Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
ongoing by Tim Bray
ongoing fragmented essay by Tim BrayQRS: Matching “.” in UTF-8 18 Dec 2024, 9:00 pm
Back on December 13th, I
posted a challenge on Mastodon: In a simple UTF-8 byte-driven
finite automaton, how many states does it take to match the regular-expression construct “.”, i.e. “any character”?
Commenter
Anthony Williams responded,
getting it almost right I think,
but I found his description a little hard to understand. In this piece I’m going to dig into what
. actually means, and then how many states you need to match it.
The answer surprised me. Obviously this is of interest only to the faction of people who are interested in automaton wrangling, problematic characters, and the finer points of UTF-8. I expect close attention from all 17 of you!
The answer is…
Four. Or five, depending.
What’s a “Unicode character”?
They’re represented by “code points”, which are numbers in the range 0 … 17×216, which is to say 1,114,112 possible values. It turns out you don’t actually want to match all of them; more on that later.
How many states?
Quamina is a “byte-level automaton” which means it’s in a state, it reads a byte, looks up the value of that byte in a map
yielding either the next state, or nil, which means no match. Repeat until you match or fail.
What bytes are we talking about here? We’re talking about UTF-8 bytes. If you don’t understand UTF-8 the rest of this is going to be difficult. I wrote a short explainer called Characters vs. Bytes twenty-one years ago. I now assume you understand UTF-8 and knew that code points are encoded as sequences of from 1 to 4 bytes.
Let’s count!
When you match a code point successfully you move to the part of the automaton that’s trying to match the next one; let’s call this condition MATCHED.
(From here on, all the numbers are hex, I’ll skip the leading 0x. And all the ranges are inclusive.)
In multi-byte characters, all the UTF-8 bytes but the first have bitmasks like
10XX XXXX, so there are six significant bits, thus 26 or 64 distinct possible values ranging from 80-BF.There’s a Start state. It maps byte values 00-7F (as in ASCII) to MATCHED. That’s our first state, and we’ve handled all the one-byte code points.
In the Start state, the 32 byte values C0-DF, all of which begin
110signaling a two-byte code point, are mapped to the Last state. In the Last state, the 64 values 80-BF are mapped to MATCHED. This takes care of all the two-byte code points and we’re up to two states.In the Start state, the 16 byte values E0-EF, all of which begin
1110signaling a three-byte code point, are mapped to the LastInter state. In that state, the 64 values 80-BF are mapped to the Last state. Now we’re up to three states and we’ve handled the three-byte code points.In the Start state, the 8 byte values F0-F7, all of which begin 11110 signaling a four-byte code point, are mapped to the FirstInter state. In that state, the 64 values 80-BF are mapped to the LastInter state. Now we’ve handled all the code points with four states.
But wait!
I mentioned above about not wanting to match all the code points. “Wait,” you say, “why wouldn’t you want to be maximally inclusive?!” Once again, I’ll link to Unicode Character Repertoire Subsets, a document I co-wrote that is making its way through the IETF and may become an RFC some year. I’m not going to try to summarize a draft that bends over backwards to be short and clear; suffice it to say that there are good reasons for leaving out several different flavors of code point.
Probably the most pernicious code points are the “Surrogates”, U+D800-U+DFFF. If you want an explanation of what they are and why they’re bad, go read that Repertoire Subsets draft or just take my word for it. If you were to encode them per UTF-8 rules (which the UTF-8 spec says you’re not allowed to), the low and high bounds would be ED,A0,80 and ED,BF,BF.
Go’s UTF-8 implementation agrees that Surrogates Are Bad and The UTF-8 Spec Is Good and flatly refuses to convert those UTF-8 sequences into code points or vice versa. The resulting subset of code points even has a catchy name: Unicode Scalars. Case closed, right?
Wrong. Because JSON was designed before we’d thought through these problems, explicitly saying it’s OK to include any code point whatsoever, including surrogates. And Quamina is used for matching JSON data. So, standards fight!
I’m being a little unfair here. I’m sure that if Doug Crockford were inventing JSON now instead of in 2001, he’d exclude surrogates and probably some of the other problematic code points discussed in that Subsets doc.
Anyhow, Quamina will go with Go and exclude surrogates. Any RFC8259 purists out there, feel free accuse me of standards apostasy and I will grant your point but won’t change Quamina. Actually, not true; at some point I’ll probably add an option to be more restrictive and exclude more than just surrogates.
Which means that now we have to go back to the start of this essay and figure out how many states it takes to match
“.” Let’s see…
The Start state changes a bit. See #5 in the list above. Instead of mapping all of E0-EF to the LastInter state, it maps one byte in that range, ED, to a new state we’ll call, let’s see, how about ED.
In ED, just as in LastInter, 80-9F are mapped to Last. But A0-BF aren’t mapped to anything, because on that path lie the surrogates.
So, going with the Unicode Scalar path of virtue means I need five states, not four.
1994 Hong Kong Adventure 14 Dec 2024, 9:00 pm
This story is about Hong Kong and mountains and ferries and food and beer. What happened was, there’s a thirty-year-old picture I wanted to share and it brought the story to mind. I was sure I’d written it up but can’t find it here on the blog, hard as I try, so here we go. Happy ending promised!
The picture I wanted to share is from a business trip to Hong Kong in 1994 and hey, it turns out I have lots more pictures from that trip.

Kai Tak airport in 1994.

Rats for sale in a sketchy corner of Kowloon.

Kai Tak, what an airport that was. If you could open the plane’s windows, you’d have been able to grab laundry hung to dry on people’s balconies. My fast-talking HK friend said “Safest airport in the world! You know pilot paying 100% attention!”
My trip extended over a weekend and I wanted to get out of town so I read up on interesting walks; on paper of course, the Web only just barely existed. Lantau Island was recommended; there was a good hike up over the local mountains that reached a Trappist monastery with a well-reviewed milk bar. So I took the ferry from Central to Mui Wo.
The view from the ferry was great!


I revisited Mui Wo in 2019, visiting the Big Buddha.
It was easy to find the hiking trail up the mountains, well-maintained but steep. I stopped to take pictures maybe more often than strictly necessary because it was in the high Celsius thirties with 99% humidity and my North-Euro metabolism wasn’t dealing well. Visions of Trappist ice-cream danced in my head as the sweat dripped off my chin.


Having said that, I’m glad I stopped because the pictures please my eye. These are all Ektachrome; can’t remember whether I took them with the Pentax SLR or the little Nikon pocket camera.
Lantau has the new international airport on it now; I wonder if those green hills are still unspoiled.
Eventually, sweat-soaked and my body screaming for mercy, I reached a small mountaintop. I could see the monastery, but it was a couple of little mountains over, so I arrived in poor condition. Sadly for me, it was a Sunday so, commerce deferring to the sacred, the joint was closed. Poor Tim. Especially since I hadn’t brought anything to eat.
Fortunately I didn’t have to hike all the way back to Mui Wo; Almost straight downhill there there was a “Monastery Pier” with an occasional ferry to the nearby islet of Peng Chau and a connection back to Central. Looks like there still is.
It was midafternoon, the heat approaching its peak, and walking downhill has its own stresses and strains. By the time I got to the pier I was a sad excuse for a human. Here’s a picture of the ferry.

As you can see, it was pretty crowded, but unsurprisingly, nobody wanted to share the bench the big sweaty panting hungry-looking pink person was on.
Peng Chau itself was visually charming but the ferry connection was tight so I couldn’t explore.

Peng Chau waterfront in 1994. This is the picture I wanted to share that led me to (re?)tell this story. My conversational-media home on the Net is on Mastodon, but I like to keep an eye on Bluesky, so I post random pictures there under the tag #blueskyabove; this will be one.
Trudging onto the medium-sized ferry back home, I encountered a food-service option: A counter with one guy and a big steaming pot of soup behind it. My spirit lifted. The guy’s outfit might have once been white; he was unshaven and sweaty but then so was I, and my clothes were nothing to write home about either.
I stopped and pointed at the bowls. He filled one, then wanted to upsell me on a leathery, greasy-looking fried egg to go on top but there are limits. Disappointed, he stepped aside to put it back, revealing a small glass-fronted fridge, icicles hanging off it, full of big cans of San Miguel beer. My spirit lifted again.
The soup was salty and delicious. I’m not sure I’ve enjoyed a beer more in the thirty years since that day. The ferry was fast enough to generate a refreshing breeze all the way, and there were charming boats to photograph.

The tourist who walked off the boat at Central was a dry, well-hydrated, and cheerful specimen of humanity. The next day, my fast-talking HK friend said “You climb over Lantau in that weather yesterday? White guys so weird!” “It was great!” I told him, smirking obnoxiously.
I’ve been back to HK a few times over the years, but it’s not really a happy place any more.
QRS: Parsing Regexps 12 Dec 2024, 9:00 pm
Parsing regular expression syntax is hard. I’ve written a lot of parsers and,for this one, adopted a couple of new techniques that I haven’t used before. I learned things that might be of general interest.
I was initially surprised that the problem was harder than it looked, but quickly realized that I shouldn’t have been, because my brain has also always had a hard time parsing them.
They’re definitely a write-only syntax and just because I’m gleefully writing this series doesn’t mean I’m recommending you reach for REs as a tool very often.
But I bet most people in my profession find themselves using them pretty regularly, in the common case where they’re the quickest path from A to B. And I know for sure that, on a certain number of occasions, they’ve ended up regretting that choice.
Anyhow, I console myself with the thought that the I-Regexp RE dialect has less syntax and fewer footguns than PCREs generally. Plus, I’ve been having fun implementing them. So knock yourselves out. (Not legal nor investing advice.)
Sample-driven development
When I started thinking seriously about the parser, the very first thought in my mind was “How in the freaking hell am I going to test this?” I couldn’t stand the thought of writing a single line of code without having a plausible answer. Then it occurred to me that since I-Regexp subsets XSD Regular Expressions, and since XSD (which I mostly dislike) is widely deployed and used, maybe someone already wrote a test suite? So I stuck my head into an XML community space (still pretty vigorous after all these years) and asked “Anyone have an XSD regexp test suite?”
And it worked! (I love this profession sometimes.)
Michael Kay pointed at me a few things notably including
this GitHub repo. The
_regex-syntax-test-set.xml there, too big to display, contains just under a thousand regular expressions, some
valid, some not, many equipped with strings that should and should not match.
The process by which I turned it into a *_test.go file, Dear Reader, was not pretty. I will not share the
ugliness, which involved awk and emacs, plus hideous and largely untested one-off Go code.
But I gotta say, if you have to write a parser for any anything, having 992 sample cases makes the job a whole lot less scary.
Lesson: When you’re writing code to process a data format that’s new to you, invest time, before you start, in looking for samples.
Recursive descent
The I-Regexp specification contains a complete ABNF grammar for the syntax. For writing parsers I tend to like finite-automaton based approaches, but for a freakishly complicated mini-language like this, I bowed in the direction of Olympus for that grammar and started recursively descending.
I think at some point I understood the theory of Regular Languages and LL(1) and so on, but not any more. Having said that, the recursive-descent technique is conceptually simple, so I plowed ahead. And it worked eventually. But there seemed a lot of sloppy corners where I had to peek one byte ahead or backtrack one. Maybe if I understood LL(1) better it’d have been smoother.
The “character-class” syntax [abc0-9] is particularly awful. The possible leading - or
^ makes it worse, and it has the usual \-prefixed stanzas. Once again, I salute the original
specifiers who managed to express this in a usable grammar.
I was tempted, but ended up making no use of Go’s regexp library to help me parse REs.
I have to say that I don’t like the code I ended up with as much as any of my previous (automaton-based) parsers, nor as much as the rest of the Quamina code. But it seems to work OK. Speaking of that…
Test coverage
When I eventually got the code to do the right thing for each of Michael Kay’s 992 test cases, I was feeling a warm glow. So then I ran the test-coverage tool, and got a disappointingly-low number. I’m not a 100%-coverage militant generally, but I am for ultra-low-level stuff like this with a big blast radius.
And here’s the lesson: Code coverage tools are your friend. I went in and looked at the green and red bars; they revealed that while my tests had passed, I was really wrong in my assumptions about the paths they would make the code take. Substantial refactoring ensued.
Second, and somewhat disappointingly, there were a lot of coverage misses on Go’s notorious little if err != nil
stanza. Which revealed that my sample set didn’t cover the RE-syntax space quite as thoroughly as I’d hoped. In particular,
there was really no coverage of the code’s reaction to malformed UTF-8.
The reason I’m writing this is to emphasize that, even if you’re in a shop where the use of code-coverage tools is (regrettably) not required, you should use one anyhow, on basically every important piece of code. I have absolutely never failed to get surprises, and consequently improved code, by doing this.
Sharing the work
I don’t know if I-Regexp is going to be getting any uptake, but it wouldn’t surprise me if it did; it’s a nice tractable subset that hits a lot of use cases. Anyhow, now I have reasonably robust and well-tested I-Regexp parsing code. I’d like to share it, but there’s a problem.
To do that, I’d have to put it in a separate repo; nobody would want to import all of Quamina, which is a fair-sized library, just to parse REs. But then that other repo would become a Quamina dependency. And one of my favorite things about Quamina is that it has 0 dependencies!
It’s not obvious what the right thing to do is; any ideas?
QRS: Quamina Regexp Series 12 Dec 2024, 9:00 pm
Implementing regular expressions is hard. Hard in interesting ways that make me want to share the lessons. Thus this series, QRS for short.
People who keep an eye on my Quamina open-source pattern-matching project will have noticed a recent absence of updates and conversation. That’s because, persuant to Issue #66, I’m working on adding fairly-full regular-expression matching.
Personal note
This is turning out to be hard. Either it’s the hardest nut I’ve had to crack in many years, or maybe my advanced age is dulling my skills. It’s going to be some time before I can do the first incremental release. Whatever; the learning experiences coming out of this work still feel fresh and fascinating and give me the urge to share.
I hope I can retain that urge as long as I’m still mentally present. In fact, I hope I can retain the ability to work on software. For various reasons, I’ve been under a lot of personal stress in recent years. Stealing time from my adult responsibilities to wrestle with executable abstractions has been a pillar of my sanity.
Anyhow, normally when I code I blog about it, but so far I haven’t because the work is unfinished. Then I realized that it’s too big, and addresses too many distinct problems, to be just one piece, thus this mini-series.
[Readers who don’t know what regular expressions are should probably close this tab now. Don’t feel guilty, nobody who’s not a full-time computing professional should have to know much less care.]
[Notation: I’m gonna say “Regexp” or maybe just “RE” in this series.]
There are at least three pieces I know I’m going to write:
Parsing RE syntax. (Already written!)
Representing parsed REs.
Implementing UTF-8 based automata for REs.
At the moment, I think the hardest part of the work is #1, Parsing. (Maybe that’s because I haven’t really dug very deep into #3 yet.) I’d be amazed if the final series had only three parts.
Now, introductory material.
Which regular expressions?
They come in lots of flavors. The one I’m implementing is I-Regexp, RFC 9485. The observant reader will notice that I co-edited that RFC, and I cheerfully confess to bias.
I-Regexp is basically a subset of XSD Regular Expressions (chosen to subset because they have a nice clean immutable spec), which are a lot like good ol’ PCRE (Perl-compatible regular expressions). Except for:
They are designed assuming they will only ever be used to match against a string and return a “yes” or “no” answer.
They are anchored, which is to say that (unlike PCREs) they’re all assumed to start with
^and end with$.They omit popular single-character escapes like
\wand\Sbecause those are sketchy in the Unicode context.They don’t have capture groups or back-references.
They don’t support character class subtraction, e.g.
[a-z-m-p]
I’m going to claim that they hit a very useful 80/20 point if what you’re interested is asking “Did the field value match?” which of course is all Quamina is interested in doing.
Project strategy
I’m totally not going to try to do all this as a big bang. I’ve got a reliable RE parser now (it was hard!) that recognizes
ten different RE features, ranging from . to everything in
(a+b*c?).|d[ef]{3,9}\?\P{Lu}
Unbackslashing again
Go check out
Unbackslash.
Tl;dr: It’s terribly painful to deal with the standard RE escaping character \ in Go software that is processing
JSON. Because both Go and JSON use \ for escaping and your unit tests eventually fill up with \\ and
\\\\\\\\ and become brutally hard to read. So after publishing that blog piece and running polls on Mastodon,
~ is the new \. So that RE above becomes (a+b*c?).|d[ef]{3,9}~?~P{Lu}.
You’re allowed to not like it. But I request that you hold off pushing the big button that sends me to Hell until you’ve tried writing a few unit tests for REs that you want Quamina to process.
Back to strategy: The first feature is going to be that lovely little dot operator. And thus…
Quiz
Just for fun, here’s an intellectual challenge. Suppose you’re building a byte-at-a-time state machine to process UTF-8 text. How
many states, roughly, would it take to match ., i.e. any single Unicode code point? By “match” I mean reject
any byte sequence that
doesn’t, and when it does match, consume just enough bytes to leave you positioned after the . and ready to start
matching whatever’s next.
I think I’ve found the correct answer. It surprised me, so I’m still sanity-checking, but I think I’m right. I am convinced the problem isn’t as simple as it looks.
Remembering Bonnie 2 Dec 2024, 9:00 pm
The murderer I emailed with is still in prison. And the software that got him pissed off at me still runs, so I ran it. Now here I am to pass on the history and then go all geeky. Here’s the tell: If you don’t know what a “filesystem” is (that’s perfectly OK, few reasonable adults need to) you might want to stay for the murderer story then step off the train.
Filesystems are one of the pieces of software that computers need to run, where “computers” includes your phone and laptop and each of the millions of servers that drive the Internet and populate the cloud. There are many flavors of filesystem and people who care about them care a lot.
One of the differences between filesystems is how fast they are. This matters because how fast the apps you use run depends (partly) on how fast the underlying filesystems are.
Writing filesystem software is very, very difficult and people who have done this earn immense respect from their peers. So, a lot of people try. One of the people who succeeded was named Hans Reiser and for a while his “ReiserFS” filesystem was heavily used on many of those “Linux” servers out there on the Internet that do things for you.
Reiser at one point worked in Russia and used a “mail-order bride” operation to look for a spouse. He ended up marrying Nina Sharanova, one of the bride-brokerage translators, and bringing her back to the US with him. They had two kids, got divorced, and then, on September 3, 2006, he strangled her and buried her in a hidden location.
To make a long story short, he eventually pleaded guilty to a reduced charge in exchange for revealing the grave location, and remains in prison. I haven’t provided any links because it’s a sad, tawdry story, but if you want to know the details the Internet has them.
I had interacted with Reiser a few times as a consequence of having written a piece of filesystem-related software called “Bonnie” (more on Bonnie below). I can’t say he was obviously murderous but I found him unpleasant to deal with.
As you might imagine, people generally did not want to keep using the murderer’s filesystem software, but it takes a long time to make this kind of infrastructure change and just last month, ReiserFS was removed as a Linux option. Which led to this Mastodon exchange:
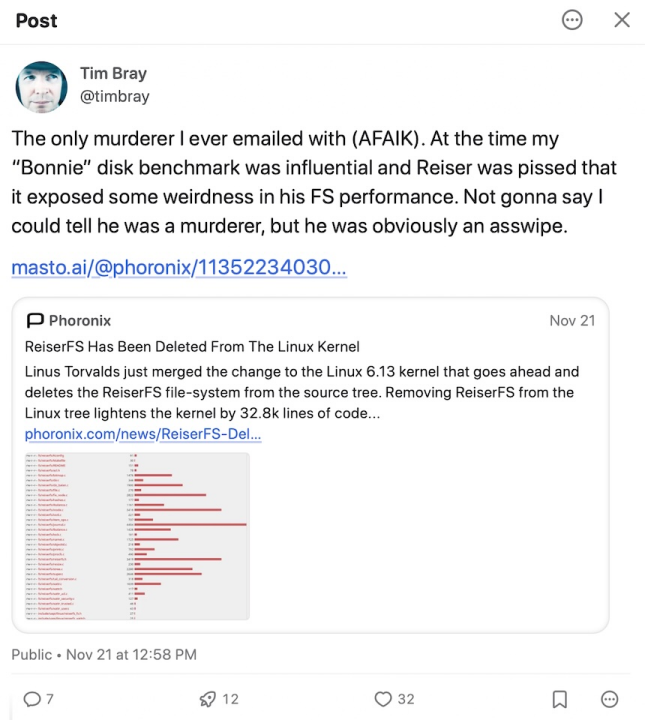
Here’s a link to that post and the conversation that followed.
(People who don’t care about filesystems can stop reading now.)
Now, numbers
After that conversation, on a whim I tracked down the Bonnie source and ran it on my current laptop, a 2023 M2 MacBook Pro with 32G of RAM and 3T of disk. I think the numbers are interesting in and of themselves even before I start discoursing about benchmarking and filesystems and disks and so on.
-------Sequential Output--------- ---Sequential Input--- --Random--
-Per Char- --Block--- -Rewrite-- -Per Char- --Block--- --Seeks---
Machine GB M/sec %CPU M/sec %CPU M/sec %CPU M/sec %CPU M/sec %CPU /sec %CPU
MBP-M2-32G 64 56.9 99.3 3719 89.0 2772 83.4 59.7 99.7 6132 88.0 33613 33.6 Bonnie says:
This puppy can write 3.7 GB/second to a file, and read it back at 6.1GB/sec.
It can update a file in place at 2.8 GB/sec.
It can seek around randomly in a 64GB file at 33K seeks/second.
Single-threaded sequential file I/O is almost but not quite CPU-limited.
I wonder: Are those good numbers for a personal computer in 2024? I genuinely have no idea.
Bonnie
I will shorten the story, because it’s long. In 1988 I was an employee of the University of Waterloo, working on the New Oxford English Dictionary Project. The computers we were using typically had 16MB or so of memory (so the computer I’m typing this on has two thousand times as much) and the full text of the OED occupied 572MB. Thus, we cared really a lot about I/O performance. Since the project was shopping for disks and computers I bashed out Bonnie in a couple of afternoons.
I revised it lots over the years, and Russell Coker made an excellent fork called Bonnie++ that (for a while at least) was more popular than Bonnie. Then I made my own major revision at some point called Bonnie-64.
In 1996, Linux Torvalds recommended Bonnie, calling it a “reasonable disk performance benchmark”.
That’s all I’m going to say here. If for some weird reason you want to know more, Bonnie’s quaint Nineties-flavor home and description pages are still there, plus this blog has documented Bonnie’s twisty history quite thoroughly. And explored, I claim, filesystem-performance issues in a useful way.
I will address a couple of questions here, though.
Do filesystems matter?
Many performance-sensitive applications go to a lot of work to avoid reading and/or writing filesystem data on their critical path. There are lots of ways to accomplish this, the most common being to stuff everything into memory using Redis or Memcached or, well, those two dominate the market, near as I can tell. Another approach is to have the data in a file but access it with mmap rather than filesystem logic. Finally, since real disk hardware reads and writes data in fixed-size blocks, you could arrange for your code to talk straight to the disk, entirely bypassing filesystems. I’ve never seen this done myself, but have heard tales of major commercial databases doing so.
I wonder if anyone has ever done a serious survey study of how the most popular high-performance data repositories, including Relational, NoSQL, object stores, and messaging systems, actually persist the bytes on disk when they have to?
I have an opinion, based on intuition and having seen the non-public inside of several huge high-performance systems at previous employers that, yes, filesystem performance still matters. I’ve no way to prove or even publicly support that intuition. But my bet is that benchmarks like Bonnie are still relevant.
I bet a few of the kind of people who read this blog similarly have intuitions which, however, might be entirely different than mine. I’d like to hear them.
What’s a “disk”?
There is a wide range of hardware and software constructs which are accessed through filesystem semantics. They have wildly different performance envelopes. If I didn’t have so many other hobbies and projects, it’d be fun to run Bonnie on a sample of EC2 instance types with files on various EBS and EFS and so on configurations.
For the vast majority of CPU/storage operations in the cloud, there’s at least one network hop involved. Out there in the real world, there is still really a lot of NFS in production. None of these things are much like that little SSD slab in my laptop. Hmmm.
Today’s benchmarks
I researched whether some great-great-grandchild of Bonnie was the new hotness in filesystem benchmarking, adopting the methodology of typing “filesystem benchmark” into Web search. The results were disappointing; it doesn’t seem like this is a thing people do a lot. Which would suggest that people don’t care about filesystem performance that much? Which I don’t believe. Puzzling.
Whenever there was a list of benchmarks you might look at, Bonnie and Bonnie++ were on that list. Looks to me like IOZone gets the most ink and is thus probably the “industry-leading” benchmark. But I didn’t really turn up any examples of quality research comparing benchmarks in terms of how useful the results are.
Those Bonnie numbers
The biggest problem in benchmarking filesystem I/O is that Linux tries really hard to avoid doing it, aggressively using any spare memory as a filesystem cache. This is why serving static Web traffic out of the filesystem often remains a good idea in 2024; your server will take care of caching the most heavily fetched data in RAM without you having to do cache management, which everyone knows is hard.
I have read of various cache-busting strategies and have never really been convinced that they’ll outsmart this aspect of Linux, which was written by people who are way smarter and know way more than I think I do. So Bonnie has always used a brute-force approach: Work on a test file which is much bigger than main memory, so Linux has to do at least some real I/O. Ideally you’d like it to be several times the memory size.
But this has a nasty downside. The computer I’m typing on has 32GB of memory, so I ran Bonnie with a 64G filesize (128G would have been better) and it took 35 minutes to finish. I really don’t see any way around this annoyance but I guess it’s not a fatal problem.
Oh, and those numbers: Some of them look remarkably big to me. But I’m an old guy with memories of how we had to move the bits back and forth individually back in the day, with electrically-grounded tweezers.
Reiser again
I can’t remember when this was, but some important organization was doing an evaluation of filesystems for inclusion in a big contract or standard or something, and so they benchmarked a bunch, including ReiserFS. Bonnie was one of the benchmarks.
Bonnie investigates the rate at which programs can seek around in a file by forking off three child processes that do a bunch of random seeks, read blocks, and occasionally dirty them and write them back. You can see how this could be stressful for filesystem code, and indeed, it occasionally made ReiserFS misbehave, which was noted by the organization doing the benchmarking.
Pretty soon I had email from Reiser claiming that what Bonnie was doing was actually violating the contract specified for the filesystem API in terms of concurrent write access. Maybe he was right? I can’t remember how the conversation went, but he annoyed me and in the end I don’t think I changed any code.
Here’s Bonnie
At one time Bonnie was on SourceForge, then Google Code, but I decided that if I were going to invest effort in writing this blog, it should be on GitHub too, so here it is. I even filed a couple of bugs against it.
I make no apologies for the rustic style of the code; it was another millennium and I was just a kid.
I cheerfully admit that I felt a warm glow checking in code originally authored 36 years ago.
Why Not Bluesky 15 Nov 2024, 9:00 pm
As a dangerous and evil man drives people away from Xitter, many stories are talking up Bluesky as the destination for the diaspora. This piece explains why I kind of like Bluesky but, for the moment, have no intention of moving my online social life away from the Fediverse.
(By “Fediverse” I mean the social network built around the ActivityPub protocol, which for most people means Mastodon.)
If we’re gonna judge social-network alternatives, here are three criteria that, for me, really matter: Technology, culture, and money.
I don’t think that’s controversial. But this is: Those are in increasing order of importance. At this point in time, I don’t think the technology matters at all, and money matters more than all the others put together. Here’s why.
Technology
Mastodon and the rest of the fediverse rely on ActivityPub implementations. Bluesky relies on the AT Protocol, of which so far there’s only one serious implementation.
Both of these protocols are good enough. We know this is true because both are actually working at scale, providing good and reliable experiences to large numbers of people. It’s reasonable to worry what happens when you get to billions of users and also about which is more expensive to operate. But speaking as someone who spent decades in software and saw it from the inside at Google and AWS, I say: meh. My profession knows how to make this shit work and work at scale. Neither alternative is going to fail, or to trounce its competition, because of technology.
I could write many paragraphs about the competing nice features and problems of the competing platforms, and many people have. But it doesn’t matter that much because they’re both OK.
Culture
At the moment, Bluesky seems, generally speaking, to be more fun. The Fediverse is kind of lefty and geeky and queer. The unfortunate Mastodon culture of two years ago (“Ewww, you want us to have better tools and be more popular? Go away!”) seems to have mostly faded out. But the Fediverse doesn’t have much in the way of celebrities shitposting about the meme-du-jour. In fact it’s definitely celebrity-lite.
I enjoy both cultural flavors, but find Fedi quite a lot more conversational. There are others who find the opposite.
More important, I don’t think either culture is set in stone, or has lost the potential to grow in multiple new, interesting directions.
Money
Here’s the thing. Whatever you think of capitalism, the evidence is overwhelming: Social networks with a single proprietor have trouble with long-term survival, and those that do survive have trouble with user-experience quality: see Enshittification.
The evidence is also perfectly clear that it doesn’t have to be this way. The original social network, email, is now into its sixth decade of vigorous life. It ain’t perfect but it is essential, and not in any serious danger.
The single crucial difference between email and all those other networks — maybe the only significant difference — is that nobody owns or controls it. If you have a deployment that can speak the languages of IMAP and SMTP and the many anti-spam tools, you are de facto part of the global email social network.
The definitive essay on this question is Mike Masnick’s Protocols, Not Platforms: A Technological Approach to Free Speech. (Mike is now on Bluesky’s Board of Directors.)
What does success look like?
My bet for the future (and I think it’s the only one with a chance) is a global protocol-based conversation with many thousands of individual service providers, many of which aren’t profit-oriented businesses. One of them could be your local Buddhist temple, and another could be Facebook. The possibilities are endless: Universities, government departments, political parties, advocacy organizations, sports teams, and, yes, tech companies.
It’s obvious to me that the Fediverse has the potential to become just this. Because it’s most of the way there already.
Could Bluesky? Well, maybe. As far as I can tell, the underlying AT Protocol is non-proprietary and free for anyone to build on. Which means that it’s not impossible. But at the moment, the service and the app are developed and operated by “Bluesky Social, PBC”. In practice, if that company fails, the app and the network go away. Here’s a bit of Bluesky dialogue:
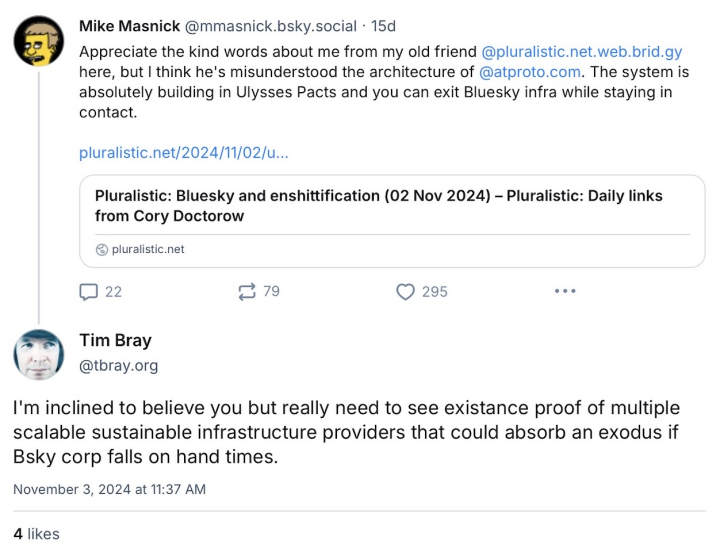
In practice, “Bsky corp” is not in immediate danger of hard times. Their team is much larger than Mastodon’s and on October 24th they announced they’d received $15M in funding, which should buy them at least a year.
But that isn’t entirely good news. The firm that led the investment is seriously sketchy, with strong MAGA and cryptocurrency connections.
The real problem, in my mind, isn’t in the nature of this particular Venture-Capital operation. Because the whole raison-d’etre of Venture Capital is to make money for the “Limited Partners” who provide the capital. Since VC investments are high-risk, most are expected to fail, and the ones that succeed have to exhibit exceptional revenue growth and profitability. Which is a direct path to the problems of survival and product quality that I mentioned above.
Having said that, the investment announcement is full of soothing words about focus on serving the user and denials that they’ll go down the corrupt and broken crypto road. I would like to believe that, but it’s really difficult.
To be clear, I’m a fan of the Bluesky leadership and engineering team. With the VC money as fuel, I expect their next 12 months or so to be golden, with lots of groovy features and mind-blowing growth. But that’s not what I’ll be watching.
I’ll be looking for ecosystem growth in directions that enable survival independent of the company. In the way that email is independent of any technology provider or network operator.
Just like Mastodon and the Fediverse already are.
Yes, in comparison to Bluesky, Mastodon has a smaller development team and slower growth and fewer celebrities and less buzz. It’s supported by Patreon donations and volunteer labor. And in the case of my own registered co-operative instance CoSocial.ca, membership dues of $50/year.
Think of the Fediverse not as just one organism, but a population of mammals, scurrying around the ankles of the bigger and richer alternatives. And when those alternatives enshittify or fall to earth, the Fediversians will still be there. That’s why it’s where my social-media energy is still going.
Read more
On the Fediverse you can follow a hashtag and I’m subscribed to #Bluesky, which means a whole lot of smart, passionate writing on the subject has been coming across my radar. If you’re interested enough to have read to the bottom of this piece, I bet one or more of these will reward an investment of your time:
Maybe Bluesky has “won”, by Gavin Anderegg, goes deep on the trade-offs around Bluesky’s AT Protocol and shares my concern about money.
Blue Sky Mine, by Rob Horning, ignores technology and wonders about the future of text-centric social media and is optimistic about Bluesky.
Does Bluesky have the juice?, by Max Read, is kind of cynical but says smart things about the wave of people currently landing on Bluesky.
The Great Migration to Bluesky Gives Me Hope for the Future of the Internet, by Jason Koebler over at 404 Media, is super-optimistic: “Bluesky feels more vibrant and more filled with real humans than any other social media network on the internet has felt in a very long time.” He also wonders out loud if Threads’ flirtation with Mastodon has been damaging. Hmm.
And finally there’s Cory Doctorow, probably the leading thinker about the existential conflict between capitalism and life online, with Bluesky and enshittification. This is the one to read if you’re thinking that I’m overthinking and over-worrying about a product that is actually pretty nice and currently doing pretty well. If you don’t know what a “Ulysses Pact” is, you should read up and learn about it. Strong stuff.
Privacy, Why? 14 Nov 2024, 9:00 pm
They’re listening to us too much, and watching too. We’re not happy about it. The feeling is appropriate but we’ve been unclear about why we feel it.
[Note: This is adapted from a piece called Privacy Primer that I published on Medium in 2013. I did this mostly because Medium was new and shiny then and I wanted to try it out. But I’ve repeatedly wanted to refer to it and then when I looked, wanted to fix it up a little, so I’ve migrated it back to its natural home on the blog.]
This causes two problems: First, people worry that they’re being unreasonable or paranoid or something (they’re not). Second, we lack the right rhetoric (in the formal sense; language aimed at convincing others) for the occasions when we find ourselves talking to the unworried, or to law-enforcement officials, or to the public servants minding the legal framework that empowers the watchers.
The reason I’m writing this is to shoot holes in the “If you haven’t done anything wrong, don’t worry” story. Because it’s deeply broken and we need to refute it efficiently if we’re going to make any progress.
Privacy is a gift of civilization
Living in a civilized country means you don’t have to poop in a ditch, you don’t have to fetch water from the well or firewood from the forest, and you don’t have to share details of your personal life. It is a huge gift of civilization that behind your front door you need not care what people think about how you dress, how you sleep, or how you cook. And that when communicating with friends and colleagues and loved ones, you need not care what anyone thinks unless you’ve invited them to the conversation.

Photo credit: Beyond My Ken, via Wikimedia Commons
Privacy doesn’t need any more justification. It’s a quality-of-life thing and needs no further defense. We and generations of ancestors have worked hard to build a civilized society and one of the rewards is that often, we can relax and just be our private selves. So we should resist anyone who wants to take that away.
Bad people
The public servants and private surveillance-capitalists who are doing the watching are, at the end of the day, people. Mostly honorable and honest; but some proportion will always be crooked or insane or just bad people; no higher than in the general population, but never zero. I don’t think Canada, where I live, is worse than anywhere else, but we see a pretty steady flow of police brutality and corruption stories. And advertising is not a profession built around integrity. These are facts of life.
Given this, it’s unreasonable to give people the ability to spy on us without factoring in checks and balances to keep the rogues among them from wreaking havoc.
“But this stuff isn’t controversial”
You might think that your communications are definitely not suspicious or sketchy, and in fact boring, and so why should you want privacy or take any effort to have it?
Because you’re forgetting about the people who do need privacy. If only the “suspicious” stuff is made private, then our adversaries will assume that anything that’s private must be suspicious. That endangers our basic civilizational privacy privilege and isn’t a place we want to be.
Talking points for everyday use
First, it’s OK to say “I don’t want to be watched”; no justification is necessary. Second, as a matter of civic hygiene, we need to be regulating our watchers, watching out for individual rogues and corrupt cultures.
So it’s OK to demand privacy by default; to fight back against those who would commandeer the Internet; and (especially) to use politics to empower the watchers’ watchers; make their political regulators at least as frightened of the voters as of the enemy.
That’s the reasonable point of view. It’s the surveillance-culture people who want to abridge your privacy who are being unreasonable.
TV In 2024 11 Nov 2024, 9:00 pm
It’s probably part of your life too. What happened was, we moved to a new place and it had a room set up for a huge TV, so I was left with no choice but to get one. Which got me thinking about TV in general and naturally it spilled over here into the blog. There is good and bad news.
Buying a TV
It’s hard. You visit Wirecutter and Consumer Reports and the model numbers they recommend often don’t quite match the listings at the bigbox Web site. Plus too many choices. Plus it’s deceiving because all the name-brand TVs these days have fabulous pictures.
Having bought a TV doesn’t make me an expert, but for what it’s worth we got a 77" Samsung S90C, which is Samsung’s second-best offering from 2023. Both WC and CR liked it last year and specifically called out that it works well in a bright room; ours is south-facing. And hey, it has quantum dots, so it must be good.
Actually I do have advice. There seems to be a pattern where last year’s TV is often a good buy, if you can find one. And you know where you can often find last year’s good product at a good price? Costco, that’s where, and that’s where we went. Glad we did, because when after a week’s use it frapped out, Costco answered the phone pretty quick and sent over a replacement.
But anyhow, the upside is that you’ll probably like whatever you get. TVs are just really good these days.
Standards!
We were moving the gear around and I snapped a picture of all the video and audio pieces stacked up together. From behind.

The enlarged version of this photo has
embedded
Content Credentials to establish provenance.
Speaking as a guy who’s done standards: This picture is evidence of excellence. All those connections, and the signals they exchange, are 100% interoperable. All the signals are “line-level” (RCA or XLR wires and connectors), or video streams (HDMI), or to speakers (you should care about impedance and capacitance, but 12ga copper is good enough).
Put another way: No two of those boxes come from the same vendor, but when I wired them all up it Just Worked. First time, no compatibility issues. The software profession can only dream of this level of excellence.
Because of this, you can buy all the necessary connectors and cabling super-cheap from your favorite online vendor, but if you’re in Vancouver, go to Lee’s Electronics, where they have everything and intelligent humans will help you find it.
Fixing the picture
Out of the box the default settings yield eye-stabbing brilliance and contrast, entirely unrealistic, suitable (I guess?) for the bigbox shelves.
“So, adjust the picture,” you say. Cue bitter laughter. There are lots of dials to twist; too many really. And how do you know when you’ve got it right? Of course there are YouTubers with advice, but they don’t agree with each other and are short on quantitative data or color science, it’s mostly “This is how I do it and it looks great so you should too.”
What I want is the equivalent of the Datacolor “Spyder” color calibrators. And I wonder why such a thing couldn’t be a mobile app — phonecams are very high-quality these days and have nice low-level APIs. You’d plug your phone into the screen with a USB-C-to-HDMI adapter, it’d put patterns on the screen, and you’d point your phone at them, and it’d tell you how close you are to neutral.
It turns out there are objective standards and methods for measuring color performance; for example, see “Delta-E” in the Tom’s Hardware S90C review. But they don’t help consumers, even reasonably technical ones like me, fine-tune their own sets.
Anyhow, most modern TVs have a “Filmmaker” or “Cinema” setting which is said to be the truest-to-life. So I pick that and then fine-tune it, subjectively. Measurements, who needs ’em?
Privacy
Our TVs spy on us. I have repeatedly read that hardware prices are low because the profit is in mining and selling your watching habits. I’ve not read anything that has actual hard facts about who’s buying and how much they’re paying, but it feels so obvious that it’d be stupid not to believe it.
It’s hopeless to try and keep it from happening. If you’re watching a show on Netflix or a ballgame on MLB.tv, or anything on anything really, they’re gonna sell that fact, they’re up-front about it.
What really frosts my socks, though, is ACR, Automatic Content Recognition, where the TV sends hashed screenshots to home base so it (along with Netflix and MLB and so on) can sell your consumption habits to whoever.
Anyhow, here’s what we do. First, prevent the TV from connecting to the Internet, then play all the streaming services through a little Roku box. (With the exception of one sports streamer that only does Chromecast.) Roku lets you turn off ACR, and Chromecast promises not to. Imperfect but better than nothing.
What to watch?
That’s the problem, of course. It seems likely we’re in the declining tail-end of the Golden Age of TV. The streamers, having ripped the guts out of the cable-TV industry, are turning into Cable, the Next Generation. The price increases are relentless. I haven’t so far seen a general quality decline but I’ve read stories about cost-cutting all over the industry. Even, for example, at Apple, which is currently a quality offering.
And, of course, subscription fatigue. There are lots of shows that everyone agrees are excellent that we’ll never see because I just absolutely will not open my wallet on a monthly basis to yet another outgoing funnel. I keep thinking I should be able to pay to watch individual shows that I want to watch, no matter who’s streaming them. Seems that’s crazy talk.
We only watch episodic TV one evening or so a week, and only a couple episodes at a time, so we’re in no danger of running out of input. I imagine being (unlike us) a real video connoisseur must be an (expensive) pain in the ass these days.
But you already knew all that.
Can it work?
Well, yeah. A big honkin’ modern TV being driven by a quality 4K signal can be pretty great. We’re currently watching 3 Body Problem, which has occasional fabulous visuals and also good sound design. I’m pretty sure the data show that 4K, by any reasonable metric, offers enough resolution and color-space coverage for any screen that can fit in a reasonable home. (Sidebar: Why 8K failed.)
The best picture these days is the big-money streamer shows. But not only. On many evenings, I watch YouTube concert videos before I go to bed. The supply is effectively infinite. Some of them are shakycam productions filmed from row 54 (to be fair, some of those capture remarkably good sound). But others are quality 4K productions and I have to say that can be a pretty dazzling sensory experience.
Here are a couple of captures from a well-shot show on PJ Harvey’s current tour, which by the way is musically fabulous. No, I didn’t get it off the TV, I got it from a 4K monitor on my Mac, but I think it gives the feel.


Content Credentials here too.
AUDIO visual
In our previous place we had a big living room with the deranged-audiophile stereo in it, and the TV was in a little side-room we called the Video Cave. The new place has a media room with the big TV wall, so I integrated the systems and now the sound accompanying the picture goes through high-end amplification and (for the two front channels) speakers.
It makes more difference than I would have thought. If you want to improve your home-theatre experience, given that TV performance is plateauing, better speakers might be a good option.
Live sports
I like live-sports TV. I acknowledge many readers will find this distasteful, for reasons I can’t really disagree with; not least is maybe encouraging brain-damaging behavior in young men. I can’t help it; decades ago I was a pretty good basketball player at university and a few of those games remain among my most intense memories.
I mean, I like drama. In particular I like unscripted drama, where neither you nor your TV hosts know how the show’s going to end. Which is to say, live sports.
I’ve griped about this before, but once again: The state of the sports-broadcasting art is shamefully behind what the hardware can do.
The quality is all over the map, but football, both fútbol and gridiron, is generally awful. I’ve read that the problem is the expense of the in-stadium broadcast infrastructure, routing all the fat 4K streams to the TV truck and turning them into a coherent broadcast.
In practice, what we’re getting is not even as good as a quality 1080p signal. It’s worth noting that Apple TV’s MLS and MLB broadcasts are noticeably better (the sound is a lot better).
It can only improve, right?
Control how?
When I sit on the comfy video-facing furniture, I need to control Samsung, Parasound, Marantz, Roku, and Chromecast devices. We use a Logitech Harmony; I have another in reserve, both bought off eBay. Logitech has dropped the product but someone is still updating the database; or at least was through 2023, because it knows how to talk to that Samsung TV.
They work well enough that I don’t have to be there for other family members to watch a show. Once they wear out, I have no freaking idea what Plan B is. That’s OK, maybe I’ll die first. And because (as noted above) the audio side has superb interoperability, I can count on upgrading speakers and amplifiers and so on for as long as I last.
Golden age?
Yes, I guess, for TV hardware. As for the shows, who knows? Not my problem; I’m old enough and watch little enough that there’s plenty out there to fill the remainder of my life.
C2PA Progress 29 Oct 2024, 8:00 pm
I took a picture looking down a lane at sunset and liked the way it came out, so I prettied it up a bit in Lightroom to post on Mastodon. When I exported the JPG, I was suddenly in the world of C2PA, so here’s a report on progress and problems. This article is a bit on the geeky side but I think the most interesting bits concern policy issues. So if you’re interested in online truth and disinformation you might want to read on.
If you don’t know what “C2PA” is, I immodestly think my introduction is a decent place to start. Tl;dr: Verifiable provenance for online media files. If for some reason you think “That can’t possibly work”, please go read my intro.
Here’s the Lightroom photo-export dialog that got my attention:
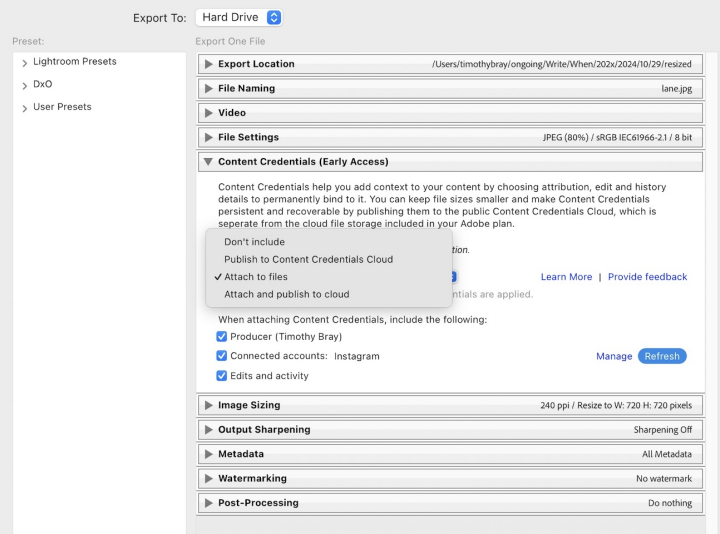
There’s interesting stuff in that dialog. First, it’s “Early Access”, and I hope that means not fixed in stone, because there are issues (not just the obvious typo); I’ll get to them.
Where’s the data?
There’s a choice of where to put the C2PA data (if you want any): Right there in the image, in “Content Credentials Cloud” (let’s say CCC), or both. That CCC stuff is (weakly) explained here — scroll down to “How are Content Credentials stored and recovered?” I think storing the C2PA data in an online service rather than in the photo is an OK idea — doesn’t weaken the verifiability story I think, although as a blogger I might be happier if it were stored here on the blog? This whole area is work in progress.
What surprised me on that Adobe CCC page was the suggestion that you might be able to recover the C2PA data about a picture from which it had been stripped. Obviously this could be a very bad thing if you’d stripped that data for a good reason.
I’m wondering what other fields you could search on in CCC… could you find pictures if you knew what camera they were shot with, on some particular date? Lots of complicated policy issues here.
Also there’s the matter of size: The raw JPG of the picture is 346K, which balloons to 582K with the C2PA. Which doesn’t bother me in the slightest, but if I were serving millions of pictures per day it would.
Who provided the picture?
I maintain that the single most important thing about C2PA isn’t recording what camera or software was used, it’s identifying who the source of the picture is. Because, living online, your decisions on what to believe are going to rely heavily on who to believe. So what does Lightroom’s C2PA feature offer?
First, it asserts that the picture is by “Timothy Bray”; notice that that value is hardwired and I can’t change it. Second, that there’s a connected account at Instagram. In the C2PA, these assertions are signed with an Adobe-issued certificate, which is to say Adobe thinks you should believe them.
Let’s look at both. Adobe is willing to sign off on the author being “Timothy Bray”, but they know a lot more about me; my email, and that I’ve been a paying customer for years. Acknowledging my name is nice but it’d be really unsurprising if they have another Tim Bray among their millions of customers. And suppose my name was Jane Smith or some such.
It’d be well within Adobe’s powers to become an identity provider and give me a permanent ID like “https://id.adobe.com/timbray0351”, and include that in the C2PA. Which would be way more useful to establish provenance, but then Adobe Legal would want to take a very close look at what they’d be getting themselves into.
But maybe that’s OK, because it’s offering to include my “Connected” Instagram account, https://www.instagram.com/twbray. By “connected” they mean that Lightroom went through an OAuth dance with Meta and I had to authorize either giving Insta access to Adobe or Adobe to Insta, I forget which. Anyhow, that OAuth stuff works. Adobe really truly knows that I control that Insta ID and they can cheerfully sign off on that fact.
They also offered me the choice of Behance, Xitter, and LinkedIn.
I’ll be honest: This excites me. If I really want to establish confidence that this picture is from me, I can’t think of a better way than a verifiable link to a bunch of my online presences, saying “this is from that guy you also know as…” Obviously, I want them to add my blog and Mastodon and Bluesky and Google and Apple and my employer and my alma mater and my bank, and then let me choose, per picture, which (if any) of those I want to include in the C2PA. This is very powerful stuff on the provenance front.
Note that the C2PA doesn’t include anything about what kind of device I took the picture on (a Pixel), nor when I took it, but that’d be reasonably straightforward for Google’s camera app to include. I don’t think that information is as important as provenance but I can imagine applications where it’d be interesting.
What did they do to the picture?
The final choice in that export dialog is whether I want to disclose what I did in Lightroom: “Edits and Activity”. Once again, that’s not as interesting as the provenance, but it might be if we wanted to flag AI intervention. And there are already problems in how that data is used; more below.
Anyhow, here’s the picture; I don’t know if it pleases your eye but it does mine.

Now, that image just above has been through the ongoing publishing system, which doesn’t know about C2PA, but if you click and enlarge it, the version you get is straight outta Lightroom and retains the C2PA data.
If you want to be sure, install
c2patool, and apply it to lane.jpg.
Too lazy? No problem, because here’s the JSON output (with the --detailed option).
If you’re geeky at all and care about this stuff, you might want to poke around in there.
{kind=link}
Another thing you might want to do is download lane.jpg and feed it to the Adobe Content Authenticity Inspect page. Here’s what you get:
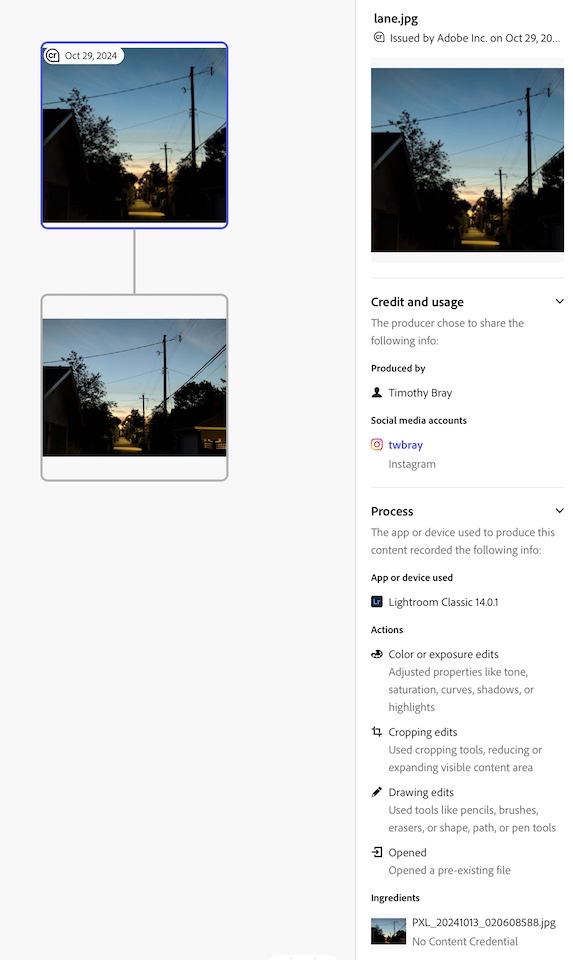
This is obviously a service that’s early in its life and undoubtedly will get more polish. But still, interesting and useful.
Not perfect
In case it’s not obvious, I’m pretty bullish on C2PA and think it provides us useful weapons against online disinformation and to support trust frameworks. So, yay Adobe, congrats on an excellent start! But, things bother me:
-
[Update: There used to be a complaint about c2patool here, but its author got in touch with me and pointed out that when you run it and doesn’t complain about validation problems, that means there weren’t any. Very UNIX. Oops.]
Adobe’s Inspector is also available as a Chrome extension. I’m assuming they’ll support more browsers going forward. Assuming a browser extension is actually useful, which isn’t obvious.
The Inspector’s description of what I did in Lightroom doesn’t correspond very well to what the C2PA data says. What I actually did, per the C2PA, was (look for “actions” in the JSON):
Opened an existing file named “PXL_20241013_020608588.jpg”.
Reduced the exposure by -15.
Generated a (non-AI) mask, a linear gradient from the top of the picture down.
In the mask, moved the “Shadows” slider to -16.
Cropped and straightened the picture (the C2PA doesn’t say how much).
Changed the masking again; not sure why this is here because I didn’t do any more editing.
The Inspector output tries to express all this in vague nontechnical English, which loses a lot of information and in one case is just wrong: “Drawing edits: Used tools like pencils, brushes, erasers, or shape, path, or pen tools”. I think that in 2024, anyone who cares enough to look at this stuff knows about cropping and exposure adjustments and so on, they’re ubiquitous everywhere photos are shared.
If I generate C2PA data in an Adobe product, and if I’ve used any of their AI-based tools that either create or remove content, that absolutely should be recorded in the C2PA. Not as an optional extra.
I really, really want Adobe to build a flexible identity framework so you can link to identities via DNS records or
.well-knownfiles or OpenID Connect flows, so that I get to pick which identities are included with the C2PA. This, I think, would be huge.This is not an Adobe problem, but it bothers me that I can’t upload this photo to any of my social-media accounts without losing the C2PA data. It would be a massive win if all the social-media platforms, when you uploaded a photo with C2PA data, preserved it and added more, saying who initially uploaded it. If you know anyone who writes social-media software, please tell them.
Once again, this is progress! Life online with media provenance will be better than the before times.
LLMM 28 Oct 2024, 8:00 pm
The ads are everywhere; on bus shelters and in big-money live-sportscasts and Web interstitials. They say Apple’s products are great because Apple Intelligence and Google’s too because Google Gemini. I think what’s going on here is pretty obvious and a little sad. AI and GG are LLMM: Large Language Mobile Marketing!
It looks like this:

Here are nice factual Wikipedia rundowns on Apple Intelligence and Google Gemini.
The object of the game is to sell devices, and the premise seems to be that people will want to buy them because they’re excited about what AI and GG will do for them. When they arrive, that is, which I guess they’re just now starting to. I guess I’m a little more LLM-skeptical than your average geek, but I read the list of features and thought: Would this sort of thing accelerate my mobile-device-upgrade latency, which at the moment is around three years? Um, no. Anyone’s? Still dubious.
Quite possibly I’m wrong. Maybe there’ll be a wave of influencers raving about how AI/GG improved their sex lives, income, and Buddha-nature, the masses will say “gotta get me some of that” and quarterly sales will soar past everyone’s stretch goals.
What I think happened
I think that the LLMania among the investor/executive class led to a situation where massive engineering muscle was thrown at anything with genAI in its pitch, and when it came time to ship, demanded that that be the white-hot center of the launch marketing.
Because just at the moment, a whole lot of nontechnical people with decision-making power have decided that it’s lethally risky not to bet the farm on a technology they don’t understand. It’s not like it’s the first time it’s happened.
Why it’s sad
First, because the time has long gone when a new mobile-device feature changed everyone’s life. Everything about them is incrementally better every year. When yours wears out, there’ll be a bit of new-shiny feel about onboarding to your new one. But seriously, what proportion of people buy a new phone for any reason other than “the old one wore out”?
This is sad personally for me because I was privileged to be there, an infinitesimally small contributor during the first years of the mobile wave, when many new features felt miraculous. It was a fine time but it’s gone.
The other reason it’s sad is the remorseless logic of financialized capitalism; the revenue number must go up even when the audience isn’t, and major low-hanging unmet needs are increasingly hard to find.
So, the machine creates a new unmet need (for AI/GG) and plasters it on bus shelters and my TV screen. I wish they wouldn’t.
Cursiveness 18 Oct 2024, 9:00 pm
I’ve found relief from current personal stress in an unexpected place: what my mother calls “penmanship”, i.e. cursive writing that is pleasing to the eye and clearly legible. (Wikipedia’s definition of “penmanship” differs, interestingly. Later.) Herewith notes from the handwriting front.
[Oh, that stress: We’re in the final stages of moving into a newly-bought house from the one we bought 27 years ago, and then selling the former place. This is neither easy nor fun. Might be a blog piece in it but first I have to recover.]
My generation
I’m not sure which decade handwriting ceased to matter to schoolchildren; my own kids got a derisory half-term unit. I have unpleasant elementary-school memories of my handwriting being justly criticized, month after month. And then, after decades of pounding a keyboard, it had devolved to the point where I often couldn’t read it myself.
Which I never perceived as much of a problem. I’m a damn fast and accurate typist and for anything that matters, my communication failures aren’t gonna involve letterforms.
I’ve been a little sad that I had become partly illiterate, absent a keyboard and powerful general-purpose computer. But it wasn’t actually a problem. And my inability to decipher my own scribbling occasionally embarrassed me, often while standing in a supermarket aisle. (If your family is as busy as mine, a paper notepad in a central location is an effective and efficient way to build a shopping list.)
Then one night
I was in bed but not asleep and my brain meandered into thoughts of handwriting; then I discovered that the penmanship lessons from elementary school seemed still to be lurking at the back of my brain. So I started mentally handwriting random texts on imaginary paper, seeing if I could recall all those odd cursive linkages. It seemed I could… then I woke up and it was morning. This has continued to work, now for several weeks.
So that’s a quality-of-life win for me: Mental penmanship as a surprisingly strong soporific. Your mileage may vary.
What, you might ask, is the text that I virtually handwrite? Famous poems? Zen koans? The answer is weirder: I turn some switch in a corner of my brain and words that read sort of like newspaper paragraphs come spilling out, making sense but really meaning anything.
Makes me wonder if I have an LLM in my mind.
Dots and crosses
After the occasional bedtime resort to mental cursive, I decided to try the real thing, grabbed the nearest pen-driven tablet, woke up an app that supports pen input, and started a freehand note. I found, pleasingly, that if I held the childhood lessons consciously in focus, I could inscribe an adequately comprehensible hand.

(Not the first attempt.)
Dotting and crossing
There’s a message in the media just above. I discovered that one reason my writing was so terrible was lacking enough patience to revisit the i’s and t’s after finishing a word that contains them, but rather trying to dot and cross as I went along. Enforcing a steely “finish the word, then go back” discipline on myself seems the single most important factor in getting a coherent writing line.
I’ve made the point this blog piece wants to make, but learned a few things about the subject along the way.
Wikipedia?
It says penmanship means simply the practice of inscribing text by hand (cursive is the subclass of penmanship where “characters are written joined in a flowing manner”). But I and the OED both think that English word also also commonly refers to the quality of writing. So I think that entry needs work.

Oh, and “Penmanship” also stands for Tommaso Ciampa the professional wrestler; earlier in his career he fought as “Tommy Penmanship”. I confess I offer this tasty fact just so I could include his picture.
Pop culture?
As I inscribed to-buys on the family grocery list, going back to dot and cross, it occurred to me that “or” was difficult; the writing line leaves the small “o” at the top of the letter, but a small “r” wants to begin on the baseline. I addressed this conundrum, as one does, by visiting YouTube. And thus discovered that a whole lot of people care about this stuff; there are, of course, /r/Cursive and /r/Handwriting.
Which sort of makes sense in a time when LPs and film photography are resurging. I think there are deep things to be thought and (not necessarily hand-)written about the nature of a message inscribed in cursive, even when that cursive is described in pixels. But I’m not going there today. I’m just saying I can read my grocery lists now.
Trollope’s aristos
I distinctly recall reading, in one of Anthony Trollope’s excellent novels about mid-19th-century life, that it was common knowledge that the landed aristocracy heedlessly wrote in incomprehensible chicken-scratches, but that the clerks and scriveners and merchants, the folk lacking genealogy, were expected to have a clear hand.
The new hotness?
I dunno, I don’t really think cursive is, but the idea isn’t crazy.
Voting Green October 19th 15 Oct 2024, 9:00 pm
I’m old enough that I remember voting in the Seventies. I never miss a chance to vote so that’s a lot of elections. In all but one or two my vote has gone to the NDP, Canada’s social democrats. There’s a provincial election Saturday, and I’ll be voting Green, against the current NDP government.
It’s not complicated: I’ve become a nearly-single-issue voter. The fangs of the climate monster are closing on us, and drastic immediate action is called for by all responsible governments to stave them off.
The BC NDP has followed its unlamented right-wing predecessor in making a huge energy bet on fossil fuels, “natural” gas in particular, and especially LNG, optimized for export. “Natural” gas, remember, is basically methane. The fossil-fuels mafia has greenwashed it for years as a “better alternative”, and a “bridge to the renewable future”. Which is a big fat lie; it’s been known for years to be a potent greenhouse gas, and recent research suggests it’s more damaging than coal.
Tilbury
That was the LNG project that made me snap. Here is coverage that tries to be neutral. Tilbury was sold as being a good thing because LNG is said to have a lighter carbon load than the heavy bunker fuel freighters usually burn. Supposing that to be true, well so what: The terminal mostly exists to pump locally-extracted methane to the rest of the world. Check out Tilbury’s first contract, for 53,000 tons of LNG a year off to China, with no indication of what it will be used for and plenty of reason to believe it will end up heating buildings, which instead should be moving to renewable options.
Tilbury is just the latest chapter of the successful march of LNG infrastructure through the minds of successive BC governments; I’ll spare you the long, dispiriting story (but I won’t forget it in the polling booth).
I don’t believe it’s oversimplifying to say that essentially everything the fossil-fuel industry says is a pack of self-serving planet-destroying lies. Why would I vote for a party that apparently believes those lies?
The Carbon Tax
Post-Tilbury, I was probably 60% of the way to splitting with the NDP when they announced they were ready to drop the carbon tax. It is hard to find an economist who does not believe that a carbon tax is one of our sanest and most powerful anti-GHG policy tools. BC has been a North-American leader in instituting and maintaining a carbon tax. So, that sealed the deal. Bye bye, NDP.
What’s happening is simple enough: Canada’s right-wing troglodytes have united around an anti-Carbon-tax platform, chanting “axe the tax”. And our NDP has waved the chickenshit-colored tag of surrender. You can pander to reactionary hypocrites, or you can help us do our bit for the world my children will inherit, but you can’t do both. Bye.
The Greens
Their platform is the kind of sensible social-democratic stuff that I’ve always liked, plus environmentalist to the core. Leader Sonia Furstenau is impressive. It wasn’t a hard choice.
But tactical voting!
It’s been a weird election, with the official opposition party, center-rightists who long formed the government, changing their name (from “Liberals” to “United”) midstream, then collapsing. This led to the emergence of the BC Conservative Party, a long-derided fringe organization famous for laughable candidates, thick with anti-vaxxers, climate deniers, anti-wokesters, anti-LGBTQ ranters, and multiple other flavors of conspiracy connoisseur.
Guess what: That’s what they still are! But much to everyone’s surprise, they’re running pretty close to neck and neck with the NDP.
So people like me can expect to be told that by abandoning the NDP, we’re in effect aiding and abetting the barbarians at the gate. (To be fair, nobody has actually said that to me. The strongest I’ve heard is “it’s your privilege to waste your vote.”)
But what I see is two parties neither of which have any concern for my children’s future, and one which does. If it’s wrong to vote on that basis, I don’t want to be right.
Unbackslash 22 Sep 2024, 9:00 pm
Old software joke: “After the apocalypse, all that’ll be left will be cockroaches, Keith Richards, and markup characters that have been escaped (or unescaped) one too many (or few) times.” I’m working on a programming problem where escaping is a major pain in the ass, specifically “\”. So, for reasons that seem good to me, I want to replace it. What with?
The problem
My
Quamina project is all about matching patterns (not going into any further
details here, I’ve
written this one to death). Recently, I implemented a “wildcard”
pattern, that works just like a shell glob, so
you can match things like *.xlsx or invoice-*.pdf. The only metacharacter is *, so it
has basic escaping, just \* and \\.
It wasn’t hard to write the code, but the unit tests were a freaking nightmare, because
\. Specifically, because Quamina’s patterns are wrapped in JSON, which also uses \ for escaping, and
I’m coding in Go, which does too, differently for strings delimited by " and
`. In the worst case, to test whether \\ was handled properly, I’d have \\\\\\\\
in my test code.
It got to the point that when a test was failing, I had to go into the debugger to figure out what eventually got
passed to the library code I was working on. One of the cats jumped up on my keyboard while I was beset with \\\\
and found itself trying to tread air. (It was a short drop onto a soft carpet. But did I ever get glared at.)
Regular expressions ouch
That’s the Quamina feature I’ve just started working on. And as everyone knows, they use \ promiscuously. Dear
Reader, I’m going to spare you the “Sickening Regexps I Have Known” war stories. I’m sure you have your
own. And I bet they include lots of \’s.
(The particular dialect of regexps I’m writing is I-Regexp.)
I’ve never implemented a regular-expression processor myself, so I expect to find it a bit challenging. And I expect to have
really a lot of unit tests. And the prospect of wrangling the \’s in those tests is making me
nauseous.
I was telling myself to suck it up when a little voice in the back of my head piped up “But the people who use this library will be writing Go code to generate and test patterns that are JSON-wrapped, so they’re going to suffer just like you are now.”
Crazy idea
So I tried to adopt the worldview of a weary developer trying to unit-test their patterns and simultaneously fighting JSON
and Go about what \\ might mean. And I thought “What if I used some other character for escaping in the regexp? One
that didn’t have special meanings to multiple layers of software?”
“But that’s crazy” said the other half of my brain. Everyone has been writing things like \S+\.txt and
[^{}[\]]+ for years and just thinks that way. Also, the Spanish Inquisition.”
Whatever; like Prince said, let’s go crazy.
The new backslash
We need something that’s visually distinctive, relatively unlikely to appear in common regular expressions, and not too hard for a programmer to enter. Here are some candidates, in no particular order.
For each, we’ll take a simple harmless regexp that matches a pair of parentheses containing no line breaks, like so:
Original: \([^\n\r)]*\)
And replace its \‘s with the candidate to see what it looks like:
Left guillemet: «
This is commonly used as open-quotation in non-English languages, in particular French. “Open quotation” has a good semantic
feel; after all, \ sort of ”quotes” the following character.
It’s visually pretty distinctive. But it’s hard to type on keyboards not located in Europe. Speaking of developers sitting
behind those keyboards, they’re more likely to want to use « in a regexp. Hmm.
Sample: «([^«n«r)]*«)
Em dash: —
Speaking of characters used to begin quotes, Em dash seems visually identical to U+2015 QUOTATION DASH, which I’ve often seen as a quotation start in English-language fiction. Em dash is reasonably easy to type, unlikely to appear much in real life. Visually compelling.
Sample: —([^—n—r)]*—)
Left double quotation mark: “
(AKA left smart quote.) So if we like something that suggests an opening quote, why not just use an opening quote? There’s a key combo to generate it on most people’s keyboards. It’s not that likely to appear in developers’ regular expressions. Visually strong enough?
Sample: “([^“n“r)]*“)
Pilcrow: ¶
Usually used to mark a paragraph, so no semantic linkage. But, it’s visually strong (maybe too strong?) and has combos on many keyboards. Unlikely to appear in a regular expression.
Sample: ¶([^¶n¶r)]*¶)
Section sign: §
Once again, visually (maybe too) strong, accessible from many keyboards, not commonly found in regexps.
Sample: §([^§n§r)]*§)
Tilde: ~
Why not? I’ve never seen one in a regexp.
Sample: ~([^~n~r)]*~)
Escaping
Suppose we used tilde to replace backslash. We’d need a way to escape tilde when we wanted it to mean itself.
I think just
doubling the magic character works fine. So suppose you wanted to match anything beginning with . in my home
directory: ~~timbray/~..*
“But wait,” you cry, “why are any of these better than \?” Because there aren’t other layers of software fighting to
interpret them as an escape, it’s all yours.
You can vote!
I’m going to run a series of polls on Mastodon. Get yourself an account anywhere in the Fediverse and follow the
#unbackslash hashtag. Polls will occur on Friday September 27, in reasonable Pacific times.
Of course, one of the options will be “Don’t do this crazy thing, stick with good ol’ \!”
New Amplification 9 Sep 2024, 9:00 pm
The less interesting part of the story is that my big home stereo has new amplification: Tiny Class-D Monoblocks! (Terminology explained below.) More interesting, another audiophile tenet has been holed below the waterline by Moore’s Law. This is a good thing, both for people who just want good sound to be cheaper, and for deranged audiophiles like me.
Tl;dr
This was going to be a short piece, but it got out of control. So, here’s the deal: Audiophiles who love good sound and are willing to throw money at the problem should now throw almost all of it at the pure-analog pieces:
Speakers.
Listening room setup.
Phono cartridge (and maybe turntable) (if you do LPs).
What’s new and different is that amplification technology has joined D-to-A conversion as a domain where small, cheap, semiconductors offer performance that’s close enough to perfect to not matter. The rest of this piece is an overly-long discussion of what amplification is and of the new technology.

The future of amplifiers looks something like this; more below.
What’s an “amp”?
A stereo system can have lots of pieces: Record players, cartridges, DACs, volume and tone controls, input selectors, and speakers. But in every system the last step before the speakers is the “power amplifier”; let’s just say “amp”. Upstream, music is routed round the system, not with electrical currents, but by a voltage signal, we say “line level”. That is to say, the voltage vibrates back and forth, usually between +/-1V, the vibration pattern being that of the music, i.e. that of the sound-wave vibrations you want the speakers to produce in the air between them and your ears.
Now, it takes a lot more than +/-1V to make sound come out of speakers. You need actual electrical current and multiple watts of energy to vibrate the electromagnets in your speakers and generate sound by pushing air around, which will push your eardrums around, which sends data to your brain that results in the experience of pleasure. If you have a big room and not-terribly-efficient speakers and are trying to play a Mahler symphony really loud, it can get into hundreds of watts.
So what an amp does take the line-level voltage signal and turn it into a corresponding electric-current signal with enough oomph behind it to emulate the hundred or so musicians required for that Mahler.
Some speakers (subwoofers, sound bars) come with amps built in, so you just have to send them the line-level signal and they take care of the rest. But in a serious audiophile system, your speakers are typically passive unpowered devices driven through speaker wires by an amp.
Historically, high-end amps have often been large, heavy, expensive, impressive-looking devices. The power can come either from vacuum tubes or “solid-state” circuits (basically, transistors and capacitors). Vacuum tubes are old technology and prone to distortion when driven too hard; electric-guitar amps do this deliberately to produce cool snarly sounds. But there are audiophiles who love tube amps and plenty are sold.
Amps come in pairs, one for each speaker, usually together in a box called a “stereo amplifier”. Sometimes the box also has volume and tone controls and so on, in which case it’s called an “integrated amplifier”.
So, what’s new?

TPA3255
This thing, made by Texas Instruments, is described as a “315-W stereo, 600-W mono, 18 to 53.5V supply, analog input Class-D audio amplifier”. It’s tiny: 14x6.1mm! It sort of blows my mind that this little sliver of semiconductor can serve as the engine for the class of amps that used to weigh 20kg and be the size of a small suitcase. Also that it can deliver hundreds of watts of power without vanishing in a puff of smoke.
Also, it costs less than $20, quantity one.
It’s not that new, was released in 2016. It would be wrong to have expected products built around it to arrive right away. I said above that the chip is the engine of an amplifier, and just like a car, once you have an engine there’s still lots to be built. You have to route the signal and power to the chip — and this particular chip needs a lot of power. You have to route the chip output to the speaker connection, and you have to deal with the fact that speakers’ impedences (impedance is resistance, except for alternating rather than direct current) vary with audio frequency in complicated ways.
Anyhow, to make a long story short, in the last couple of years there have started to be TPA3255-based amps that are aimed at audiophiles, claiming a combination of high power, high accuracy, small size, and low price. And technically-sophisticated reviewers have started to do serious measurements on them and… wow. The results seem to show that the power is as advertised, and that any distortion or nonlinearity is way down below the sensitivity of human hearing. Which is to say, more or less perfect.
For example, check out the work of Archimago, an extremely technical high-end audio blogger, who’s been digging in deep on TPA3255-based amps. If you want to look at a lot of graphs most of which will be incomprehensible unless you’ve got a university education in the subject, check out his reviews of the AIYIMA A08 Pro, Fosi Audio TB10D, and Aoshida A7.
Or, actually, don’t. Below I’ll link to the measurements of the one I bought, and discuss why it’s especially interesting. (Well, maybe do have a quick look, because some of these little beasties come with a charming steampunk aesthetic.)
PWM
That stands for pulse-width modulation, the technique that makes Class-D amps work. It’s remarkably clever. You have the line-level audio input, and you also bring in a triangle-wave signal (straight lines up then back down) at a higher frequency, and you take samples at another higher frequency and if the audio voltage is higher than the sawtooth voltage, you turn the power on, and if lower, you turn it off. So the effect is that the louder the music, the higher the proportion of time the power is on. So you get current output that is shaped like the voltage input, only with lots of little square corners that look like high-frequency noise; an appropriate circuit filters out the high frequencies and reproduces the shape of the input wave with high accuracy.
If that didn’t make sense, here’s a decent YouTube explainer.
The explanation, which my understanding of practical electronics doesn’t go deep enough to validate, is that because the power is only ever on or off, no intermediate states are necessary and the circuit is super efficient therefore cheap.
Monoblocks
Most amps are “stereo amplifiers”, i.e. two amps in a box. They have to solve the problem of keeping the two stereo signals from affecting each other. It turns out the TPA3255 does this right on the chip. So the people who measure and evaluate these devices pay a lot of attention to “channel separation” and “crosstalk”. This has led to high-end audiophiles liking “monoblock” amps, where you have two separate boxes, one for each speaker. Poof! crosstalk is no longer an issue.
Enter Fosi
You may have noticed that you didn’t recognize any of the brand names in that list of reviews above. I didn’t either. This is because mainstream brands from North America, Europe, and Japan are not exactly eager to start replacing their big impressive high-end amps costing thousands of dollars with small, cheap TPA3255-based products at a tenth the price.
Shenzen ain’t got time for that. Near as I can tell, all these outfits shipping little cheap amps are down some back street off a back street in the Shenzen-Guanghzhou megalopolis. One of them is Fosi Audio.
They have a decent web site but are definitely a back-street Shenzen operation. What caught my attention was Archimago’s 2-part review (1, 2) of Fosi’s V3 Mono.
This is a monoblock power amp with some ludicrously high power rating that you can buy as a pair with a shared power supply for a super-reasonable price. They launched with a Kickstarter.
I recommend reading either or both of Archimago’s reviews to feel the flavor of the quantitative-audio approach and also for the general coolness of these products.
I’m stealing one of Archimago’s pictures here, to reveal how insanely small the chip is; it’s the little black/grey rectangle at the middle of the board.

And here is my own pair of V3 Monos to the right of the record player.

My own experience
My previous amp (an Ayre Acoustics V-5xe) was just fine albeit kinda ugly, but we’re moving to a new place and it’s just not gonna fit into the setup there. I was wrestling with this problem when Archimago published those Fosi write-ups and I was sold, so there they are.
They’re actually a little bit difficult to set up because they’re so small and the power supply is heavier than both amps put together. So I had a little trouble getting all the wires plugged in and arranged. As Archimago suggests, I used the balanced rather than RCA connectors.
Having said all that, once they were set up, they vanished, as in, if it weren’t for the space between the speakers where the old amp used to be, I wouldn’t know the difference. They didn’t cost much. They fit in. They sound good.
One concern: These little suckers get hot when I pump music through them for an extended time. I think I’m going to want to arrange them side-by-side rather than stacked, just to reduce the chances of them cooking themselves.
Also, a mild disappoinment: They have an AUX setting where they turn themselves on when music starts and off again after a few minutes of silence. Works great. But, per Archimago’s measurements, they’re drawing 10 watts in that mode, which seems like way too much to me, and they remain warm to the touch. So, nice feature, but I guess I’ll have to flick their switches from OFF to ON like a savage when I want to listen to music.
The lesson
Maybe you love really good sound. Most of you don’t know because you’ve probably never heard it. I’m totally OK with Sonos or car-audio levels of quality when it’s background music for cooking or cleaning or driving. But sitting down facing a quality high-end system is really a different sort of thing. Not for everyone, but for some people, strongly habit-forming.
If it turns out that if you’re one of those people, it’s now smart to invest all your money in your speakers, and in fiddling with the room where they are to get the best sound out of them. For amplification and the digital parts of the chain, buy cheap close-enough-to-perfect semiconductor products.
And of course, listen to good music. Which, to be fair, is not always that well-produced or well-recorded. But at least the limiting factor won’t be what’s in the room with you.
Standing on High Ground 8 Sep 2024, 9:00 pm
That’s the title of a book coming out October 29th that has my name on the cover. The subtitle is “Civil Disobedience on Burnaby Mountain”. It’s an anthology; I’m both an author and co-editor. The other authors are people who, like me, were arrested resisting the awful “TMX” Trans Mountain pipeline project.

Pulling together a book with 25 contributing authors is a lot of work! One of the contributions started out as a 45-minute phone conversation, transcribed by me. The others manifested in a remarkable melange of styles, structures, and formats.
Which is what makes it fun. Five of our authors are Indigenous people. Another is Elizabeth May, leader of Canada’s Green party. There is a sprinkling of university professors and faith leaders. There are two young Tyrannosauri Rex (no, really). And then there’s me, the Internet geek.
As I wrote then, my brush with the law was very soft; arrested on the very first day of a protest sequence, I got off with a fine. Since fines weren’t stopping the protest, eventually the arrestees started getting jail time. Some of the best writing in the book is the prison narratives, all from people previously unacquainted with the pointy end of our justice system.
Quoting from my own contribution:
Let me break the fourth wall here and speak as a co-editor of the book you are now reading. As I work on the jail-time narratives from other arrestees, alternately graceful, funny, and terrifying, I am consumed with rage at the judicial system. It is apparently content to allow itself to be used as a hammer to beat down resistance to stupid and toxic rent-seeking behaviour, oblivious to issues of the greater good. At no point has anyone in the judiciary looked in the mirror as they jailed yet another group of self-sacrificing people trying to throw themselves between TMX’s engine of destruction and the earth that sustains us, and asked themselves, Are we on the right side here?
Of necessity, the law is constructed of formalisms. But life is constructed on a basis of the oceans and the atmosphere and the mesh of interdependent ecosystems they sustain. At some point, the formalisms need to find the flexibility to favour life, not death. It seems little to ask.
We asked each contributor for a brief bio, a narrative of their experience, and the statement they made to the judge at the time of their sentencing. Our contributors being what they are, sometimes we instead got poems and music-theory disquisitions and discourse on Allodial title. Cartoons too!
Which, once again, is what makes it fun. Well, when it’s not rage-inducing. After all, we lost; they built the pipeline and it’s now doing its bit to worsen the onrushing climate catastrophe, meanwhile endangering Vancouver’s civic waters and shipping economy.

We got endorsements! Lots more on
the
Web site and book cover.
The effort was worthwhile, though. There is reason to hope that our work helped raise the political and public-image cost of this kind of bone-stupid anti-survival project to the point that few or no more will ever be built.
Along with transcribing and editing, my contribution to the book included a couple of photos and three maps. Making the maps was massively fun, so I’m going to share them here just because I can. (Warning: These are large images.);
The first appears as a two-page spread, occupying all of the left page and the top third or so of the right.
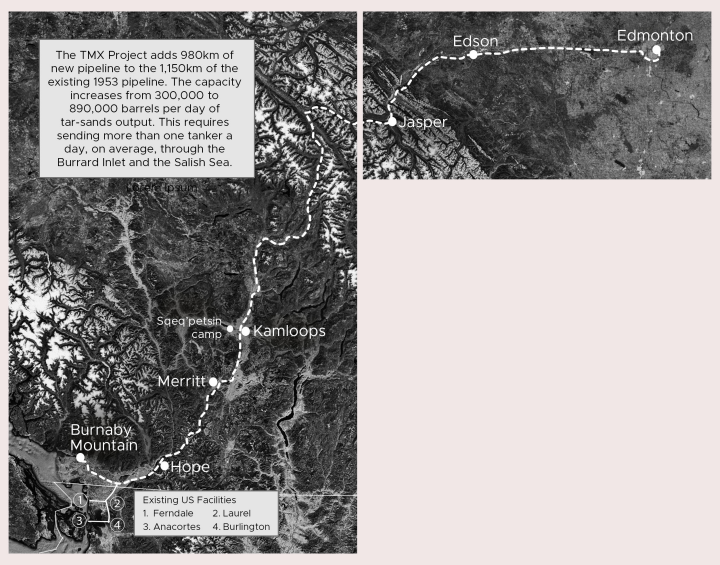
Then there’s a map of Vancouver and the Lower Mainland, highlighting the locations where much of the book’s action took place.
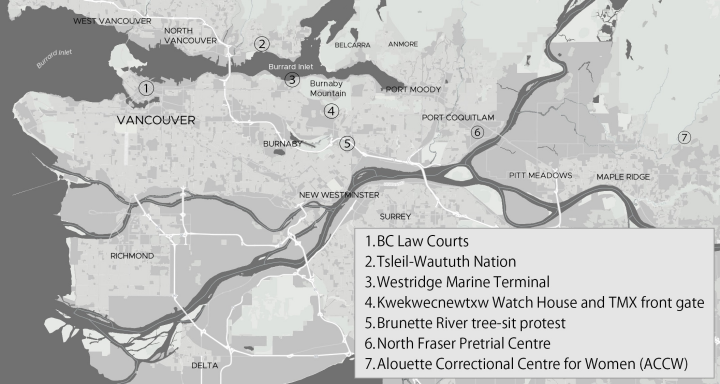
Finally, here’s a close-up of Burnaby Mountain, where TMX meets the sea, and where most of the arrests happened.

The credits say “Maps by Tim Bray, based on data from Google Maps, OpenStreetMap, and TMX regulatory filings.”
I suspect that if you’re the kind of person who finds yourself reading this blog from time to time, you’d probably enjoy reading Standing on High Ground. The buy-this-book link is here. If you end up buying a copy — please do — the money will go in part to our publisher Between The Lines, who seem a decent lot and were extremely supportive and competent in getting this job done. The rest gets distributed equally among all the contributors. Each contributor is given the option of declining their share, which makes sense, since some of us are highly privileged and the money wouldn’t make any difference; others can really use the dough.
What’s next?
We’re going to have a launch event sometime this autumn. I’ll announce it here and everywhere else I have a presence. There will be music and food and drink; please come!
What’s really next is the next big harebrained scheme to pad oil companies’ shareholders’ pockets by building destructive infrastructure through irreplaceable wilderness, unceded Indigenous land, and along fragile waterways. Then we’ll have to go out and get arrested again and make it more trouble than it’s worth. It wouldn’t take that many people, and it’d be nice if you were one of them.
I put in years of effort to stop the pipeline. Based on existing laws, I concluded that the pipeline was illegal and presented those arguments to the National Energy Board review panel. When we got to the moment on Burnaby Mountain when the RCMP advanced to read out the injunction to us, I was still acting in the public interest. The true lawbreakers were elsewhere.
[From Elizabeth May’s contribution.]
Thanks!
Chiefly, to our contributors, generous with their words and time, tolerant of our nit-picky editing. From me personally, to my co-editors Rosemary Cornell and Adrienne Drobnies; we didn’t always agree on everything but the considerable work of getting this thing done left nobody with hard feelings. And, as the book’s dedication says, to all those who went out and got arrested to try to convince the powers that be to do the right thing.
I’m going to close with a picture which appears in the book. It shows Kwekwecnewtxw (“Kwe-kwek-new-tukh”), the Watch House built by the Tsleil-Waututh Nation to oversee the enemy’s work, that work also visible in the background. If you want to know what a Watch House is, you’ll need to read the very first contribution in the book, which begins “Jim Leyden is my adopted name—my spirit name is Stehm Mekoch Kanim, which means Blackbear Warrior.”

0 dependencies! 4 Sep 2024, 9:00 pm
Here’s a tiny little done-in-a-couple-hours project consisting of a single static Web page and a cute little badge you can slap on your GitHub project.

The Web site is at 0dependencies.dev. The badge is visible on my current open-source projects, for example check out Topfew (you have to scroll down a bit).
Zero, you say?
In recent months I keep seeing these eruptions of geek angst about the fulminating masses of dependencies squirming under the surface of just about any software anyone uses for anything. The most recent, and what precipitated this, was Mike Perham’s Kill Your Dependencies.
It’s not just that dependencies are a fertile field for CVEs (*cough* xz *cough*) and tech debt, they’re also an enemy of predictable performance.
Also, they’re unavoidable. When you take a dependency, often you’re standing on the shoulders of giants. (Unfortunately, sometimes you’re standing in the shoes of clowns.) Software is accretive and it’s a good thing that that’s OK because it’s also inevitable.
In particular, don’t write your own crypto, etc. Because in software, as in life, you’re gonna have to take some dependencies. But… how about we take less? And how about, sometimes we strive for zero?
The lower you go
… the closer you are to zero. So, suppose you’re writing library code. Consider these criteria:
It’s low-level, might be useful to a lot of apps aimed at entirely different goals.
Good performance is important. Actually, let me revise that: predictably good performance is important.
Security is important.
If you touch all three of these bases, I respectfully suggest that you try to earn this badge: ⓿ ⓿ dependencies! dependencies! (By the way, it’s cool that I can toss a chunk of SVG into my HTML and it Just Works. And, you can click on it.)
How to?
First, whatever programming language you’re in, try to stay within the bounds of what comes with the language. In Go, where I
live these days, that means your go.sum file is empty. Good for you!
Second, be aggressive. For example, Go’s JSON support is known to be kind of slow and memory-hungry. That’s OK because there are better open-source options. For Quamina, I rejected the alternatives and wrote my own JSON parser for the hot code path. Which, to be honest, is a pretty low bar: JSON’s grammar could be inscribed on a grain of rice, or you can rely on Doug Crockford’s JSON.org.
So, get your dependencies to zero and display the badge proudly. Or if you can’t, think about each of your dependencies. Does each of them add enough value, compared to you writing the code yourself? In particular, taking a dependency on a huge general-purpose library for one small simple function is an antipattern.
What are you going to do, Tim?
I’m not trying to start a movement or anything. I just made a badge, a one-page website, and a blog post.
If I were fanatically dedicated, 0dependencies.dev would be database-backed with a React front-end and multiple
Kubernetes pods, to track bearers of the badge. Uh, no.
But, I’ll keep my eyes open. And if any particularly visible projects that you know about want to claim the badge, let me know and maybe I’ll start a 0dependency hall of fame.
Long Links 2 Sep 2024, 9:00 pm
It’s been a while. Between 2020 and mid-2023, I wrote pretty regular “Long Links” posts, curating links to long-form pieces that I thought were good and I had time to read all of because, unlike my readers, I was lightly employed. Well, then along came my Uncle Sam gig, then fun Open Source with Topfew and Quamina, then personal turmoil, and I’ve got really a lot of browser tabs that I thought I’d share one day. That day is today.
Which is to say that some of these are pretty old. But still worth a look I think.
True North Indexed
Let’s start with Canadian stuff; how about a poem? No, really, check out Emergency Exit, by Kayla Czaga; touched me and made me smile.
Then there’s Canada Modern, from which comes the title of this section. It’s an endless scroll of 20th-century Canadian design statements. Go take it for a spin, it’s gentle wholesome stuff
Renaissance prof
uses this has had a pretty good run since 2009; I quote: “Uses This is a collection of nerdy interviews asking people from all walks of life what they use to get the job done.” Older readers may find that my own May 2010 appearance offers a nostalgic glow.
Anyhow, a recent entry covers “Robert W Gehl, Professor (Communication and Media Studies)”, and reading it fills me with envy at Prof. Gehl’s ability to get along on the most pristine free-software diet imaginable. I mean, I know the answer: I’m addicted to Adobe graphics software and to Apple’s Keynote. No, wait, I don’t give that many conference talks any more and when I do, I rely on preloaded set of browser tabs that my audience can visit and follow along.
If it weren’t for that damn photo-editing software. Anyhow, major hat-tip in Prof. Gehl’s direction. Some of you should try to be more like him. I should too.
Now for some tech culture.
Consensus
The IETF does most of the work of nailing down the design of the Internet in sufficient detail that programmers can read the design docs and write code that interoperates. It’s all done without voting, by consensus. Consensus, you say? What does that mean? Mark Nottingham (Mnot for short) has the details. Consensus in Internet Standards doesn’t limit its discussion to the IETF. You probably don’t need to know this unless you’re planning to join a standards committee (in which case you really do) but I think many people would be interested in how Internet-standards morlocks work.
More Mnot
Check out his Centralization, Decentralization, and Internet Standards The Internet’s design is radically decentralized. Contemporary late-capitalist business structures are inherently centralized. I know which I prefer. But the tension won’t go away, and Mnot goes way deep on the nature of the problem and what we might be able to do it.
For what it’s worth, I think “The Fediverse” is a good answer to several of Mnot’s questions.
More IETF
From last year, Reflections on Ten Years Past the Snowden Revelations is a solid piece of work. Ed Snowden changed the Internet, made it safer for everyone, by giving us a picture of what adversaries did and knew. It took a lot of work. I hope Snowden gets to come home someday.
Polling Palestinians
We hear lots of stern-toned denunciations of the Middle East’s murderers — both flavors, Zionist and Palestinian — and quite a variety of voices from inside Israel. But the only Palestinians who get quoted are officials from Hamas or the PLA; neither organization has earned the privilege of your attention. So why not go out and use modern polling methodology to find out what actual Palestinians think? The project got a write-up in the New Yorker: What It Takes to Give Palestinians a Voice. And then here’s the actual poll, conducted by the “Palestinian Center for Policy and Survey Research”, of which I know nothing. Raw random data about one of the world’s hardest problems.
Music rage
Like music? Feel like a blast of pure white-hot cleansing rage? Got what you need: Same Old Song: Private Equity Is Destroying Our Music Ecosystem. I mean, stories whose titles begin “Private equity is destroying…” are getting into “There was a Tuesday in last week” territory. But this one hit me particularly hard. I mean, take the ship up and nuke the site from orbit. It’s the only way to be sure.
Movies too
Existentially threatened by late capitalism, I mean. Hollywood’s Slo-Mo Self-Sabotage has the organizational details about how the biz is eating its seed corn in the name of “efficiency”.
I’m increasingly convinced that the whole notion of streaming is irremediably broken; these articles speak to the specifics and if they’re right, we may get to try out new approaches after the streamers self-immolate.
A target for luck
I’ve mostly not been a fan of Paul Graham. Like many, I was impressed by his early essays, then saddened as he veered into a conventional right-wing flavor that was reactionary, boring, and mostly wrong. So these days, I hesitate to recommend his writing. Having said that, here’s an outtake from How To Do Great Work:
When you read biographies of people who've done great work, it's remarkable how much luck is involved. They discover what to work on as a result of a chance meeting, or by reading a book they happen to pick up. So you need to make yourself a big target for luck, and the way to do that is to be curious. Try lots of things, meet lots of people, read lots of books, ask lots of questions.
Amen. And the humility — recognition that good outcomes need more than brains and energy — is not exactly typical of the Bay-Aryan elite, and is welcome. And there’s other thought-provoking stuff in there too, but the tone will put many off; the wisdom is dispensed with an entire absence of humility, or really any supporting evidence. And that title is a little cringey. Could have been shorter, too.
“readable, writerly web layouts”
Jeffrey Zeldman asks who will design them. It’s mostly a list of links to plausible candidates for that design role. Year-old links, now, too. But still worth grazing on if you care about this stuff, which most of us probably should.
Speaking of which, consider heather buchel’s Just normal web things. I suspect that basically 100% of the people who find their way here will be muttering FUCK YEAH! at every paragraph.
Enshittification stanzas
(My oldest tabs, I think.) I’m talking about Ellis Hamburger’s Social media is doomed to die and Cat Valente’s Stop Talking to Each Other and Start Buying Things: Three Decades of Survival in the Desert of Social Media, say many of the same things that Cory is. But with more personal from-the-inside flavor. And not without streaks of optimism.
Billionaires
It’s amazing how fast this word has become shorthand for the problem that an increasing number of people believe is at the center of the most important social pathologies: The absurd level of inequality that has has grown tumorously under modern capitalism. American billionaires are a policy failure doesn’t really focus on the injustice, but rather does the numbers, presenting a compelling argument that a society having billionaires yields little to no benefit to that society, and precious little to the billionaires. It’s sobering, enlightening, stuff.
Gotta talk about AI I guess
The “T” in GPT stands for “Transformation”. From Was Linguistic A.I. Created by Accident? comes this quote:
It’s fitting that the architecture outlined in “Attention Is All You Need” is called the transformer only because Uszkoreit liked the sound of that word. (“I never really understood the name,” Gomez told me. “It sounds cool, though.”)
Which is to say, this piece casts an interesting sidelight on the LLM origin story, starting in the spring of 2017. If you’ve put any study into the field this probably won’t teach you anything you don’t know. But I knew relatively little of this early history.
Visual falsehood
Everyone who’s taken a serious look at the intersection of AI and photography offered by the Pixel 9 has reacted
intensely. The terms applied have ranged from “cool” to “terrifying”. I particularly like Sarah Jeong’s
No one’s ready for this,
from which a few soundbites:
“These photographs are extraordinarily convincing, and they are all extremely fucking fake.”
“…the easiest, breeziest user interface for top-tier lies…”
“…the default assumption about a photo is about to become that it’s faked…”
“A photo, in this world, stops being a supplement to fallible human recollection, but instead a mirror of it.”
We are fucked.
And that’s just the words; the picture accompanying the article are a stomach-churning stanza of visual lies.
Fortunately, I’m not convinced we’re fucked. But Google needs to get its shit together and force this AI voodoo to leave tracks, be transparent, disclose what it’s doing. We’re starting to have the tools, in particular a thing called C2PA on which I’ve had plenty to say.
Specifically, what Google needs to do is, when someone applies an AI technique to produce an image of something that didn’t happen, write a notification that this is the case into the picture’s EXIF and include that in the C2PA-signed manifest. And help create a culture where anything that doesn’t have a verifiable C2PA-signed provenance trail should be presumed a lie and neither forwarded nor reposted nor otherwise allowed to continue on its lying path.
Fade out
Here’s some beautifully performed and recorded music that has melody and integrity and grace: The Raconteurs feat. Ricky Skaggs and Ashley Monroe - Old Enough.
I wish things were a little less hectic. Because I miss having the time for Long Links.
Let’s all do the best we can with what we have.
Q Numbers Redux Explained 31 Aug 2024, 9:00 pm
[The first guest post in some years. Welcome, Arne Hormann!]
Hi there, I'm Arne. In July, I stumbled on a lobste.rs link (thanks, Carlana) that led me to Tim’s article on Q Numbers. As I'm regularly working with both floating point numbers and Go, the post made me curious — I was sure I could improve the compression scheme. I posted comments. Tim liked my idea and challenged me to create a PR. I did the encoding but felt overwhelmed with the integration. Tim took over and merged it. And since v1.4.0 released in August 28th, it's in Quamina.
In Tim’s post about that change, he wrote “Arne explained to me how it works in some chat that I can’t find, and to be honest I can’t quite look at this and remember the explanation”. Well, you're reading it right now.
Float64
Let's first talk about the data we are dealing with here. Quamina operates on JSON. While no JSON specification limits
numbers to
IEEE 754 floating point (Go calls
them float64),
RFC 8259 recommends treating them as such.
They look like this:
1 bit sign; 0 is positive, 1 is negative.
11 bits exponent; It uses a bias of
1023((1<<10)-1), and all exponent bits set means Infinity or Not a Number (NaN)1 mantissa high bit (implicit, never stored:
0if all exponent bits are0, otherwise1). This is required so there's exactly one way to store each number.52 explicit mantissa bits. The 53 mantissa bits are the binary digits of the number itself.
Both 0 and -0 exist and are equal but are represented differently. We have to normalize -0 to 0 for comparability,
but according to Tim’s tests, -0 cannot occur in Quamina because JSON decoding silently converts -0 to 0.
With an exponent with all bits set, Infinity has a mantissa of 0. Any other mantissa is NaN. But both sign values are
used. There are a lot of different NaNs; 1<<53 - 2 different ones!
In JSON, Infinity and NaN are not representable as numbers, so we don't have to concern ourselves with them.
Finally, keep in mind that these are binary numbers, not decimals. Decimal 0.1 cannot be accurately encoded. But 0.5
can. And all integers up to 1<<53, too.
Adding numbers to Quamina
Quamina operates on UTF-8 strings and compares them byte by byte. To add numbers to it, they have to be bytewise-comparable and all bytes have to be valid in UTF-8.
Given these constraints, let's consider the problem of comparability, first.
Sortable bits
We can use math.Float64bits() to convert a float64 into its individual bits (stored as uint64).
Positive numbers are already perfectly sorted. But they are smaller than negative numbers. To fix that, we always flip the
sign bit so it's 1 for positive and 0 for negative values.
Negative values are sorted exactly the wrong way around. To totally reverse their order, we have to flip all exponent and mantissa bits in addition to the sign bits.
A simple implementation would look like:
func numbitsFromFloat64(f float64) numbits {
u := math.Float64bits(f)
if f < 0 {
return numbits(^u)
}
return numbits(u) | (1 << 63)
}
Now let's look at the actual code:
func numbitsFromFloat64(f float64) numbits {
u := math.Float64bits(f)
mask := (u>>63)*^uint64(0) | (1 << 63)
return numbits(u ^ mask)
}The mask line can be a bit of a headscratcher...
u>>63moves the sign bit of the number to the lowest bitthe result will be
0for positive values and1for negative valuesthat's multiplied with
^0- all 64 bits set to truewe now have
0for positive numbers and all bits set for negative numbersregardless, always set the sign bit with
| (1 << 63)
By xoring mask to the original bits, we get our transformation for lexically ordered numbers.
The code is a bit hard to parse because it avoids branches for performance reasons.
Sortable bytes
If we were to use the uint64 now, it would work out great. But it has to be split into its individual bytes. And on little endian systems - most of the frequently used ones - the byte order will be wrong and has to be reversed. That's done by storing the bytes in big endian encoding.
UTF-8 bytes
Our next problem is the required UTF-8 encoding. Axel suggested to only use the lower 7 bits. That means we need up to 10 byte instead of 8 (7*10 = 70 fits 8*8 = 64).
Compress
The final insight was that trailing 0 bytes do not influence the comparison at all and can be dropped. Which compresses
positive power-of-two numbers and integers even further. Not negative values, though - the required bit inversion messes it
up.
And that's all on this topic concerning Quamina — even if there's so, so much more about floats.
Q Numbers Redux 28 Aug 2024, 9:00 pm
Back in July I wrote about Q numbers, which make it possible to compare numeric values using a finite automaton. It represented a subset of numbers as 14-hex-digit strings. In a remarkable instance of BDD (Blog-Driven Development, obviously) Arne Hormann and Axel Wagner figured out a way to represent all 64-bit floats in at most ten bytes of UTF-8 and often fewer. This feels nearly miraculous to me; read on for heroic bit-twiddling.
Numbits
Arne Hormann worked out how to rearrange the sign, exponent and mantissa that make up a float’s 64 bits into a big-endian integer that you probably couldn’t do math with but you can compare for equality and ordering. Turn that into sixteen hex digits and you’ve got automaton fuel which covers all the floats at the cost of being a little bigger.
If you want to admire Arne’s awesome bit-twiddling skills, look at numbits.go. He explained to me how it works in some chat that I can’t find, and to be honest I can’t quite look at this and remember the explanation.
u := math.Float64bits(f)
// transform without branching
// if high bit is 0, xor with sign bit 1 << 63,
// else negate (xor with ^0)
mask := (u>>63)*^uint64(0) | (1 << 63)
return numbits(u ^ mask)[Update: Arne wrote it up! See Q Numbers Redux Explained.]
Even when I was puzzled, I wasn’t worried because the unit tests are good; it works.
Arne called these “numbits” and wrote a nice complete API for them, although Quamina just needs .fromFloat64()
and .toUTF8().
I and Arne both thought he’d invented this, but then he discovered that the same trick was being used in the DB2 on-disk data
format years and years ago. Still, damn clever, and I’ve urged him to make numbits into a standalone library.
We want less!
We care about size; Among other things, the time an automaton takes to match a value is linear (sometimes worse) in its length. So the growth from 14 to 16 bytes made us unhappy. But, no problemo! Axel Wagner pointed out that if you use base-128, you can squeeze those 64 bits into ten usable bytes of UTF-8. So now we’re shorter than the previous iteration of Q numbers while handling all the float64 values…
But wait, there’s more! Arne noticed that for purposes of equality and comparison, trailing zeroes (0x0, not
‘0’) in those 10-byte strings
are entirely insignificant and can just be discarded. The final digit only has 1/128 chance of being zero, so maybe no big
deal. But it turns out that you do get dramatic trailing-0 sequences in positive integers, especially small ones,
which in my experience are the kinds of numbers you most often want to match. Here’s a chart of the length of the lengths the of
numbits-based Q numbers for the integers zero through 100,000 inclusive.
| Length | Count |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 115 |
| 4 | 7590 |
| 5 | 92294 |
They’re all shorter than 5 until you get to 1,000.
Unfortunately, none of my benchmarks prove any performance increase because they focus on corner cases and extreme numbers; the benefits here are to the world’s most boring numbers, namely small non-negative integers.
Here I am, well past retirement age, still getting my jollies from open-source bit-banging. I hope other people manage to preserve their professional passions into later life.
Mozart Requiem 25 Aug 2024, 9:00 pm
Vancouver has many choirs, with differing proficiency levels and repertoire choices. Most gather fall-to-spring and take the summer off. Thus, Summerchor, which aggregates a couple of hundred singers from many choirs to tackle one of the Really Big choral pieces each August. This year it was the Mozart Requiem. Mozart died while writing this work and there are many “completions” by other composers. Consider just the Modern completions; this performance was of Robert Levin’s.

Summerchor performs Mozart’s Requiem in
St.Andrews-Wesley United Church, August 24, 2024.
The 200 singers were assisted by four soloists, a piano, a trombone, the church’s excellent pipe organ, and finally, of course, by the towering arched space.
The combined power of Mozart’s music, the force of massed voices, and the loveliness of the great room yielded a entirely overwhelming torrent of beauty. I felt like my whole body was being squeezed.
Obviously, in an hour-long work, some parts are stronger than others. For me, the opening Requiem Aeternum and Kyrie hit hard, then the absolutely wonderful ascending line opening the Domine Jesu totally crushed me. But for every one of the three-thousand-plus seconds, I was left in no doubt that I was experiencing about as much beauty as a human being can.
God?
We were in a house of worship. The words we were listening to were liturgical, excerpted from Scripture. What, then, of the fact that I am actively hostile to religion? Yeah, I freely acknowledge that all this beauty I’m soaking up is founded on faith. Other people’s faith, of other times. The proportion of people who profess that (or any) faith is monotonically declining, maybe not everywhere, but certainly where I live.
Should I feel sad about that? Not really; The fact that architects and musicians worked for the Church is related to the fact that the Church was willing to pay. Musicians can manage without God, generally, as long as they’re getting paid.
The sound
We’ve been going out to concerts quite a lot recently so of course I’ve been writing about it, and usually discussing the sound quality too.
The sound at the Requiem was beyond awesome. If you look at the picture above you can see there’s a soundboard and a guy sitting at it, but I’m pretty sure the only boost was on the piano, which had to compete with 200 singers and the organ. So, this was the usual classical-music scenario: If you want dynamic range, or to hear soloists, or to blend parts, you do that with musical skill and human throats and fingers and a whole lot of practice. There’s no knob to twirl.
I mean, I love well-executed electric sound, but large-scale classical, done well, is on a whole other level.
Above, I mentioned the rising line at the opening of the Domine Jesu; the pulses, and the space between them, rose up in the endless vertical space as they rose up the scale, and yet were clearly clipped at start and end, because you don’t get that much reverb when the pews are full of soft human flesh and the roof is made of old wood, no matter how big the church is. I just don’t have words for how wonderful it sounded.
Classical?
Obviously, this is what is conventionally called “classical” music. But I’m getting a little less comfortable with that term, especially the connotation that it’s “music for old people” (even though I am one of those). Because so is rootsy rock music and bluegrass and Americana and GoGo Pengin and Guns N’ Roses.
Page processed in 0.296 seconds.
Powered by SimplePie 1.3.1, Build 20121030095402. Run the SimplePie Compatibility Test. SimplePie is © 2004–2024, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.