And Ms Rose is 100% right that Tiktok, Xitter, Facebook, Insta, or really any other centralized profit-driven corporate “social network” products are just not useful for progressives. These are all ad-supported, and (at this historical moment) under heavy pressure from governments controlled by our enemies, and in some cases, themselves owned and operated by Fascists.
That leaves decentralized social media (the Fediverse and (for the moment) Bluesky), Net-native operations like 404/Vice/Axios/Verge (even though most of them are struggling), and mainstream “quality publications”: The Atlantic, the Guardian, and your local progressive press (nearest to me here in Canada, The Tyee).
Don’t forget blogs. They can still move the needle.
And, I guess, as Ms Rose says, highly focused local conversations on Discord, WhatsApp, and Signal. (Are there other tech options for this kind of thing?)
Are you angry?
I am. And here I part paths with Ms Rose, who is vehement that we should see online anger as an anti-pattern. Me, I’m kinda with Joe Strummer, anger can be power. Rose writes “researchers have found that the viral outrage disseminated on social media in response to these ridiculous claims actually reduces the effectiveness of collective action”. I followed that link and found the evidence unconvincing.
Also, if there’s one thing I believe it’s that in the social-media context, being yourself, exposing the person behind the words, is central to getting anywhere. And if the enemy’s actions are filling me with anger, it would be disingenuous and ineffective to edit that out of my public conversation.
Posting is a progressive tool
Not gonna say more about principles or theory, just offer samples.
50501 has done it all with hashtags and micro-posts. Let’s see how it works.
Here’s Semafor arguing that the Democrats’ litigation-centric resistance is working pretty well.
Heidi Li Feldman, in Fear and loathing plus what blue states should be doing now argues on her blog for resistance at the state-government level, disengaging from and pushing back against toxic Musk/Trump projects.
Here’s Josh Marshall at Talking Points Memo calling for pure oppositionism and then arguing that Democrats should go to the mattresses on keeping the government open and raising the debt limit.
Here’s the let’s-both-sides-Fascism New York Times absolutely savaging the GOP campaign to keep Mayor Adams in place as a MAGA puppet.
Here’s yours truly posting about who progressives should talk to.
Here’s Mark Cuban on Bluesky saying hardass political podcasts are the only way to reach young men.
Here’s Elizabeth Kolbert in The New Yorker making very specific suggestions as to the tone and content of progressive messaging.
Here’s Cory Doctorow on many channels as usual, on how Canada should push back against the Trump tariffs.
There’s lots more strong stuff out there. Who’s right?
I don’t know. Not convinced anyone does.
Let’s keep posting about it till we get it right.
Photo Philosophizing 4 Feb 2025, 9:00 pm
What happened was, I went to Saskatchewan to keep my mother company, and got a little obsessed about photo composition and complexity. Which in these troubled times is a relief.
This got started just after take-off from Vancouver. As the plane climbed over the city I thought “That’s a nice angle” and pointed the Pixel through the plexiglass.

You might want to enlarge this one.
A couple of days into my Prairie visit I got around to processing the photos and thought that Vancouver aerial had come out well. No credit to the photographer here, got lucky on the opportunity, but holy crap modern mobile-device camera tech is getting good these days. I’ll take a little credit for the Lightrooming; this has had heavy dehazing and other prettifications applied.
A couple of days later I woke up and the thermometer said -36°C (in Fahrenheit that’s “too freaking cold”). The air was still and the hazy sunlight was weird. “There has to be a good photo in this somewhere, maybe to contrast that Vancouver shot” I thought. So I tucked the Fujifilm inside my parka (it claims to be only rated to -10°) and went for a walk. Mom politely declined my invitation to come along without, to her credit, getting that “Is he crazy?” expression on her face.
Her neighborhood isn’t that photogenic but there’s a Pitch-n-putt golf course a block away so I trudged through that. The snow made freaky squeaking sounds underfoot. At that temperature, it feels like you have to push the air aside with each step. Also, you realize that your lungs did not evolve to process that particular atmospheric condition.
Twenty minutes in I had seen nothing that made me want to pull out the camera, and was thinking it was about time to head home. So I stopped in a place where there was a bit of shape and shadow, and decided that if I had to force a photo opportunity to occur by pure force of will, so be it.

It ain’t a great city framed by coastal mountains. But it ain’t nothing either. I had to take my gloves off to shoot, and after just a couple of minutes of twisting around looking for angles, my fingers were screaming at me.
The two pictures are at the opposite end of the density-vs-minimalism spectrum but they share, um, snow, so that’s something.
Anyhow, here’s the real reason I was there.

Jean Bray, who’ll be turning 95 this year.
I find photography to be a very useful distraction from what’s happening to the world.
In The Minority 22 Jan 2025, 9:00 pm
That’s us. I assume you’re among those horrified at the direction of politics and culture in recent years and especially recent weeks, in the world at large and especially in America. We are a minority. We shouldn’t try to deny it, we should be adults and figure out how to deal with it.
Denialists
I’m out of patience with people who put the blame on the pollsters or the media or Big Tech, or really any third party. People generally heard what Mr Trump was offering — portrayed pretty accurately I thought — and enough of them liked it to elect him. Those who didn’t are in a minority. Quit dodging and deal.
Clearly, we the minority have failed in explaining our views. Many years ago I wrote an essay called Two Laws of Explanation. One law says that if you’re explaining something and the person you’re explaining to doesn’t get it, that’s not their problem, it’s your problem. I still believe this, absolutely.
So let’s try to figure out better explanations.
But first, a side trip into economic perception and reality.
Economists
A strong faction of progressives and macroeconomists are baffled by people being disaffected when the economy, they say, is great. Paul Krugman beats this drum all the time. Unemployment and inflation are low! Everything’s peachy! Subtext: If the population disagrees, they are fools.
I call bullshit. The evidence of homelessness is in my face wherever I go, even if there are Lamborghinis cruising past the sidewalk tents. Food banks are growing. I give a chunk of money every year to Adopt a School, which puts free cafeterias in Vancouver schools where kids are coming to school hungry. Kingston, a mid-sized mid-Canadian city, just declared an emergency because one household in three is suffering from food insecurity.
Even among those who are making it, for many it’s just barely:
… half of Canadians (50%, +8) are now $200 or less away each month from not being able to pay their bills and debt payments. This is a result of significantly more Canadians saying they are already insolvent (35%, +9) compared to last quarter. Canadians who disproportionately report being $200 or less away from insolvency continue to be women (55%, +4) but the proportion of men at risk has increased to 44%, up 13 points from last quarter.
Source: MNP Consumer Debt Index. The numbers like “+8” give the change since last quarter.
(Yes, this data is Canadian, because I am. But I can’t imagine that America is statistically any better.)
Majorities
Minorities need to study majorities closely. So let me sort them, the ones who gave Trump the election I mean, into baskets:
Stone racists who hate immigrants, especially brown ones.
Culture warriors who hate gays and trans people and so on.
Class warriors; the conventional billionaire-led Republican faction who are rich, voting for anyone they think offers lower taxes and less regulation.
People who don’t pay much attention to the news but remember that gas was cheaper when Trump was in office.
Oh wait, I forgot one: People who heard Trump say what boiled down to “The people who are running things don’t care about you and are corrupt!” This worked pretty well because far too many don’t and are. A whole lot of the people who heard this are financially stressed (see above).
Who to talk to?
Frankly, I wouldn’t bother trying to reach out to either of the first two groups. Empirically, some people are garbage. You can argue that it’s not their fault; maybe they had a shitty upbringing or just fell into the wrong fellowships. Maybe. But you can be sure that that’s not your fault. The best practice is some combination of ignoring them and defending against their attacks, politics vs politics and force versus force.
I think talking to the 1% is worthwhile. The fascist leaders are rich, but not all of the rich are fascist. Some retain much of their humanity. And presumably some are smart enough to hear an argument that on this economic path lie tumbrils and guillotines.
That leaves the people who mostly ignore the news and the ones who have just had it with the deal they’re getting from late-Capitalist society. I’m pretty sure that’s who we should be talking to, mostly.
What to say?
I’m not going to claim I know. I hear lots of suggestions…
In the New Yorker, Elizabeth Kolbert’s Does One Emotion Rule All Our Ethical Judgments? makes two points. First, fear generally trumps all other emotions. So, try phrasing your arguments in terms of the threats that fascism poses directly to the listener, rather than abstract benefits to be enjoyed by everyone in a progressive world.
Second, she points out the awesome power of anecdote: MAGA made this terrible thing happen to this actual person, identified by name and neighborhood.
On Bluesky, Mark Cuban says we need offensive hardass progressive political podcasts, and offers a sort of horrifying example that might work.
On Bloomberg (paywalled) they say that the ruling class should be terrified of a K-shaped recovery; by inference, progressives should be using that as an attack vector.
Josh Marshall has been arguing for weeks that since the enemies won the election, they have the power and have to own the results. Progressives don’t need to sweat alternative policies, they just have to highlight the downsides of encroaching fascism (there are plenty) and say “What we are for is NOT THAT!” and just keep saying it. Here’s an example.
Maybe one of these lines of attack is right. I think they’re all worth trying. And I’m pretty sure I know one ingredient that’s going to have to be part of any successful line of attack…
Be blunt
Looking back at last year’s Presidential campaign, there’s a thing that strikes me as a huge example of What Not To Do. I’m talking about Harris campaign slogan: “Opportunity Economy”. This is marketing-speak. If there’s one thing we should have learned it’s that the population as a whole — rich, poor, Black, white, queer, straight, any old gender — has learned to see through this kind of happy talk.
Basically, in Modern Capitalism, whenever, and I mean whenever without exception, whenever someone offers you an “opportunity”, they’re trying to take advantage of you. This is appallingly tone-deaf, and apparently nobody inside that campaign asked themselves the simple question “Would I actually use this language in talking to someone I care about?” Because they wouldn’t.
Be blunt. Call theft theft. Call lies lies. Call violence violence. Call ignorance ignorance. Call stupidity stupidity.
Also, talk about money a lot. Because billionaires are unpopular.
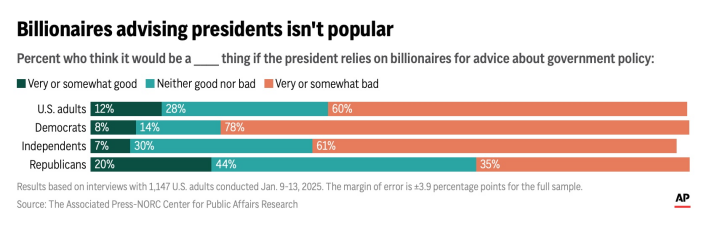
From a good AP poll.
Don’t say anything you wouldn’t say straight-up in straight-up conversation with a real person. Don’t let any marketing or PR professionals edit the messaging. This is the kind of messaging that social media is made for.
Maybe I’m oversimplifying, but I don’t think so.
Protocol Churn 14 Jan 2025, 9:00 pm
Bluesky and the Fediverse are our best online hopes for humane human conversation. Things happened on 2025/01/13; I’ll hand the microphone to Anil Dash, whose post starts “This is a monumental day for the future of the social web.”

What happened? Follow Anil’s links: Mastodon and Bluesky (under the “Free Our Feeds” banner). Not in his sound-bite: Both groups are seeking donations, raising funds to meet those goals.

I’m sympathetic to both these efforts, but not equally. I’m also cynical, mostly about the numbers: They’ve each announced a fundraising target, and both the targets are substantial, and I’m not going to share either, because they’re just numbers pulled out of the air, written on whiteboards, designed to sound impressive.
What is true
These initiatives, just by existing, are evidence in letters of fire 500 miles high, evidence of people noticing something important: Corporately-owned town squares are irreversibly discredited. They haven’t worked in the past, they don’t work now, and they’ll never work.
Something decentralized is the only way forward. Something not owned by anyone, defined by freely-available protocols. Something like email. Or like the Fediverse, which runs on the ActivityPub protocol. Or, maybe Bluesky, where by “Bluesky” I mean independent service providers federated via the AT Protocol, “ATProto” for short.
What is hard?
I’ll tell you what’s hard: Raising money for a good cause, when that good cause is full of abstractions about openness and the town square and so on. Which implies you’re not intending that the people providing the money will make money. So let’s wish both these efforts good luck. They’ll need it.
What matters
Previously in Why Not Bluesky I argued that, when thinking about the future of conversational media, what matters isn’t the technology, or even so much the culture, but the money: Who pays for the service? On that basis, I’m happy about both these initiatives.
But now I’m going to change course and talk about technology a bit. At the moment, the ATProto implementation that drives Bluesky is the only one in the world. If the company operating it failed in execution or ran out of money, the service would shut down.
So, in practice, Bluesky’s not really decentralized at all. Thus, I’m glad that the “Free Our Feeds” effort is going to focus on funding an alternative ATProto implementation. In particular, they’re talking about offering an alternative ATProto “Relay”.
Before I go on, you’re going to need a basic understanding of what ATProto is and how its parts work. Fortunately, as usual, Wikipedia has a terse, accurate introduction. If you haven’t looked into ATProto yet, please hop over there and remedy that. I’ll wait.
Now that you know the basics, you can understand why Free Our Feeds is focusing on the Relay. Because, assuming that Bluesky keeps growing, this is going to be a big, challenging piece of software to build, maintain, and operate, and the performance of the whole service depends on it.
The Fediverse in general and Mastodon in particular generally don’t rely on a global firehose feed that knows everything that happens, like an eye in the sky. In fact, the ActivityPub protocol assumes a large number of full-stack peer implementations that chatter with each other, in stark contrast to ATProto’s menagerie of Repos and PDSes and Relays and App Views and Lexicons.
The ATProto approach has advantages; since the Relay knows everything, you can be confident of seeing everything relevant. The Fediverse makes no such promise, and it’s well-known that in certain circumstances you can miss replies to your posts. And perhaps more important, miss replies to others’ posts, which opens the door to invisible attackers.
And this makes me nervous. Because why would anyone make the large engineering and financial investments that’d be required to build and operate an ATProto Relay?
ActivityPub servers may have their flaws, but in practice they are pretty cheap to operate. And it’s easy to think of lots of reasons why lots of organizations might want to run them:
A university, to provide a conversational platform for its students…
… or its faculty.
A Developer Relations team, to talk to geeks.
Organized religion, for evangelism, scholarship, and ministry.
Marketing and PR teams, to get the message out.
Government departments that provide services to the public.
Or consider my own instance, CoSocial, the creation of Canadians who (a) are fans of the co-operative movement, (b) concerned about Canadians’ data staying in Canada, and (c) want to explore modes of funding conversational media that aren’t advertising or Patreon.
Maybe, having built and run a Relay, the Free Our Feeds people will discover a rationale for why anyone else should do this.
So, anyhow…
I hope both efforts hit their fundraising targets. I hope both succeed at what they say they’re going to try.
But for my own conversation with the world, I’m sticking with the Fediverse.
Most of all, I’m happy that so many people, whatever they think of capitalism, have realized that it’s an unsuitable foundation for online human conversation. And most of all I hope that that number keeps growing.
AI Noise Reduction 10 Jan 2025, 9:00 pm
What happened was, there was a pretty moon in the sky, so I got out a tripod and the big honkin’ Tamron 150-500 and fired away. Here’s the shot I wanted to keep.

Sadly, the clouds had shifted
and Luna had lost her pretty bronze shading.
I thought the camera and lens did OK given that I was shooting from sea level through soggy Pacific-Northwest winter air. But when I zoomed in there was what looked like pretty heavy static. So I applied Lightroom to the problem, twice.


I’ll be surprised if many of you can see a significant difference. (Go ahead and enlarge.) But you would if it were printed on a big piece of paper and hung on a wall. So we’ll look at the zoomed-in version. But first…
Noise reduction, old-school
Lightroom has had a Luminance-noise reduction tool for years. Once you wake it up, you can further refine with “Detail” and “Contrast” sliders, whose effects are subtle at best. For the moon shot, I cranked the Luminance slider pretty all the way over and turned up Detail quite a bit too.
Noise reduction, with AI
In recent Lightroom versions there’s a “Denoise…” button. Yes, with an ellipsis and a note that says “Reduce noise with AI.” It’s slow; took 30 seconds or more to get where it was going.
Anyhow, here are the close-up shots.



Original first, then noise-reduced
in Lightroom by hand, then with AI.
What do you think?
I have a not-terribly-strong preference for the by-hand version. I think both noise reductions add value to the photo. I wonder why the AI decided to enhance the very-slight violet cast? You can look at the rim of one crater or another and obsess about things that nobody just admiring the moon will ever see.
It’s probably worth noting that the static in the original version isn’t “Luminance noise”, which is what you get when you’re pushing your sensor too hard to capture an image in low light. When you take pictures of the moon you quickly learn that it’s not a low-light scenario at all, the moon is a light-colored object in direct sunlight. These pix are taken at F7.1 at 1/4000 second shutter. I think the static is just the Earth’s atmosphere getting in the way. So I’m probably abusing Lightroom’s Luminance slider. Oh well.
You could take this as an opportunity to sneer at AI, but that would be dumb. First, Lightroom’s AI-driven “select sky” and “select subject” tools work astonishingly well, most times. Second, Adobe’s been refining that noise-reduction code for decades and the AI isn’t even a year old yet.
We’ll see how it goes.
Bitcoin Lessons 4 Jan 2025, 9:00 pm
Here we are, it’s 2025 and Bitcoin is surging. Around $100K last time I looked. While its creation spews megatons of carbon into our atmosphere, investors line up to buy it in respectable ETFs, and long-term players like retirement pools and university endowments are looking to get in. Many of us are finding this extremely annoying. But I look at Bitcoin and I think what I’m seeing is Modern Capitalism itself, writ large and in brutally sharp focus.
[Disclosure: In 2017 I made a lot of money selling Bitcoins at around $20K, ones I’d bought in 2013. Then in 2021 I lost money shorting Bitcoin (but I’m still ahead on this regrettable game).]
What is a Bitcoin?
It is verifiable proof that a large amount of computing has been done. Let’s measure it in carbon, and while it’s complicated and I’ve seen a range of answers, they’re all over 100 tonnes of CO2/Btc. That proof is all that a Bitcoin is.

Bitcoin is also a store of value. It doesn’t matter whether you think it should be, empirically it is, because lots of people are exchanging lots of money for Bitcoins on the assumption that they will store the value of that money. Is it a good store of value? Many of us think not, but who cares what we think?
Is Bitcoin useful?
I mean, sure, there are currency applications in gun-running, ransoms, narcotics, and sanctions-dodging. But nope, the blockchain is so expensive and slow that all most people can really do with Bitcoin is refresh their wallets hoping to see number go up.
Bitcoin and late capitalism
The success of Bitcoin teaches the following about capitalism in the 2020s:
Capitalism doesn’t care about aesthetics. Bitcoins in and of themselves in no way offer any pleasure to any human.
Capitalism doesn’t care about negative externalities generally, nor about the future of the planet in particular. As long as the number goes up, the CO2 tonnage is simply invisible. Even as LA burns.
Capitalism can be oblivious to the sunk-cost fallacy as long as people are making money right now.
Capitalism doesn’t care about utility; the fact that you can’t actually use Bitcoins for anything is apparently irrelevant.
And oblivious about crime too. The fact that most actual use of Bitcoins as a currency carries the stench of international crime doesn’t seem to bother anyone.
Capitalism doesn’t care about resiliency or sustainability. Bitcoins are fragile; very easy to lose forever by forgetting a password or failing to back up data just right. Also, on the evidence, easy to steal.
Capitalism can get along with obviously crazy behavior, for example what MicroStrategy is doing: Turning a third-rate software company into a bag of Bitcoins and having an equity valuation that is higher than the value of the bag; see Matt Levine (you have to scroll down a bit, look for “MicroStrategy”).
Capitalism says: “Only money is real. Those other considerations are for amateurs. Also, fuck the future.”
Do I hate capitalism?
Not entirely. As Paul Krugman points out, a market-based economy can in practice deliver reasonably good results for a reasonably high proportion of the population, as America’s did in the decades following 1945. Was that a one-time historical aberration? Maybe.
But as for what capitalism has become in the 21st century? Everything got financialized and Bitcoin isn’t the disease, it’s just a highly visible symptom. Other symptoms: The explosion of homelessness, the destruction of my children’s ecosystem, the gig economy, and the pervasiveness of wage theft. It’s really hard to find a single kind word to say.
Are Bitcoins dangerous?
Not existentially. I mean, smart people are worried, for example Rostin Behnam, chair of the Commodity Futures Trading Commission: “You still have a large swath of the digital asset space unregulated in the US regulatory system and it’s important — given the adoption we’ve seen by some traditional financial institutions, the huge demand for these products by both the retail and institutional investors — that we fill this gap.”
All that granted, the market cap of Bitcoin is around two trillion US dollars as I write this. Yes, that’s a lot of money. But most of them are held by market insiders, so even in the (plausible) case that it plunges close to zero, the damage to the mainstream economy shouldn’t be excessive.
It’s just immensely annoying.
Bitcoin and gold
One of the things Bitcoin teaches us is that there is too much money in the world, more than can be put to work in sensible investments. So the people who have it do things like buy Bitcoins.
Gold is also a store of value, also mostly just because people believe it is. But it has the virtues of beauty and of applications in jewellery and electronics. I dunno, I’m seriously thinking about buying some on the grounds that the people who have too much money are going to keep investing in it. In particular if Bitcoin implodes.
Having fun staying poor
I’ve been snarling at cryptocurrencies since 2018 or so. But, number go up. So I’ll close by linking to HODLers apology.
Question
Is this the best socio-economic system we as a species can build?
December 24th Lasagna 2 Jan 2025, 9:00 pm
We had thirteen people at my Mom’s house this last Christmas. One of our traditions is a heroic Lasagna for Christmas Eve, a specialty of a family member. This year we asked them for the recipe and they agreed, but would rather remain uncredited. It’s called “Very Rich Red Sauce and four-Cheese Lasagna”.
I sort of enjoy cooking but would never have the courage to take on a project like this. I can testify that the results are wonderful.
Sauce
Key sauce ingredients are red wine & sun-dried tomatoes; lasagna is all about mozza, the provolone adds a certain extra something. Over to the chef:
Ingredients
Sauce:
butter - half a lb block or less
olive oil to sauté
carrots - 2 to 4 depending on size, make sure they are fresh!
celery - 5-6 spears, say ⅔ of a bunch
onions (ideally yellow, but whatevs) - 3-6 depending on size.
(by volume, you are looking to get roughly 3:2:1 proportions when chopped of onions:celery:carrots)
a red sweet pepper
extra lean hamburger - 1 kg
3 cloves
salt - half a tablespoon? more? (tomato sauces tend to need a little more salt than other applications)
black pepper - if not using cayenne, a LOT, perhaps a tablespoon of freshly ground
cayenne - if using, to taste, I find strength is highly variable so hard to say how much, perhaps a couple of teaspoons?
Two big cans of diced tomatoes (NOT AYLMER! yuck, Unico is acceptable, Italian imported best)
3 small cans or one big can of tomato paste (or tubes, if you get them from an Italian grocery store, which are a rather superior product) It is hard to use too much tomato paste
(pro tip for cans of tomato paste: use the can opener to open BOTH the top and bottom of the can, then the paste slides out neatly and you don’t have to fool around trying to spatula the paste out of the can!)
about a half bottle of cheap red wine (the grocery store sells cheap cooking wine in demi bottles, though red can be hard to find, one demi bottle is more than enough)
most of a garlic bulb, say three quarters, once again FINELY chopped (no not pressed or processed!)
a LOT of dried oregano, say 3-4 tablespoons plus
a fair amount of dried basil, say 2 tablespoons plus
some died thyme, say a half tablespoon plus
(herbs are tough to give measurements for, as they vary enormously in potency with brand, age & storage)
about a tablespoon of powdered beef stock
about 1½ to 2 cups of finely chopped sun-dried tomatoes NO SUBSTITUTIONS!!!!!
Lasagna
1 disposable foil pan
foil to cover
butter to grease pan
melted butter to cover top lightly
1¼ margarine tins of sauce above
1½ boxes of lasagna noodles (NOT the “instant” or pre-cooked kind)
salted water to boil noodles
1 big block of mozzarella cheese, coarsely grated
2 packages (12-16 slices) of provolone cheese
1 tin of ricotta cheese
grated parmesan cheese
little bit of freshly ground black pepper
Procedure: Sauce
For the mirepoix, the vegetables all need to be FINELY chopped up for sauce consistency. And I mean FINELY chopped-- I have tried both powered and manual food processors, and they do not do a good job, either reducing things to mush, or leaving big chunks-- the idea here is to get everything about the same size (and the garlic later), it gives the sauce some consistency.
This is tedious and takes a long time.
To give you an idea, a celery spear can be cut into 5-7 strips longwise with the grain, and then the strips chopped as finely as possible across the grain. A big carrot can yield say 6 long flat pieces that can be cut longways into strips, and then the strips cuts finely against the grain to produce little cubes.
The mirepoix is important, we need to get the natural sugars to balance out the acidity of the tomatoes and wine. I cook the onions separately from the rest…
Caramelize the onions. Frankly, this is a pain in the ass. There are no shortcuts; the internet has all these handy tips like using a pressure cooker at first or a slow cooker or adding baking soda or water or whatnot, I’ve tried them, and just no. So a big non-stick frying pan, and sloooow saute with a little butter and salt, frequent stirring, a lot of patience, at LEAST 40 minutes. Maybe an hour. And constant attention, the bastards will burn on you at the drop of a hat. There is no hiding it, this is tricky and somewhat difficult. But worth it, caramelized onions are magic.
Meanwhile, in as big a heavy bottom pot as you can find, saute the celery and carrots (and peppers if you are using them) with say 3 dried cloves, in a little butter, you want to shrink them down and bring out the carrots’ natural sugars, and soften the cloves & bring out their flavour, this takes a while, say 20 minutes or more?
Remove the onions and carrots and celery to a BIG bowl, clean out the big heavy bottom pot and brown the hamburger, about 1kg. DO NOT USE “regular” as it is mostly fat; lately I have been using the “extra lean” because even the lean is quite fatty these days. A little olive oil in the pot, a fair amount of salt (half tablespoon?) & a lot of freshly ground black pepper (approaching a tablespoon?) on the meat and lots of stirring.
This where a lot of people screw up, essentially they “grey” the meat, they don’t BROWN it, ie achieve the Maillard reaction-- as with the mirepoix, we are trying to bring out natural sugars. A lot of stirring/scraping, to break the hamburger up into as small pieces as possible, ie the same size as the veggies in the mirepoix.
While this is happening, add the rest of the ingredients to the mirepoix in the big bowl: tomatoes, tomato paste (more is better), wine.
Also the chopped garlic, oregano, basil, thyme, about a tablespoon of powdered beef stock (yes this is cheating, shhh).
A word about sun-dried tomatoes: they are absolutely wonderful things, but hard to find. Ideally, you want the dried kind, not the “in oil” kind, but you may have to settle for that. There are two different kinds of “in oil”, the ones in jars floating in oil like pickles in brine (they are prepped for salads, not sauces, so they are floating oil, and disintegrate once they are in a sauce), which you really do not want, and the ones in packages that have been oiled for preservation. This is usually what you have to settle for. The best ones are dry and quite hard.They are hard to find.
Of these, the worst sun-dried tomatoes are the North American product, the big food companies noted there was a demand for them, and started tossing field tomatoes into drying kilns. These are quite inferior, but useable if it’s all you can find. The best ones are Turkish, followed by Italian, you can usually find in Italian delicatessens or grocery stores (even the Italians agree the Turkish ones are best).
[Tim says: I found them in Vancouver and the chef is right, the flavor is to die for.]
If you get the fully dried/no oil kind, you can simmer them a little in a little water to soften them before you try chopping them up; the water (or some of it anyway) should be added to the sauce…
Drain any fat from the browned meat, add the mix to the meat in the big pot. Stir it all up some more, get it well mixed. You can add a little wine and/or tomato juice if it seems too thick, but be aware that it will liquify a little during cooking. If you are going to use it as a pasta sauce, you want it more liquid, if for lasagna, you want it as thick as practical. In any case, it is very difficult to judge the final thickness at this point.
You can add a little (sun-dried tomato?) water, or tomato juice, or wine, if it needs it, but be cautious.
Put on medium to low heat and stir frequently until it comes to a high simmer/low boil (don’t let it burn!) then turn the heat down to minimum, and slow-cook for at least 4 hours, stirring every 20 minutes or so. Cooking it longer is a Good Thing, I often cook it for 7 or more hours.
LEAVE it out overnight! (this is important!)
Warm it up the next day, bringing it back to a high simmer/low boil and stirring a lot, serve it on pasta. Or make lasagna. Or freeze it. One margarine tin makes a meal with leftovers (each serving would be small, because the stuff is quite strong). One margarine tin (plus a little, ideally) makes for one lasagna. You should get about 3 or so margarine tins from the above. It freezes just fine.
Whew.
Lasagna
In theory, one box of lasagna noodles is just enough to make one pan of lasagna. However, there are almost always a lot of broken pieces of lasagna in a box, and pieces that break or get stuck or something during cooking. I allow for 1 and half a box per lasagna pan.
Ingredients:
enough lasagna noodles, cooked al dente in salted boiling water
1¼ margarine tins of sauce, gently heated up
Butter (better than margarine but you can use that if necessary)
1 big block of mozzarella (the regular supermarket kind is fine, I tried the expensive high quality italian stuff, and it was a LITTLE bit better, but not enough to justify the cost)
1 tin of ricotta cheese, or failing that, dry curd cottage cheese
12-16 slices of provolone cheese (usually 2 packages)
parmesan cheese (like with the mozza, I find the cheap Kraft product fully acceptable for this purpose)
freshly ground black pepper
foil lasagna pan
heavy duty foil
Grease the pan with butter. do a thorough job, you don’t want huge amounts of butter, but you do not want any bit of foil that might come in contact with lasagna ungreased.
Coarsely grate the mozzarella.
Lay an overlapping layer of lasagna noodles crossways in the pan, with the sides going up the sides of the pan. The pieces at either end need to overlap the piece on the bottom, but bend up to cover the short end of the pan as well. This is a pain in the ass to get right.
The sauce goes a long way, you do NOT want a thick layer. Spread a thin layer over the bottom of the pan, about a third of the sauce. Put a layer of mozza on top, about a third of it. Put half the provolone on top. Put a layer of lasagna noodles down long-ways , overlapping a bit.
Spread a thin layer of sauce, another third, covered with mozza, another third, and cover that with the ricotta (or dry-curd cottage). Put down another layer of lasagna long-ways.
The rest of the sauce, the rest of the mozza, and the rest of the provolone.
Cover the cross-wise lasagna noodles, overlapping, and trying to tuck the ends in to seal the package. This is tricky at the ends, I find putting a small cut in the lasagna noodle at the corner makes it easier to fold over neatly. (Usually I am tired by this point and less inclined to be finicky and careful, which is a pity.)
Pour a little melted butter over the top, enough to grease the surface. Sprinkle some freshly ground pepper and a fair amount of parmesan over the top. Cover with foil. Put in fridge (you can pre-make hours before use if you are having a party or something) or immediately put in pre-heated oven.
Preheat oven to pretty hot, 375-400. Cook lasagna for 45 minutes to an hour. Remove foil from pan 10-15 minutes before you remove it from the oven. Put the foil back on and let it stand for AT LEAST 15 minutes, better if you can hold off for half an hour (the hotter it is, the more likely it is do disintegrate when being served, you want the melted cheese to start to re-set a little)
Serve with garlic bread and salad and an impertinent red wine. One pan goes a fairly long way, serves 6-8ish? Depends how many hungry teens you have around…
QRS: Dot-matching Redux 29 Dec 2024, 9:00 pm
Recently I posted
Matching “.” in UTF-8, in which I claimed that you could match
the regular-expression “.” in a UTF-8 stream with either four or five states in a byte-driven finite automaton,
depending how
you define the problem. That statement was arguably wrong, and you might need three more states, for a total of eight. But you
can make a case that really, only four should be needed, and another case calling for quite a few more.
Because that phrase “depending how you define the problem” is doing a lot of work.
But first, thanks: Ed Davies, whose blog contributions (1, 2, 3) were getting insufficient attention from me until Daphne Preston-Kendal insisted I look more closely.
To summarize Ed’s argument: There are a bunch of byte combinations that look (and work) like regular UTF-8 but are explicitly ruled out by the Unicode spec, in particular Section 3.9.3 and its Table 3.7.
Moar States!
Ed posted a nice picture of a corrected 8-state automaton that will fail to match any of these forbidden sequences.
(Original SVG here.)
{kind=link}
I looked closely at Ed’s proposal and it made sense, so I implemented it and (more important) wrote a bunch of unit tests exploring the code space, and it indeed seems to accept/reject everything correctly per Unicode 3.9.3.
So, argument over, and I should go forward with the 8-state Davies automaton, right? Why am I feeling nervous and grumpy, then?
Not all Unicode
I’ve already mentioned in this series that your protocols and data structures just gotta support Unicode in the 21st century, but you almost certainly don’t want to support all the Unicode characters, where by “character” I mean, well… if you care at all about this stuff, please go read Unicode Character Repertoire Subsets (“Unichars for short), a draft inching its way through the IETF, with luck an RFC some day. And if you really care, dig into RFC 3454: PRECIS Framework: Preparation, Enforcement, and Comparison of Internationalized Strings in Application Protocols. Get a coffee first, PRECIS has multiple walls of text and isn’t simple at all. But it goes to tremendous lengths to address security issues and other best practices.
If you don’t have the strength, take my word for it that the following things are true:
We don’t talk much about abstract characters; instead focus on the numeric “code points” that represent them.
JSON, for historical reasons, accepts all the code points.
There are several types of code points that don’t represent characters: “Surrogates”, “controls”, and “noncharacters”.
There are plenty of code points that are problematic because they can be used by phishers and other attackers to fool their victims because they look like other characters.
There are characters that you shouldn’t use because they represent one or another of the temporary historical hacks used in the process of migrating from previous encoding schemes to Unicode.
The consequence of all this is that there are many subsets of Unicode that you might want to restrict users of your protocols or data structures to:
JSON characters: That is to say, all of them, including all the bad stuff.
Unichars “Scalars”: Everything except the surrogates.
Unichars “XML characters”: Lots but not all of the problematic code points excluded.
Unichars “Unicode Assignables”: “All code points that are currently assigned, excluding legacy control codes, or that might in future be assigned.”
PRECIS “IdentifierClass”: “Strings that can be used to refer to, include, or communicate protocol strings like usernames, filenames, data feed identifiers, and chatroom name.”
PRECIS “FreeformClass”: “Strings that can be used in a free-form way, e.g., as a password in an authentication exchange or a nickname in a chatroom.”
Some variation where you don’t accept any unassigned code points; risky, because that changes with every Unicode release.
(I acknowledge that I am unreasonably fond of numbered lists, which is probably an admission that I should try harder to compose smoothly-flowing linear arguments that don’t need numbers.)
You’ll notice that I didn’t provide links for any of those entries. That’s because you really shouldn’t pick one without reading the underlying document describing why it exists.
What should you accept?
I dunno. None of the above are crazy. I’m kind of fond of Unicode Assignables, which I co-invented. The only thing I’m sure of is that you should not go with JSON Characters, because of the fact that its rules make the following chthonic horror perfectly legal:
{"example": "\u0000\u0089\uDEAD\uD9BF\uDFFF"}
Unichars describes it:
The value of the “example” field contains the C0 control NUL, the C1 control "CHARACTER TABULATION WITH JUSTIFICATION", an unpaired surrogate, and the noncharacter U+7FFFF encoded per JSON rules as two escaped UTF-16 surrogate code points. It is unlikely to be useful as the value of a text field. That value cannot be serialized into well-formed UTF-8, but the behavior of libraries asked to parse the sample is unpredictable; some will silently parse this and generate an ill-formed UTF-8 string.
No, really.
What is Quamina for?
If you’re wondering what a “Quamina” is, you probably stumbled into this post through some link and, well, there’s a lot of history. Tl;dr: Quamina is a pattern-matching library in Go with an unusual (and fast) performance envelope; it can match thousands of Patterns to millions of JSON blobs per second. For much, much more, peruse the Quamina Diary series on this blog.
Anyhow, all this work in being correctly restrictive as to the shape of the incoming UTF-8 was making me uncomfortable. Quamina is about telling you what byte patterns are in your incoming data, not enforcing rules about what should be there.
And it dawned on me that it might be useful to ask Quamina to look at a few hundred thousand inputs per second and tell you which had ill-formed-data problems. Quamina’s dumb-but-fast byte-driven finite automaton would be happy to do that, and very efficiently too.
Conclusion
So, having literally lain awake at night fretting over this, here’s what I think I’m going to do:
I’ll implement a new Quamina pattern called
ill-formedor some such that will match any field that has busted UTF-8 of the kind we’ve been talking about here. It’d rely on an automaton that is basically the inverse of Davies’ state machine.By default, the meaning of “
.” will be “matches the Davies automaton”; it’ll match well-formed UTF-8 matching all code points except surrogates.I’ll figure out how to parameterize regular-expression matches so you can change the definition of “
.” to match one or more of the smaller subsets like those in the list above from Unichars and PRECIS.
But who knows, maybe I’ll end up changing my mind again. I already have, multiple times. Granted that implementing regular
expressions is hard, you’d think that matching “.” would be the easy part. Ha ha ha.
QRS: Matching “.” in UTF-8 18 Dec 2024, 9:00 pm
Back on December 13th, I
posted a challenge on Mastodon: In a simple UTF-8 byte-driven
finite automaton, how many states does it take to match the regular-expression construct “.”, i.e. “any character”?
Commenter
Anthony Williams responded,
getting it almost right I think,
but I found his description a little hard to understand. In this piece I’m going to dig into what
. actually means, and then how many states you need to match it.
[Update: Lots more on this subject and some of the material below is arguably wrong, but just “arguably”; see
Dot-matching Redux.]
The answer surprised me. Obviously this is of interest only to the faction of people who are interested in automaton wrangling, problematic characters, and the finer points of UTF-8. I expect close attention from all 17 of you!
The answer is…
Four. Or five, depending.
What’s a “Unicode character”?
They’re represented by “code points”, which are numbers in the range 0 … 17×216, which is to say 1,114,112 possible values. It turns out you don’t actually want to match all of them; more on that later.
How many states?
Quamina is a “byte-level automaton” which means it’s in a state, it reads a byte, looks up the value of that byte in a map
yielding either the next state, or nil, which means no match. Repeat until you match or fail.
What bytes are we talking about here? We’re talking about UTF-8 bytes. If you don’t understand UTF-8 the rest of this is going to be difficult. I wrote a short explainer called Characters vs. Bytes twenty-one years ago. I now assume you understand UTF-8 and knew that code points are encoded as sequences of from 1 to 4 bytes.
Let’s count!
When you match a code point successfully you move to the part of the automaton that’s trying to match the next one; let’s call this condition MATCHED.
(From here on, all the numbers are hex, I’ll skip the leading 0x. And all the ranges are inclusive.)
In multi-byte characters, all the UTF-8 bytes but the first have bitmasks like
10XX XXXX, so there are six significant bits, thus 26 or 64 distinct possible values ranging from 80-BF.There’s a Start state. It maps byte values 00-7F (as in ASCII) to MATCHED. That’s our first state, and we’ve handled all the one-byte code points.
In the Start state, the 32 byte values C0-DF, all of which begin
110signaling a two-byte code point, are mapped to the Last state. In the Last state, the 64 values 80-BF are mapped to MATCHED. This takes care of all the two-byte code points and we’re up to two states.In the Start state, the 16 byte values E0-EF, all of which begin
1110signaling a three-byte code point, are mapped to the LastInter state. In that state, the 64 values 80-BF are mapped to the Last state. Now we’re up to three states and we’ve handled the three-byte code points.In the Start state, the 8 byte values F0-F7, all of which begin 11110 signaling a four-byte code point, are mapped to the FirstInter state. In that state, the 64 values 80-BF are mapped to the LastInter state. Now we’ve handled all the code points with four states.
But wait!
I mentioned above about not wanting to match all the code points. “Wait,” you say, “why wouldn’t you want to be maximally inclusive?!” Once again, I’ll link to Unicode Character Repertoire Subsets, a document I co-wrote that is making its way through the IETF and may become an RFC some year. I’m not going to try to summarize a draft that bends over backwards to be short and clear; suffice it to say that there are good reasons for leaving out several different flavors of code point.
Probably the most pernicious code points are the “Surrogates”, U+D800-U+DFFF. If you want an explanation of what they are and why they’re bad, go read that Repertoire Subsets draft or just take my word for it. If you were to encode them per UTF-8 rules (which the UTF-8 spec says you’re not allowed to), the low and high bounds would be ED,A0,80 and ED,BF,BF.
Go’s UTF-8 implementation agrees that Surrogates Are Bad and The UTF-8 Spec Is Good and flatly refuses to convert those UTF-8 sequences into code points or vice versa. The resulting subset of code points even has a catchy name: Unicode Scalars. Case closed, right?
Wrong. Because JSON was designed before we’d thought through these problems, explicitly saying it’s OK to include any code point whatsoever, including surrogates. And Quamina is used for matching JSON data. So, standards fight!
I’m being a little unfair here. I’m sure that if Doug Crockford were inventing JSON now instead of in 2001, he’d exclude surrogates and probably some of the other problematic code points discussed in that Subsets doc.
Anyhow, Quamina will go with Go and exclude surrogates. Any RFC8259 purists out there, feel free accuse me of standards apostasy and I will grant your point but won’t change Quamina. Actually, not true; at some point I’ll probably add an option to be more restrictive and exclude more than just surrogates.
Which means that now we have to go back to the start of this essay and figure out how many states it takes to match
“.” Let’s see…
The Start state changes a bit. See #5 in the list above. Instead of mapping all of E0-EF to the LastInter state, it maps one byte in that range, ED, to a new state we’ll call, let’s see, how about ED.
In ED, just as in LastInter, 80-9F are mapped to Last. But A0-BF aren’t mapped to anything, because on that path lie the surrogates.
So, going with the Unicode Scalar path of virtue means I need five states, not four.
1994 Hong Kong Adventure 14 Dec 2024, 9:00 pm
This story is about Hong Kong and mountains and ferries and food and beer. What happened was, there’s a thirty-year-old picture I wanted to share and it brought the story to mind. I was sure I’d written it up but can’t find it here on the blog, hard as I try, so here we go. Happy ending promised!
The picture I wanted to share is from a business trip to Hong Kong in 1994 and hey, it turns out I have lots more pictures from that trip.

Kai Tak airport in 1994.

Rats for sale in a sketchy corner of Kowloon.

Kai Tak, what an airport that was. If you could open the plane’s windows, you’d have been able to grab laundry hung to dry on people’s balconies. My fast-talking HK friend said “Safest airport in the world! You know pilot paying 100% attention!”
My trip extended over a weekend and I wanted to get out of town so I read up on interesting walks; on paper of course, the Web only just barely existed. Lantau Island was recommended; there was a good hike up over the local mountains that reached a Trappist monastery with a well-reviewed milk bar. So I took the ferry from Central to Mui Wo.
The view from the ferry was great!


I revisited Mui Wo in 2019, visiting the Big Buddha.
It was easy to find the hiking trail up the mountains, well-maintained but steep. I stopped to take pictures maybe more often than strictly necessary because it was in the high Celsius thirties with 99% humidity and my North-Euro metabolism wasn’t dealing well. Visions of Trappist ice-cream danced in my head as the sweat dripped off my chin.


Having said that, I’m glad I stopped because the pictures please my eye. These are all Ektachrome; can’t remember whether I took them with the Pentax SLR or the little Nikon pocket camera.
Lantau has the new international airport on it now; I wonder if those green hills are still unspoiled.
Eventually, sweat-soaked and my body screaming for mercy, I reached a small mountaintop. I could see the monastery, but it was a couple of little mountains over, so I arrived in poor condition. Sadly for me, it was a Sunday so, commerce deferring to the sacred, the joint was closed. Poor Tim. Especially since I hadn’t brought anything to eat.
Fortunately I didn’t have to hike all the way back to Mui Wo; Almost straight downhill there there was a “Monastery Pier” with an occasional ferry to the nearby islet of Peng Chau and a connection back to Central. Looks like there still is.
It was midafternoon, the heat approaching its peak, and walking downhill has its own stresses and strains. By the time I got to the pier I was a sad excuse for a human. Here’s a picture of the ferry.

As you can see, it was pretty crowded, but unsurprisingly, nobody wanted to share the bench the big sweaty panting hungry-looking pink person was on.
Peng Chau itself was visually charming but the ferry connection was tight so I couldn’t explore.

Peng Chau waterfront in 1994. This is the picture I wanted to share that led me to (re?)tell this story. My conversational-media home on the Net is on Mastodon, but I like to keep an eye on Bluesky, so I post random pictures there under the tag #blueskyabove; this will be one.
Trudging onto the medium-sized ferry back home, I encountered a food-service option: A counter with one guy and a big steaming pot of soup behind it. My spirit lifted. The guy’s outfit might have once been white; he was unshaven and sweaty but then so was I, and my clothes were nothing to write home about either.
I stopped and pointed at the bowls. He filled one, then wanted to upsell me on a leathery, greasy-looking fried egg to go on top but there are limits. Disappointed, he stepped aside to put it back, revealing a small glass-fronted fridge, icicles hanging off it, full of big cans of San Miguel beer. My spirit lifted again.
The soup was salty and delicious. I’m not sure I’ve enjoyed a beer more in the thirty years since that day. The ferry was fast enough to generate a refreshing breeze all the way, and there were charming boats to photograph.

The tourist who walked off the boat at Central was a dry, well-hydrated, and cheerful specimen of humanity. The next day, my fast-talking HK friend said “You climb over Lantau in that weather yesterday? White guys so weird!” “It was great!” I told him, smirking obnoxiously.
I’ve been back to HK a few times over the years, but it’s not really a happy place any more.
QRS: Parsing Regexps 12 Dec 2024, 9:00 pm
Parsing regular expression syntax is hard. I’ve written a lot of parsers and,for this one, adopted a couple of new techniques that I haven’t used before. I learned things that might be of general interest.
I was initially surprised that the problem was harder than it looked, but quickly realized that I shouldn’t have been, because my brain has also always had a hard time parsing them.
They’re definitely a write-only syntax and just because I’m gleefully writing this series doesn’t mean I’m recommending you reach for REs as a tool very often.
But I bet most people in my profession find themselves using them pretty regularly, in the common case where they’re the quickest path from A to B. And I know for sure that, on a certain number of occasions, they’ve ended up regretting that choice.
Anyhow, I console myself with the thought that the I-Regexp RE dialect has less syntax and fewer footguns than PCREs generally. Plus, I’ve been having fun implementing them. So knock yourselves out. (Not legal nor investing advice.)
Sample-driven development
When I started thinking seriously about the parser, the very first thought in my mind was “How in the freaking hell am I going to test this?” I couldn’t stand the thought of writing a single line of code without having a plausible answer. Then it occurred to me that since I-Regexp subsets XSD Regular Expressions, and since XSD (which I mostly dislike) is widely deployed and used, maybe someone already wrote a test suite? So I stuck my head into an XML community space (still pretty vigorous after all these years) and asked “Anyone have an XSD regexp test suite?”
And it worked! (I love this profession sometimes.)
Michael Kay pointed at me a few things notably including
this GitHub repo. The
_regex-syntax-test-set.xml there, too big to display, contains just under a thousand regular expressions, some
valid, some not, many equipped with strings that should and should not match.
The process by which I turned it into a *_test.go file, Dear Reader, was not pretty. I will not share the
ugliness, which involved awk and emacs, plus hideous and largely untested one-off Go code.
But I gotta say, if you have to write a parser for any anything, having 992 sample cases makes the job a whole lot less scary.
Lesson: When you’re writing code to process a data format that’s new to you, invest time, before you start, in looking for samples.
Recursive descent
The I-Regexp specification contains a complete ABNF grammar for the syntax. For writing parsers I tend to like finite-automaton based approaches, but for a freakishly complicated mini-language like this, I bowed in the direction of Olympus for that grammar and started recursively descending.
I think at some point I understood the theory of Regular Languages and LL(1) and so on, but not any more. Having said that, the recursive-descent technique is conceptually simple, so I plowed ahead. And it worked eventually. But there seemed a lot of sloppy corners where I had to peek one byte ahead or backtrack one. Maybe if I understood LL(1) better it’d have been smoother.
The “character-class” syntax [abc0-9] is particularly awful. The possible leading - or
^ makes it worse, and it has the usual \-prefixed stanzas. Once again, I salute the original
specifiers who managed to express this in a usable grammar.
I was tempted, but ended up making no use of Go’s regexp library to help me parse REs.
I have to say that I don’t like the code I ended up with as much as any of my previous (automaton-based) parsers, nor as much as the rest of the Quamina code. But it seems to work OK. Speaking of that…
Test coverage
When I eventually got the code to do the right thing for each of Michael Kay’s 992 test cases, I was feeling a warm glow. So then I ran the test-coverage tool, and got a disappointingly-low number. I’m not a 100%-coverage militant generally, but I am for ultra-low-level stuff like this with a big blast radius.
And here’s the lesson: Code coverage tools are your friend. I went in and looked at the green and red bars; they revealed that while my tests had passed, I was really wrong in my assumptions about the paths they would make the code take. Substantial refactoring ensued.
Second, and somewhat disappointingly, there were a lot of coverage misses on Go’s notorious little if err != nil
stanza. Which revealed that my sample set didn’t cover the RE-syntax space quite as thoroughly as I’d hoped. In particular,
there was really no coverage of the code’s reaction to malformed UTF-8.
The reason I’m writing this is to emphasize that, even if you’re in a shop where the use of code-coverage tools is (regrettably) not required, you should use one anyhow, on basically every important piece of code. I have absolutely never failed to get surprises, and consequently improved code, by doing this.
Sharing the work
I don’t know if I-Regexp is going to be getting any uptake, but it wouldn’t surprise me if it did; it’s a nice tractable subset that hits a lot of use cases. Anyhow, now I have reasonably robust and well-tested I-Regexp parsing code. I’d like to share it, but there’s a problem.
To do that, I’d have to put it in a separate repo; nobody would want to import all of Quamina, which is a fair-sized library, just to parse REs. But then that other repo would become a Quamina dependency. And one of my favorite things about Quamina is that it has 0 dependencies!
It’s not obvious what the right thing to do is; any ideas?
Page processed in 1.003 seconds.
Powered by SimplePie 1.3.1, Build 20121030095402. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.