Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Onehouse opens up the lakehouse with Open Engines | InfoWorld
Technology insight for the enterpriseOnehouse opens up the lakehouse with Open Engines 17 Apr 2025, 8:31 pm
Data lake vendor Onehouse on Thursday released Open Engines, a new capability on its platform which it says provides the ability to deploy open source engines on top of open data.
Available in private preview, it initially supports Apache Flink for stream processing, Trino for distributed SQL queries for business intelligence and reporting, and Ray for machine learning (ML), AI, and data science workloads.
In a blog announcing Open Engines, Onehouse founder and CEO Vinoth Chandar wrote that while the industry “has made strides towards making data open with file formats … along with a budding renaissance of open data catalogs … we are still often restricted to closed compute because achieving open compute on open data is not as easy as it should be.”
“With Open Engines, Onehouse is now removing the final barrier to realizing a truly universal data lakehouse and finally flipping the defaults—for both data and compute—to open,” he wrote.
He also pointed out that no engine excels with all data workloads. For example, he said, the company’s deep dive blogs comparing analytics, data science and machine learning, and stream processing engines show that Apache Spark is “well-rounded, but not necessarily the best engine in any of these categories.”
A more modular approach
James Curtis, senior research analyst at S&P Global Market Intelligence, who specializes in data, AI and analytics, said, “my first impression of Open Engines is that this a good thing. With its carefully curated choice of engines, Onehouse is raising enterprise awareness that not every problem is a nail and not every solution is a hammer.”
One of the underlying benefits of the open file formats and open table formats, he said, has been that enterprises can mix and match different engines with the data, although he noted, “while that gives organizations choice, it still doesn’t completely address other data management challenge such as security and governance, let alone the added administrative work it takes to set up and maintain these environments.”
Onehouse addresses this potential added administrative burden by offering Open Engines as a managed service, said Curtis.
Usman Lakani, principal advisory director at Info-Tech Research Group, said that Open Engines, as part of an open lakehouse architecture, “introduces a more modular approach by breaking the Siamese connection between compute and storage.”
Organizations, he said, “would potentially no longer have to feel stuck using the data engine they initially thought would work. Rather, they would be enabled to adopt a ‘horses for courses’ approach, like having the option to select Presto for SQL-based analytics or Spark for more complex machine learning.”
Lakani added that this flexibility to scale compute without the constraints of data storage “is at least a game enhancer, if not a game changer. The use of open table formats like Apache Iceberg and Hudi ensures an organization’s data is not under proprietary lock and key and promotes interoperability, which is a crucial ingredient in an open, democratic, and decentralized data infrastructure.”
No one engine does everything well
Gaetan Castelein, chief marketing officer (CMO) at Onehouse, said the current problem revolves around the fact there is no single query engine that can best support all use cases and workloads, especially with the rise of machine learning, AI, and real time analytics. “If you go back 10 years, all of these platforms were basically supporting batch business intelligence,” he observed.
In addition, he said that while large organizations such as Uber and Walmart have installed and are using lakehouse offerings, mainstream enterprises, to a large extent, have not yet moved to them, because “today it requires building a via a do-it-yourself approach where you build your own, you cobble together a bunch of open source tools. If you have a deep engineering bench, you can do that. If you don’t have that deep engineering bench, that becomes very difficult.”
Kyle Weller, VP product at Onehouse, added that organizations currently face two challenges: “[They have] chosen a Databricks or Snowflake, and that dictates the rest of their architectural choices, or they are in a situation where they’re looking to open source, but that complexity of self managing is preventative from exploring multiple engines.”
Each engine has a unique specialty, he said, noting, “Flink was not invented for no reason. Flink was invented to address real time stream processing. Ray wasn’t invented just to be another item on the shelf. Ray was invented special purpose for AI use cases, ML use cases, data science.”
He added, “having the optionality or ability to bring these and match them to your use cases Is so critical. [Open Engines] is a one click deployment for Trino, Ray, and Flink clusters. This is our starting point. We’ll add more engines as we go.”
Getting value out of data
Info-Tech’s Lakani agreed. “In the marketplace of ideas and inventions, systems need to be flexible and not impose restrictions on enhancing the art of the possible,” he said. “Open-source software has always been at the forefront of this philosophy, and over the last two decades, closed business models used by the big names in the technology industry have slowly but steadily jumped on the bandwagon.”
However, he added, “this openness was primarily limited to software, leaving the capital-intensive hardware infrastructure in the gilded cage of vendor lock-in. People have to eat, and companies want to make profits — there’s no begrudging them this, but the sometimes unnecessarily complex conversations around available data tools we use overshadow the real source of value: our data. The release of Open Engines starts to chip away at this, and it’s about time.”
Curtis, meanwhile, said the “choice of engines is nothing new. The better question to ask is what does choice lead to? Complexity is usually the answer. Onehouse maintains that choice doesn’t necessarily require an extra administrative lift.”
He pointed out, “in an environment where alignment with one particular engine or table format is common, Onehouse’s approach is to provide an open platform that is more inclusive to different engines and table formats while also maintaining a focus on data as a first class citizen, which is ultimately where enterprises are challenged. That is, getting value out of their data.”
{kind=link}
Enter the parallel universe of Java’s Vector API 17 Apr 2025, 11:00 am
If there is one thing you can describe as an obsession for both developers and devops, it’s how to improve the performance of applications. Ultimately, better performance leads to lower costs (through reduced utilization of resources) or bigger profits (by delivering an improved service, thus attracting more customers).
Of course, there are many, many ways to improve performance, but one of the more obvious is to “divide and conquer.” Let’s say you have optimized your algorithms and upgraded your hardware, but you’re still not achieving the performance you need. The solution might lie deeper in the stack—at the CPU level—where vector operations can process multiple data points simultaneously. Being able to do more than one thing at a time will often (but not always) reduce how long it takes to complete a task.
The terms concurrent and parallel are often used interchangeably when discussing improving performance, so it’s worth explaining the difference between them.
Two tasks are said to execute concurrently if the second task starts executing after the first has started and before the first has finished. There is no requirement that, at any time, both tasks execute simultaneously. This technique has been used for a long time, especially in operating systems. Before the dawn of multi-core, multi-CPU machines, a single execution unit would have to be shared among all processes. To give the illusion that processes were running simultaneously, several would run concurrently and share the execution unit by swapping between them very quickly (this is called a time-sharing operating system).
For tasks to execute in parallel, they must execute simultaneously, not just overlap their execution.
How vector processing works
Moore’s law has squeezed more transistors into the same space. To extract more performance, we now have multi-core processors, which allow concurrent processes to execute in parallel. At a lower level, the CPU also contains hardware for parallel execution of specific types of tasks, which are referred to as vector operations.
Let’s say you have a set of numbers you want to process by applying the same operation to all of them. For example, all of the values need to be incremented by one. In Java, the typical way to handle this would be to store all your values in an array, create a loop to iterate over the array and add one to each value in the body of the loop. When you run a Java application, frequently used code will be compiled from the bytecodes of the virtual machine instruction set into native instructions. The JVM does this using a just-in-time (JIT) compiler.
The JIT is smart enough to understand the underlying processor architecture and will optimize the loop to use vector operations (this is called autovectorization).
Vector processing uses very wide registers to hold more than one value. For example, the AVX-2 Intel instructions make use of 256-bit wide registers. Java integers are stored in 32 bits, so each vector register can hold eight Java integers (ints). The JIT will generate code to load values from the array in groups of eight. The code can then use one of the AVX-2 instructions to tell the CPU to add one to each of these eight values independently (and deal with any overflow so neighboring values are not corrupted). This is true parallel processing since all values are processed in a single machine instruction cycle. The net effect is that processing the array takes only an eighth of the time to process as it does without autovectorization.
This all sounds wonderful and means that Java developers can code how they want and let the JIT compiler optimize for them at runtime.
Unfortunately, this is not the whole story…
Autovectorization works well for simple situations like the one just described. However, making the loop even slightly more complicated can quickly defeat the JIT compiler’s ability to improve performance in this way. If we add a simple conditional in the body of the loop to test whether the value should be incremented, the JIT will revert to using a sequential approach and not use vector operations.
Enter the Java Vector API
One solution to this is to allow Java developers to write code that is explicit about how vector operations should be used. The JIT compiler can translate this directly without the need for autovectorization. This is what the Java Vector API, introduced as an incubator module in JDK 16, is designed to do. Interestingly, this API holds the record for the longest incubating feature in OpenJDK, as it will be in its ninth iteration with the release of JDK 24. As an aside, this is not because it is in a perpetual state of flux but because it is part of a larger project, Valhalla. When Valhalla, which will add value types to Java, is delivered in the OpenJDK, the Vector API will become final.
The Vector API provides a comprehensive set of functionality. First, there are classes to represent each Java primitive numeric type as a vector. A vector species combines these primitive vector forms with CPU-specific registers, so it is simple to understand how to populate data from an array. Vectors can be manipulated using a rich set of operators. There are 103 of them, which cover everything you will realistically need.
The Vector API provides developers with everything they need to enable the JIT compiler to generate highly optimized code for numerically intensive operations. Since most things result in manipulating numbers (strings are, after all, just sequences of characters encoded to numbers), this can lead to significant performance improvements.
Ideally, the Vector API would not be required; autovectorization would handle this transparently. The good news is that high-performance JVMs include a different JIT compiler. The Falcon JIT compiler (which replaces the OpenJDK C2 JIT) is based on another open-source project, LLVM. This can recognize substantially more cases where vectors can be used, leading to better-performing applications without requiring code changes.
The Falcon JIT compiler is available in the Azul Platform Prime JDK, which is free for development and evaluation. As a TCK (Technology Compatibility Kit)-tested JDK, Azul Platform Prime is a drop-in replacement. Why not try it out with your applications?
Simon Ritter is deputy CTO and Java champion at Azul.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
Headlamp: A multicluster management UI for Kubernetes 17 Apr 2025, 11:00 am
As important as Kubernetes is to the modern cloud-native stack, it’s still not easy to use on your own hardware. That’s surprising, considering how long it’s been around. Sure, you can use managed cloud services such as Azure Kubernetes Service, but what’s needed is a common user interface that works not only with those cloud services but also with development systems and on-premises clusters.
The Kubernetes development team knows this is a problem, and its user interface special interest group, SIG-UI, has been working on a solution. This group runs two projects: Dashboard and Headlamp. Headlamp is a relatively new part of the core Kubernetes project, recently moving from its place in the CNCF’s Sandbox program. The transition was recently announced in Microsoft’s keynote slot at KubeCon+CloudNativeCon Europe 2025 in London.
Introducing Headlamp
Much of Headlamp comes from work done by Microsoft’s Kinvolk team in Germany, alongside both Flatcar’s container-optimized Linux and the Inspektor Gadget eBPF monitoring tool set. As Microsoft’s Andrew Randall noted at KubeCon, the project began when the team began thinking about how to deliver Kubernetes for the rest of us—the beginners and the Windows administrators—the people who expect an out-of-the-box experience.
If you’ve installed Kubernetes, even in a Minikube development environment, you know that you quickly have to get into the weeds of YAML and kubectl, even before using Helm to install necessary extensions and applications. It’s clear that some form of out-of-the-box experience is necessary just to get over that first hump.
That’s the intent behind Headlamp: to go from a standalone installation to a running Kubernetes environment in seconds, or to pick up your laptop, point it at a running Kubernetes environment, and start managing it.
Setting up Headlamp for the first time
I started by setting up a Minikube environment on a PC running Ubuntu 24.10. This was relatively simple to use Curl to download a binary release package from GitHub before running an install script. Some prerequisites are necessary. The system needs a container environment, and I installed KVM2 and Docker to ensure that this was ready for Minikube’s Kubernetes environment. It’s a good idea to have kubectl in place before you start, as you will need the Kubernetes command line to get everything working.
With Minikube running, I could now install Headlamp. There are several different installation options, but I chose Flatpak to install the full desktop application. You need to add Flatpak support if you’re not using a Red Hat Linux and then configure access to Kinvolk’s repository. Once installed, Headlamp adds an icon to your desktop launcher.
If you install via Flatpak and intend to use Headlamp with external tools, you must enable access through its sandbox. This is a single command and can be cut and pasted from the Headlamp documentation.
I also installed Headlamp on a Windows development PC. You can use the Winget tool to quickly install from a command line, or if you prefer Chocolatey, Headlamp is available in its repository. Both Winget and Chocolatey have their own update mechanisms, so you can keep your Headlamp installation current.
Headlamp isn’t only a desktop application; it can be installed in-cluster as a web application. This last option works well for teams with a central Kubernetes platform, but if you’re working with a development tool like Minikube, having a separate application allows you to quickly tear down and rebuild your environment without needing to reinstall Headlamp and any customizations every time.
Using Headlamp with Kubernetes
My Headlamp install on Linux quickly detected the Minikube install via Kubernetes’ config file and started to monitor and manage the cluster. The Cluster view is the heart of Headlamp. Here you can see all the clusters you’re managing, with the ability to filter by namespace. It gives you a good overview of resource usage: CPU, memory, and the number of nodes and pods in use. Cluster events can be filtered to show only warnings. Other filters let you drill down into specific namespaces to help track down issues in busy clusters.
Headlamp makes it easy to navigate through the various components that make up a Kubernetes cluster. Various views drill down into pods, deployments, and more. The Pod view shows what’s running, the resources each pod is using, and the internal IP address. You can see how old a pod is and when it last restarted. Click into a pod and you get details of its containers, any ports that are being used, as well as environment variables.
Other options quickly expose service YAML, using a built-in editor so you can make changes to your environment on the fly. There’s even a terminal so you can interact with a local shell inside your containers.
The more tools in your cluster, the more detail Headlamp exposes. If you’ve got Prometheus installed, it’ll show metrics, using its built-in plug-in. That’s one of the advantages of Headlamp: It’s built around an extensible architecture, which its community can use to add new features to work with the ever-growing Kubernetes environment. If a feature you need isn’t part of the default installation, simply search the Headlamp app catalog and install it with a couple of clicks.
Exploring application deployments
Perhaps the most useful feature is Headlamp’s application map. Starting with a view of the currently managed namespaces, you can drill into individual pods and deployments. Once you start viewing a deployment, you can see how it’s built up of ReplicaSets, pods, services, and endpoints. As you click into the map, you’re presented with more and more detail about how your application is put together and how it’s built on top of a selection of containers. You can use the tools here to forward ports so you can evaluate code, as well as explore how tools like Helm deploy code into your cluster.
It’s important to note that, as it’s dependent on the Kubernetes APIs, Headlamp isn’t only for Azure, and it’s been tested on most cloud providers’ versions as well as common on-premises and desktop development distributions. The underlying plug-in model is designed to help you quickly customize your installations and add links to your own specific tools. Plug-ins can link Headlamp to external applications and services, for example, integrating with a bug tracker.
If your plug-in needs to display information, Headlamp uses the Storybook component UI development tools, which help you make new visual components that work inside and alongside its own features. There are tips in the Headlamp documentation on how to make your code visually consistent.
Headlamp is still a young project and it does have some rough edges. I had some issues working with remote Kubernetes installs. Getting the right authentication tool in place required more platform engineering experience than I have, and although I made some progress setting up Keycloak as an OpenID Connect provider, I got bogged down. An alternate OIDC tool, Dex, may offer an easier route to a remote authentication platform, but I shall leave exploring that avenue for another day.
Eyes on K8s
Using Headlamp with a local development Kubernetes system was a lot easier, and it’s likely to quickly become an essential component of a cloud-native development stack. However, larger-scale deployments currently need significant Kubernetes platform experience to get the right configuration in place. With Headlamp now part of the Kubernetes project, ironing out complexity will likely be a high priority, hopefully making it easier to connect to a Kubernetes instance with the right roles and permissions and start working.
There’s a lot to like in Headlamp. It offers developers and platform engineers a clean, easy-to-understand user interface that exposes the complexity of a Kubernetes environment while helping you navigate not one, but many clusters. Multicluster support from a standalone application is, of course, the big win here, and why using it is preferable to Kubernetes’ other UI, Dashboard.
Thinking about Andrew Randall’s KubeCon aim for the project, is this an out-of-the-box tool for the rest of us? Not yet, but it shows a lot of promise. If anything, it’s reminiscent of classic Windows management tools such as System Center—and that’s a good thing.
{kind=link}
Gleam 1.10 improves compiler, JavaScript codegen 17 Apr 2025, 12:51 am
Gleam 1.10, a new release of the type-safe programming language for the Erlang virtual machine and JavaScript runtimes, is now available. The update features compiler improvements centering on holding more information and improving exhaustive analysis. Faster execution of JavaScript code also is highlighted.
Gleam 1.10 was introduced April 14; it is accessible on GitHub.
The compiler in this release retains more information about types and values and how they reference each other in Gleam programs, according to a blog posted by Gleam creator Louis Pilfold. This enables the language server included in the Gleam binary to provide a “find references” feature that enables developers to find where a type or value is used in a project. Also, the additional information has been used to improve the “rename” language server feature. Prior to this, only module-local types and values could be renamed. With the improvement, renaming can be performed across all project modules. Gleam’s builders also have improved the compiler’s unused-code detection, repairing some situations in which the compiler would fail in detecting all of the unused code.
Gleam 1.10 also improves the Gleam compiler’s exhaustiveness analysis with the inclusion of string pattern analysis. Previously, only rudimentary analysis was performed on strings, and unreachable strings could not be detected. Exhaustiveness analysis ensures that all possible variants of a value are handled in flow control and that there are no redundant cases that are not reachable due to previous cases. The compiler also now emits a warning when using let assert to assert a value whose variant already has been inferred.
Gleam 1.10 also features operator analysis improvements. The Gleam compiler is fault-tolerant; this means that when an error is found in code, the compiler does not stop immediately but shows the error to the programmer and makes a best effort to recover and continue analyzing the remaining code. Analysis of binary operators such as + and == has been improved so both sides will be checked even in the presence of errors. This can improve language server information and enables improved error messages.
Gleam 1.10 follows the March 8 release of Gleam 1.9, which offered improvements such as more powerful bit arrays on JavaScript. Other new features in Gleam 1.10:
- JavaScript code generation has been improved to make the code run faster. Where possible, the compiler restructures code to no longer use JavaScript “immediately invoked function expressions,” which removes the overhead of allocating and then calling these functions.
- With bit array improvements, developers now can omit the
:floatoption when used with float literals, as the intention is unambiguous. - The new
gleam export package-informationcommand will write information about a Gleam package to a file in JSON format. - The language server now can offer a code action to replace a
..in a pattern with all the fields that it was being used to ignore. - For security and compliance, Gleam’s container images now feature a software bill of materials (SBoM) and supply-chain levels for software artifacts (SLSA) provenance information. This will help with security audits and compliance of software written with Gleam. It is part of an effort to evidence production readiness and promote Gleam adoption within enterprise.
{kind=link}
The programming language wars 16 Apr 2025, 11:00 am
Microsoft recently decided to rewrite the TypeScript tool chain using Go. This has caused a stir as folks wonder why Microsoft chose the Go language instead of their own C# or even TypeScript itself. I have to say that it is a curious choice. The resulting discussion around “my language is better than your language” takes me back.
I learned to code using BASIC in the 1970s. BASIC had line numbers, and I remember hearing about this newfangled language called Pascal that didn’t have line numbers and I wondered how that was possible. How will you know where to GOTO?
Somewhat ironically, it was Pascal—first in the form of Turbo Pascal and then as Delphi—that launched my career in software development. I began programming as a hobby, but I loved it so much I turned away from a sweet Navy pension to become a professional developer. I did pretty well with it. I wrote books and blogs and eventually became the product manager for Delphi.
Death to Visual Basic
One of the nicknames Delphi had before its release (aside from the name Delphi itself) was VBK—Visual Basic Killer. At the time, most software development was Windows development, and VB was very popular with Windows developers, who liked VB’s visual development approach and the fact that it wasn’t C++.
Naturally, the name “VB Killer” raised the ire of the developers who used and liked VB. We upstarts—the Delphi fanbois—would love to go over to the VB forums and tell them, well, how Delphi was going to kill VB. Unsurprisingly, the VB fans took umbrage at this notion, and the language wars were on.
It got ugly. I mean, we hurled personal insults and argued ad nauseam about why our chosen language was better. I remember getting very, very worked up about it. It was personal for reasons that seemed desperately important. Naturally, that seems quite silly as I look back on it as a (hopefully) wiser and more mature person.
I think it’s interesting that these were two tools you had to pay for. These days, programming languages and most of the basic tools are free. Back in the 1990s, we all had to buy our development tools, and I think that spurred us to be vastly more defensive about our choice.
It is funny to look back and think that what language one chose to code in was so terribly important. I see similar disputes happening today, as you have JavaScript folks upset with TypeScript folks and Rust folks snubbing their noses at C++.
I finally came to realize that this is an endless debate. The systems, languages, and frameworks are so complex, and there are so many points to be made, that the discussion will never be settled and a final “correct answer” will never be arrived at. Just choose the language that you like, that works for you, and that you can use to get the job done.
There are teams all over the place succeeding with Java, C#, JavaScript, TypeScript, Pascal, C++, Rust, Python… I could go on for a very long time. So it seems that there isn’t a bad choice to be made. I guess if you tried to build a web application with GW-BASIC, you might run into some roadblocks. But there are myriad ways to build a web application these days and they all work. They all have strengths and limitations, and they all will drive you crazy and they all will give you moments of lovely zen as you realize their elegance.
Mostly right answers
In other words, there is no wrong answer, only right answers, and fighting over it is, well, silly. Just do what works for you and stay off the “other team’s” message boards.
To be fair, there are wrong answers. GW-BASIC probably isn’t a good choice for much of anything today, and I suspect a large enterprise isn’t going to bet the company on some upstart framework using Perl. But there are any number of obvious right answers—the venerable languages with huge and rich ecosystems—that you can’t go wrong picking one.
Language wars inevitably end up with people saying “Choose the right tool for the job.” Of course, that never seems to satisfy those diehards who think their tool is the right tool for every job. And “Choose the right tool for the job” does sound a bit trite, because why would anyone choose the wrong tool for the job? But ultimately, it’s solid advice.
I don’t know why Microsoft chose Go for their TypeScript rewrite. But I do know this: If Microsoft thought it was the best tool for the job, I’m not going to argue with them or anyone else about it.
{kind=link}
6 languages you can deploy to WebAssembly right now 16 Apr 2025, 11:00 am
WebAssembly, or Wasm, gives developers a way to create programs that run at near-native speed in the browser or anywhere else you can deploy the WebAssembly runtime. But you generally don’t write programs in Wasm directly. Instead, you write programs in other languages— some better suited to being translated to Wasm than others—and compile them with Wasm as the target.
These six languages (I count C and C++ as two) can all be deployed onto Wasm runtimes via different tooling, and with different degrees of ease and compatibility. If you want to explore using Wasm as a deployment target for your code, you’ll want to know how well-suited your language of choice is to running as Wasm. I’ll also discuss the level of work involved in each deployment.
Rust
In some ways, Rust is the language most well-suited to deploy to WebAssembly. Your existing Rust code doesn’t need to be modified a great deal to compile to Wasm, and most of the changes involve setting up the right compiler target and compilation settings. The tooling also automatically generates boilerplate JavaScript to allow the compiled Wasm modules to work directly with web pages.
The size of the compiled module will vary, but Rust can generate quite lean and efficient code, so a simple “Hello, world” generally doesn’t run more than a few kilobytes. Rust’s maintainers authored an entire guide to using Wasm from Rust, with details on how to keep the size of delivered binaries small and adding Wasm support to an existing, general-purpose Rust crate.
C/C++
C and C++ were among the first languages to compile to Wasm, in big part because many of the lower-level behaviors in those languages map well to Wasm’s instruction set. The early wave of Wasm demos were ports of graphics demonstrations and games written in C/C++, and those proof-of-concept projects went a long way toward selling Wasm as a technology. (Look! We can play Doom in the browser!)
One of the first tools developed to compile C/C++ to Wasm was the Emscripten toolchain. Emscripten has since become a full-blown toolchain for compiling C or C++ to Wasm—full-blown in the sense that it offers detailed instructions for porting code. SIMD (which is supported in Wasm), networking, C++ exceptions, asynchronous code, and many other advanced features can be ported to Wasm, although the amount of work varies by feature. Pthread support, for instance, isn’t enabled by default, and will only work in browsers when the web server has certain origin headers set correctly.
As of version 8 and up, the Clang C/C++ compiler can compile natively to Wasm with no additional tooling. However, Emscripten uses the same underlying technology as Clang—the LLVM compiler framework—and may provide a more complete toolset specifically for compilation.
Golang
The Go language added support for WebAssembly as a compilation target in version 1.11, way back in August 2018. Originally an experimental project, Wasm is now fairly well-supported as a target, with a few caveats.
As with Rust, most of the changes to a Go program for Wasm’s sake involve changing the compilation process rather than the program itself. The Wasm toolchain is included with the Go compiler, so you don’t need to install any other tooling or packages; you just need to change the GOOS and GOARCH environment variables when compiling. You will need to manually set up the JavaScript boilerplate to use Wasm-compiled Go modules, but doing this isn’t hard; it mainly involves copying a few files, and you can automate the process if needed.
The more complex parts of using Go for Wasm involve interacting with the DOM. The included tooling for this via the syscalls/js package works, but it’s awkward for anything other than basic interaction. For anything bigger, pick a suitable third-party library.
Another drawback of using Go with Wasm is the size of the generated binary artifacts. Go’s runtime means even a “Hello, world” module can be as much as two megabytes. You can compress Wasm binaries to save space, or use a different Go runtime, like TinyGo—although that option only works with a subset of the Go language.
JavaScript
It might seem redundant to translate JavaScript to Wasm. One of the most common destinations for Wasm is the browser, after all, and most browsers come with a JavaScript runtime built in. But it is possible to compile JavaScript to Wasm if you want to.
The most readily available tool for JavaScript-to-Wasm is Javy, created and supported by the Bytecode Alliance (a chief supporter of Wasm initiatives). Javy doesn’t so much compile JavaScript code to Wasm as execute it in a Wasm-based JavaScript runtime. It also uses a dynamic linking strategy to keep the resulting Wasm modules reasonably small, although the size will vary depending on the features used in your program.
Python
Python’s situation is like Go’s, but even more pronounced. You can’t run a Python program without the Python runtime, and it’s difficult to do anything useful without the Python standard library—to say nothing of the ecosystem of third-party Python packages. You can run Python by way of the Wasm runtime, but it’s clunky and bulky, and the current state of the tooling for Python-on-Wasm isn’t streamlined.
A common way to run Python applications through a Wasm runtime is Pyodide, a port of the CPython runtime to Wasm via Emscripten. One implementation of it, PyScript, lets you run Python programs in web pages, as per JavaScript. It also includes bidirectional support for communication between Python and the JavaScript/DOM side of things.
Still, Pyodide comes with multiple drawbacks. Packages that use C extensions (as an example, NumPy) must be ported manually to Pyodide to work. Only pure Python packages can be installed from PyPI. Also, Pyodide has to download a separate Wasm package for the Python runtime, which runs to a few megabytes, so it might be burdensome for those who aren’t expecting a big download potentially every time they use the language.
{kind=link}
JRuby 10 brings faster startup times 16 Apr 2025, 12:27 am
JRuby 10, the latest release of the Ruby language variant built atop the JVM, has arrived, bringing startup time improvements, support for Java 21, and compatibility with Ruby 3.4.
Release of JRuby 10 was announced April 14. JRuby 10 can be downloaded from jruby.org.
JRuby 10 offers up-to-date Ruby compatibility, support for modern JVM features, and a cleanup of internal code and external APIs, making it the most important JRuby release ever, according to JRuby core team member Charles Oliver Nutter.
With support for Java 21, the most recent long-term support version of Java, JRuby moves past Java 8 support and begins integration of Java 21 features. The JRuby team plans to bring 10 years of JVM enhancements to Ruby users. Addressing slow startup times, which has been called the number one complaint from JRuby users, JRuby 10 leverages newer JVM features including:
- Application class data store (AppCDS) – an OpenJDK feature that allows pre-caching code and metadata during startup to reduce the cost of future commands.
- Project CRaC (Coordinated Restore at Checkpoint) – an experimental feature that allows users to “checkpoint” a running process and launch multiple future processes by restoring that checkpoint.
- Project Leyden – an OpenJDK project to improve the startup time, time to peak performance, and footprint of Java programs. The JRuby team will incorporate Leyden flags into JRuby’s launcher as they become available.
These features, combined with the reduced overhead --dev flag, offer the fastest-ever startups for JRuby, Nutter said.
Compatibility with Ruby 3.4, meanwhile, has allowed the JRuby team to implement Ruby 3.2, Ruby 3.3, and Ruby 3.4 features in JRuby 10. The new JRuby release runs full invokedynamic optimization by default, providing the best available performance on JRuby scripts and applications without passing additional flags. Previous versions of JRuby ran by default in a “middle tier” of optimization, using invokeddynamic optimization only for simple Ruby operations.
JRuby can be deployed on Linux, macOS, Windows, and other platforms such as Solaris and BSD. Applications can be deployed alongside enterprise Java apps using Spring or Jakarta EE. Also, quick updates are planned to address last-minute issues. Developers can file bugs seen while testing JRuby 10 at a JRuby GitHub page.
{kind=link}
OpenAI GPT-4.1 models promise improved coding and instruction following 15 Apr 2025, 6:24 pm
OpenAI has announced a new family of models, GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano, which it says outperforms GPT-4o and GPT-4o mini “across the board.”
In conjunction with the launch of the GPT-4.1 family, OpenAI also announced that it is deprecating GPT-4.5 Preview in the API. GPT-4.5 Preview will be turned off completely on July 14, 2025, because GPT-4.1 offers similar or better performance for many functions at lower cost and latency, the company said.
OpenAI said that the new models have significantly larger context windows than their predecessors—one million tokens, compared to GPT-4o’s 128,000—and offer improved long-context comprehension. Output token limits have also been increased from 16,385 in GPT-4o to 32,767 in GPT-4.1.
However, GPT-4.1 will be available only via the API, not in ChatGPT. OpenAI explained that many of the improvements have already been incorporated into the latest version of GPT-4o, and more will be added in future releases.
OpenAI says it worked in close partnership with the developer community to optimize the models to meet their priorities. For example, it improved the coding score on SWE-bench verified by 21.4% over that of GPT-4o.
Better at coding and complex tasks
The company specifically touts the performance of the GPT-4.1 mini and GPT-4.1 nano models.
“GPT‑4.1 mini is a significant leap in small model performance, even beating GPT‑4o in many benchmarks. It matches or exceeds GPT‑4o in intelligence evals while reducing latency by nearly half and reducing cost by 83%,” the announcement said. “For tasks that demand low latency, GPT‑4.1 nano is our fastest and cheapest model available. It delivers exceptional performance at a small size with its 1 million token context window, and scores 80.1% on MMLU, 50.3% on GPQA, and 9.8% on Aider polyglot coding—even higher than GPT‑4o mini. It’s ideal for tasks like classification or autocompletion.”
These improvements, OpenAI said, combined with primitives such as the Responses API, will allow developers to build more useful and reliable agents that will perform complex tasks such as extracting insights from large documents and resolving customer requests “with minimal hand-holding.”
OpenAI also said that GPT-4.1 is significantly better than GPT-4o at tasks such as agentically solving coding tasks, front-end coding, making fewer extraneous edits, following diff formats reliably, ensuring consistent tool usage, and others.
It is also less expensive. The company said it costs 26% less than GPT-4o for median queries, and the prompt caching discount is increasing from 50% to 75%. Additionally, long context requests are billed at the standard per-token price. The models may also be used in OpenAI’s Batch API at an additional 50% discount.
Analysts raise questions
However, Justin St-Maurice, technical counselor at Info-Tech Research Group, is looking askance at some of the claims.
“This announcement definitely brings up some questions, especially when it comes to efficiency, pricing, and scale,” he said. “If the 83% cost reduction is true, it could be a big deal, especially with major enterprises and cloud providers looking closely at value per watt. That said, it doesn’t mention what baseline or model this is being compared to.”
But St-Maurice still thinks that, despite the price reduction, the models are premium offerings.
“OpenAI’s focus on long-context performance and more efficient variants like mini or nano aligns with current conversations around MCP [Model Context Protocol] servers and agentic systems,” he said. ”Being able to process up to a million tokens opens the door for more complex workflows and real-time reasoning, but the $2 per million input tokens and $8 per million output make it more of a premium offering, especially when compared to other options like Llama, which are increasingly being deployed for cost-sensitive inference at scale.”
That being the case, St-Maurice said, “if OpenAI can prove these cost and performance gains, then it will strengthen its position for efficient, scalable intelligence. However, for stronger enterprise adoption, they’ll need to be more transparent with practical benchmarks and pricing baselines.”
{kind=link}
Measuring success in dataops, data governance, and data security 15 Apr 2025, 11:00 am
Back in 2006, British mathematician Clive Humby stated that data was the new oil. Like oil, data isn’t useful in its raw state and must be refined, processed, and distributed to deliver value. Nearly 20 years later, business practices that have grown up around in this analogy include dataops automations used to integrate data; data governance to ensure accuracy, compliance, and usability; and data security to protect data from threats and breaches.
Executives and business leaders understand the importance of these three functions, especially as many organizations are adding genAI products to their digital transformation strategies and establishing AI governance as an essential guardrail.
I was recently asked how data and AI leaders should measure the effectiveness of their dataops, data governance, and data security practices. There is a growing perception that businesses are pouring money into AI with no clear metrics to determine whether the investment delivers business value and reduces risks.
Business leaders have many options to choose from, so I asked leaders to share what really works in practice. What metrics best reveal the value and effectiveness of dataops, data governance, and data security implementations?
Business value metrics
If you want business leaders to value investments in dataops, governance, and security, start with metrics that demonstrate the business value of reliable and timely data.
“Demonstrating business value requires CIOs to utilize KPIs that tie directly to the mission rather than traditional IT metrics that rarely resonate in the boardroom,” says Yakir Golan, CEO and co-founder of Kovrr. “Quantifying the benefits of technological initiatives, for instance, in financial terms, such as cost savings from automation or reduced risk exposure, effectively transforms the conversation into one that is more tangible at the executive level. For example, minimizing forecasted risk exposure by $2 million is much more powerful than IT ticket resolution rates.”
“Data effectiveness metrics CIOs can use include data ROI, similar to marketing attribution,” says Srujan Akula, CEO of The Modern Data Company. “Calculate specific data processing and storage costs against business value delivered and the time-to-insight.”
Measuring data ROI
Cost savings, risk reduction, and ROI tell an important story to business leaders about investment value. They are useful portfolio-level metrics when reviewing the aggregate of initiatives and platforms, but they may be difficult to capture on individual ones.
“The most telling KPI is often the simplest—how quickly can business teams access and act on trusted data,” says Pete DeJoy, SVP of products at Astronomer. “When you reduce that timeline from weeks to hours while maintaining security and governance standards, you create a compelling case for continued investment in dataops initiatives.”
Time to data
Time to data is a common metric used in dataops to measure any data processing and access delays. It’s an important metric for organizations that still have batch processing jobs running overnight to churn data, and today’s analytics only show yesterday’s or even older data.
Data trust
Another valuable metric, the data trust score can be a composite of business-relevant weightings of several indicators:
- Data quality metrics such as accuracy, completeness, consistency, and validity.
- User confidence scores measured through surveys, a data catalog, or service desk metrics related to data issues.
- A governance metric related to how many data sets meet governance and security policies.
If you are on a data governance or security team, consider the metrics that CIOs, chief information security officers (CISOs), and chief data officers (CDOs) will consider when prioritizing investments and the types of initiatives to focus on.
Amer Deeba, GVP of Proofpoint DSPM Group, says CIOs need to understand what percentage of their data is valuable or sensitive and quantify its importance to the business—whether it supports revenue, compliance, or innovation. “Metrics like time-to-insight, ROI from tools, cost savings from eliminating unused shadow data, or percentage of tools reducing data incidents are all good examples of metrics that tie back to clear value,” says Deeba.
Dataops metrics
Dataops technical strategies include data pipelines to move data, data streaming for real-time data sources like IoT, and in-pipeline data quality automations. Using the reliability of water pipelines as an analogy is useful because no one wants pipeline blockages, leaky pipes, pressure drops, or dirty water from their plumbing systems.
“The effectiveness of dataops can be measured by tracking the pipeline success-to-failure ratio and the time spent on data preparation,” says Sunil Kalra, practice head of data engineering at LatentView. “Comparing planned deployments with unplanned deployments needed to address issues can also provide insights into process efficiency.”
Kalra recommends developing data observability practices, which involve monitoring data’s health, accuracy, and reliability throughout the pipelines.
“Successful adoption of observability across organizations relies on three key verticals: transparency, self-service, and tagging hygiene,” says Tameem Hourani, principal and founder at RapDev. “Measuring tagging accuracy and ensuring clean data is ingested accelerates the adoption of self-service, ensuring engineers and power-users across the organization have access to all the data they need.”
Tagging is one type of data enrichment that can be automated in data pipelines. Other dataops metrics can demonstrate the business impacts of operating robust pipelines at the required speed, quality, and efficiency.
Time-to-value, data quality scores, and automation rates demonstrate how efficiently data moves from ingestion to insights, while reductions in data-related incidents and compliance risks quantify operational resilience,” says Ashwin Rajeeva, CTO & co-founder of Acceldata. “By linking these KPIs to cost savings, productivity gains, and strategic growth, CIOs can drive greater investment, shift organizational culture, and establish data as a core competitive advantage.”
Paul Boynton, co-founder and COO of Company Search Incorporated, further suggests that “dataops should use KPIs like deployment frequency, incident response time, and data quality scores.”
Data governance metrics
Data governance metrics are thematic and focus on accuracy, completeness, timeliness, uniqueness, and compliance. Data governance metrics can support increased end-user adoption of data-driven practices.
“Measuring data security and governance effectiveness requires tracking three essential OKRs: time-to-access for data requests, amount of data without designated owners, and proportion of classified versus unclassified data,” says Pranava Adduri, CTO and co-founder of Bedrock Security. “CIOs should prioritize demonstrating improved data ownership clarity to reduce friction between security and development teams, minimize alert fatigue in SOC teams, and accelerate policy enforcement across disparate platforms. These OKRs also support organizations’ ability to scale data operations and rapidly secure data for emerging use cases like AI model training.”
Other recommendations focused on measuring the organizational impacts of data governance. Edward Calvesbert, VP of product management at IBM watsonx platform, says, “KPIs for a data governance program might entail reductions in data redundancy, improved data usage, cost savings from reductions in data wrangling, and faster time-to-market of new insights and applications.”
Compliance and risk management benefits are a third area to be measured. “Data governance generates savings in compliance costs, avoiding fines and reputational damage,” adds Calvesbert. “These are KPIs with impact that ripple far beyond the CIO’s office, unlocking opportunity across the enterprise.”
Akula of The Modern Data Company adds KPIs on the effectiveness of data governance programs. “For security and governance, track the sensitive data exposure rate, the percentage of critical data properly controlled, and the data duplication index, which measures unnecessary copies that indicate governance gaps,” Akula says.
Another important consideration is end-user adoption. Deeba of Proofpoint notes it’s also critical to measure how well teams are adopting governance policies and accessing data securely without friction.
Global and regulated organizations must also measure their data provenance and sovereignty practices, and these regulations also impact many smaller domestic businesses. Data provenance tracks the origin, history, and transformations of data throughout its lifecycle and is important in regulated industries where capturing data lineage is required. Data sovereignty is the legal and regulatory ownership of data based on the country or region where it is stored or processed.
“Organizations should measure their governance program’s effectiveness through quantifiable metrics that demonstrate sovereignty, like data lineage accuracy and data exposure incidents,” says Jeremy Kelway, VP of engineering for analytics, data, and AI at EDB. “Success indicators should include decreased sensitive data exposure risks, improved data locality compliance scores, and enhanced visibility into how data interfaces with AI systems across jurisdictional boundaries.”
What can be incredibly challenging is getting the business to collaborate in implementing data governance functions. Just getting data owners assigned and data sets classified can be an uphill battle. When data governance teams can’t get the collaboration, what other options should they consider?
Alastair Parr, executive director of GRC Solutions at Mitratech notes that “fostering a competitive data security and governance culture drives broader buy-in and success. KPIs and OKRs should incorporate department- and function-level comparative scorings based on the selected metrics,” he says.
Data security metrics
Experts suggest aligning data security metrics to standards such as ISO 27001, NIST CSF 2.0, and CIS.
Greg Anderson, CEO and founder of DefectDojo says, “In the simplest of terms, measuring effectiveness comes down to what framework and level you select, and then monitoring what percentage of your organization is in compliance. ISO 27001 is probably the most popular standard, but it’s also broad.”
Anderson suggests tracking the following metrics regardless of the frameworks being used:
- Incident metrics, including the number of breaches and unauthorized access attempts.
- The meantime to detect (MTTD) and respond (MTTR) to security issues and the speed of identifying and resolving threats.
- Pass/fail rates for GDPR, HIPAA, and other compliance requirements.
- Vulnerability metrics, including open vulnerabilities and patching frequency.
- Training completion, such as the percentage of staff trained on security protocols.
- The percent of sensitive data encrypted.
- Access control metrics for addressing least-privilege access.
- Percentage of data cataloged by severity and criticality (this metric works in collaboration with the data governance function).
Dataops, governance, and security metrics in practice
Kajal Wood, VP of software engineering at Capital One, shared a detailed perspective on how to put the theory of data effectiveness into practice. “Measuring effectiveness starts with building a well-governed and high-quality data ecosystem. To do this, we consider data quality metrics like accuracy, completeness, accessibility, and availability, to ensure teams can trust and use data effectively. Observability and security KPIs like data lineage coverage, ensuring all shared and used data is registered in the catalog, sensitive data detection and remediation, and incident response times demonstrate governance maturity. Dataops efficiency metrics like pipeline deployment speed, automation rates, and consumption experience reflect agility.”
The goal of such an encompassing list of metrics, Woods adds, “is to align these metrics with business outcomes—faster innovation, reduced risk, and improved decision-making—to unlock tangible value from data.”
A mature, data-driven organization can support metrics like these, but it takes time to develop the practices. Starting with fewer meaningful metrics is often better than having too many. Put your metrics through a simple three-question test:
- Will the business understand the metric, and does it connect to value?
- Does it measure where investments are being made and demonstrate improvements?
- Is capturing the metric automated and easy to report on?
As more organizations invest in dataops, data governance, and data security, metrics that measure the value, operational efficacy, and risk involved are crucial.
{kind=link}
Google’s bold step toward hybrid AI integration 15 Apr 2025, 11:00 am
News stories about cloud services and artificial intelligence are generally predictable. Another generative AI model, another upgraded cloud feature, another boast about “leading the market in innovation.” That’s all well and good, but Google’s announcement at the Google Cloud Next 2025 conference in Las Vegas is not just about AI. It’s not even primarily about AI. It’s about something more fundamental: Google’s willingness, as a public cloud provider, to welcome integration across platforms—and to support it.
In an era where public cloud providers are fiercely competing for enterprise dominance, the industry tends to push businesses to fully embrace a specific cloud ecosystem. The providers operate under an outdated paradigm that success means closing the door on hybrid or multiplatform solutions. Google’s latest move, however, flies in the face of this unrealistic approach.
The announcement of on-premises deployment options for Google’s Gemini generative AI models is an example of how the company recognizes the growing complexity of enterprise demands. By collaborating with Nvidia and allowing enterprises to run generative AI workloads on Nvidia’s Blackwell HGX and DGX hardware, Google is not dictating terms to its customers. Instead, it is sending a clear message: “We’ll work with the platforms that best serve your business.” Finally.
This subtle shift represents a philosophical departure from how many other public cloud providers approach integration. Where others fight for exclusivity, Google champions a flexible, collaborative approach. Enterprises now have the freedom to deploy Google’s cutting-edge technology where it makes the most sense for them, whether that’s on premises, in the cloud, or in hybrid environments blending the two. This is not just about advancing enterprise AI. This is about meeting businesses where they stand—on their own terms.
Flexibility is great but has a cost
The business landscape is becoming increasingly fragmented. Enterprises want flexibility that provides the maximum value and combines their historical investments with the latest innovations. Today’s enterprises want systems and solutions that work together.
What makes Google’s approach so significant is its willingness to support Nvidia’s hardware through Nvidia Confidential Computing, which combines performance with security for enterprise workloads. This gives enterprises true options for where and how they want to process highly sensitive data. This hybrid-first mindset respects the reality that CIOs and enterprise architects must balance cloud adoption ambitions with practical business needs every day.
Other cloud providers—who shall remain unnamed—continue to pursue lock-in strategies under the guise of innovation, forcing enterprises to operate their workloads exclusively within proprietary ecosystems. Providers feel this is necessary to protect their share of the market, but it ignores a long-established truth: Customers don’t want to be pigeonholed.
Google seems to understand this better or faster than its competitors. By enabling its AI models to work seamlessly on external platforms using Nvidia’s next-generation hardware, Google is setting a precedent for what public cloud providers should do. By aligning its road map with the market’s natural evolution, Google is moving toward interoperability, portability, and customer-first solutions.
Yes, this strategy might pose short-term risks for Google in a competitive marketplace. However, in the long term, the company is building trust and defining itself as a partner for enterprises rather than just another tech vendor peddling another walled garden.
Now for the downsides. Enterprises that use this technology must manage the additional and unavoidable complexity of a hybrid environment. Although flexibility is a benefit, integrating on-premises systems such as Nvidia’s hardware with other cloud services can create interoperability and maintenance challenges that require specialized expertise.
This approach may also result in higher costs, as enterprises must invest in both cutting-edge hardware and cloud service integration. Additionally, data security risks could increase if systems are not properly secured across platforms, especially when sensitive data travels between local and cloud environments. Finally, enterprises may face longer deployment times and unexpected compatibility issues. All these challenges could delay their ability to see value.
Applause for the unforced approach
For years, the industry has heard loud proclamations from public cloud providers boasting about their willingness to collaborate. What sets Google apart with this announcement is a signal of real action rather than empty pledges. Supporting flexible deployments without compelling businesses to go “all in” on Google Cloud is a pragmatic approach. It acknowledges that enterprises have diverse needs and unique environments, and success doesn’t come from controlling customers but empowering them.
Enterprises should applaud Google’s stance because it demonstrates listening—a rare trait in the technology world. This hybrid-friendly strategy benefits not just businesses but also the broader market as innovation becomes better distributed and less centralized under the grip of single ecosystems.
The announcement at Google Next may outwardly appear to be another “AI breakthrough” me-too story. Don’t miss the point. In the face of cloud consolidation, Google’s decision to collaborate with Nvidia and pave the way for hybrid deployments is a major stride for AI as well as for enterprise autonomy. Corporations now have the flexibility and security to make cloud and AI decisions that work best for their unique ecosystems. They can run Gemini wherever they derive the most business value, and they can do so with newfound confidence in their ability to uphold data sovereignty.
This is a win for the entire industry. Being a leader in cloud innovation doesn’t mean pushing customers into your ecosystem. It means making the tools available to work where they are needed. This thoughtful, collaborative approach is the real story behind the headlines. It’s a big deal, and Google deserves to be applauded for its courage and innovation. Advances like this are how our industry will reinvent, renew, and thrive.
{kind=link}
Microsoft .NET Aspire adds resource graph, publishers 15 Apr 2025, 12:57 am
Microsoft has released .NET Aspire 9.2, a new version of the company’s cloud-ready stack for building distributed applications that features dashboard enhancements, including a resource graph, and publishers, new tools that help developers write code to package and deploy apps to Docker Compose, Kubernetes, Azure, and eventually other hosts.
Instructions for updating to .NET Aspire 9.2 can be found at devblogs.microsoft.com.
In .NET Aspire 9.2, the resource graph is a new way to visualize resources in apps, displaying a graph of resources linked by relationships. Also in release 9.2 are resource icons, added to the resource pages. The icon color matches a resource’s telemetry in structured logs and traces. A new metric warning in the dashboard, meanwhile, warns when a metric exceeds a configured cardinality limit. Once exceeded, the metric no longer provides accurate information, Microsoft said.
Also to improve the dashboard user experience, the update adds buttons to the Console logs, Structured logs, Traces, and Metrics pages to pause collecting telemetry. This feature allows users to pause telemetry in the dashboard while continuing to interact with an app.
Billed as a minor release despite a host of improvements, .NET Aspire 9.2 supports long-term support releases of .NET 8 and .NET 9. Other improvements in .NET Aspire 9.2:
- Resources now can define custom URLs. This makes it easier to build custom experiences for resources.
- Console logs now support UTC timestamps.
- A search text box has been added to trace details. Developers can filter large traces to find the exact span needed.
- Custom resource commands now support HTTP-based functionality, through the addition of a
WithHttpCommandAPI. Developers can define endpoints for tasks, such as database migrations or resets. - A
WithContainerFilesAPI provides a way to create files and folders inside a container at runtime by defining them in code. - A
ConnectionStringResourcetype makes it easier to build dynamic connection strings without defining a separate resource type. - Container resources can now specify an
ImagePullPolicyto control when an image is pulled. - An
AddAzureContainerAppEnvironmentresource allows users to define an Azure Container App environment directly in an app model. - When deploying to Azure Container Apps with .NET Aspire 9.2, each Azure Container App now gets its own dedicated managed identity by default.
{kind=link}
7 reasons low-code and no-code tools fail to deliver 14 Apr 2025, 11:00 am
The potential benefits of low-code and no-code development tools include faster application development, lower expenses, and more agility. The technology is not suited to every scenario, however, and in some cases, low- and no-code solutions could be a barrier to productivity.
Research firm Grand View Research predicts the global low-code development platform market will expand at a compound annual growth rate of about 23 percent from 2023 to 2030. The report attributes this growth to the increasing focus on digital transformation and automating business operations. It may also be driven by the demand for quick solutions and more streamlined business processes.
While the promise of easier development is tempting, organizations must be prepared to navigate the potential pitfalls of low-code and no-code tools and platforms. We asked tech leaders what to watch out for when migrating to these solutions. Here’s what they told us.
7 reasons low-code implementations fail
- Losing depth and flexibility
- Over-simplified solutions
- Failure to scale
- Unreliable LLMs
- Security risks
- Vendor lock-in
- Underestimating the technology
Losing depth and flexibility
A core use case for low-code and no-code tools is enabling unskilled users to create software. This not only widens the pool of individuals who create software but may have financial benefits for organizations seeking to hire fewer developers. But it’s important for organizations adopting low-code and no-code solutions to be prepared to lose some flexibility in the process.
“Low code/no code platforms typically provide a set of predefined templates and components that make it easier for business users to develop simple apps quickly,” says Clayton Davis, senior director of cloud-native development at cloud services provider Caylent. “However, these templates often lack the flexibility and depth needed to create truly customized, purpose-built solutions that resonate with end users,” Davis says.
While low-code and no-code tools and platforms can suffice for internal business solutions or simple tasks, “they do not meet the standards required for customer-facing applications, where user experience is critical to adoption and satisfaction,” he says.
Low-code and no-code tools can also be restrictive for developers needing more control over an application’s architecture. Arsalan Zafar, co-founder and CTO of Deep Render, a developer of video compression technology, says a possible solution is to “use low-code platforms with extensibility options or leverage APIs to integrate custom features when necessary.”
Over-simplified solutions
Over-simplification is a related challenge, where business users might create applications that don’t fully address the nuances of a problem, Zafar says.
His organization faced such a challenge while trying to build an application for comparing video codecs. “Initially, the no-code platform allowed us to quickly prototype and deploy a basic version of the application, which was a huge time-saver compared to starting from scratch with traditional development methods,” he says. However, as development progressed, the team ran into major hurdles.
“When it came to incorporating custom features that would set our product apart in the market, we found the platform’s limitations became more apparent,” Zafar says. “Integrating more advanced features, like multi-layered video comparison metrics or AI-driven enhancements, became a tedious and time-consuming process.”
The lack of support for custom integrations forced the organization to spend extra time working around the platform’s constraints, which hindered its ability to deliver tailored solutions. “This experience showed us the trade-off between the speed and convenience of no-code tools for quickly building something and the lack of flexibility when it comes to scaling up a product for more complex, enterprise-level needs,” Zafar says.
Failure to scale
“Low-code and no-code are absolutely amazing for prototyping or testing out MVPs—minimum viable products—but fail extremely short for scaling,” says Kushank Aggarwal, a software engineer and founder of DigitalSamaritan, a platform sharing artificial intelligence (AI) tutorials and tools.
“For example, when we came up with the idea for [AI tool] Prompt Genie, we went from idea to launch to first paying customer in just four days, using a no-code approach,” Aggarwal says. “But once we got the product to a market fit, we ran into major challenges in scaling.”
The low-code, no-code platform the company used wasn’t designed to handle a growing user base, “so it required a complete rebuild and migration of all the users, which was nothing short of tricky,” Aggarwal says. “You can run into issues with data loss, downtime, and broken workflows, among others. Depending on how validated your idea is, you can skip low-code and no-code and build things for scalability from scratch.”
While suitable for smaller, less complex applications, “these platforms may struggle to meet the demands of large-scale enterprise applications,” Zafar says. Evaluate the long-term viability of the platform before using it in mission-critical systems.”
Unreliable LLMs
Most low- or no-code development today is done through the use of large language models (LLMs), and this can be costly for organizations, says Devansh Agarwal, senior machine learning engineer at Amazon Web Services.
LLMs “are really good at predicting what would be the next word” or token, Agarwal says. “Based on this, they are able to generate sentences and code.” However, LLMs do not reason like human beings do, he says. “[Software product] requirements are very complex and ever-evolving. To get a decent output from an LLM, we need to try multiple prompts.” Doing so can be costly, he says.
It’s difficult to provide all the product requirement information to an LLM and expect it to generate a solution, as the product requirements are changing all the time,” Agarwal says. “If you ever try to make ChatGPT write code and if it makes a mistake, then you ask it to correct it, it will generate an entirely new solution,” he says. “Imagine the chaos it will cause when product requirements change.”
Security risks
“As a CIO, you want to make sure the technology you’re providing to your organization is both safe and useful,” says Jon Kennedy, CIO of Quickbase, a provider of project management software. “Unfortunately, not all no-code or low-code platforms are built with a framework that promotes security and governance.”
For example, highly regulated industries such as healthcare have strict requirements, which not all platforms are designed to operate in or support, Kennedy says.
“When a no-code platform is deployed throughout an organization, or open to outside users, it may be prudent to restrict access and controls,” he says. “Quickbase has so many of our customers with countless tools and vendors to manage and integrate with, and they need to securely make all this information and data accessible when and where it’s needed.”
A major security risk emerges when a large number of websites are created using a no-code tool that has even a small security flaw in the code. “It would leave all these websites and their millions of users vulnerable,” Agarwal says. “This is terrifying, as the people who use these no-code tools won’t know how to fix these risks, so [they] will remain in the public domain for a long time.”
As the adoption of low- and no-code tools increases, the risk of this kind of major breakdown also increases exponentially. A good practice is to “always keep a human in the driver’s seat and keep the tools as just a helping agent,” Agarwal says. “You should have at least one expert on your team that could vet anything that is being created by these tools.”
Vendor lock-in
Many low-code or no-code platforms work as closed ecosystems, so it can be difficult to switch providers, Aggarwal says. “This kind of dependency might lead to higher costs, will limit flexibility, and there’s always the risk of a platform shutting down a feature you need,” Aggarwal says.
“If you have to switch platforms, that is a nightmare,” says Siri Varma Vegiraju, security tech lead at Microsoft. “Because you are locked into that platform, switching platforms requires understanding the new one from scratch,” he says. Switching platforms means re-building everything from scratch, he says, “whereas, with code, you just have to change some infrastructure components and dependencies.”
Underestimating the technology
While most experts spoke about low-code’s technical shortcomings, underestimating the potential of the tools is also an issue, says Alan Jacobson, chief data and analytics officer at Alteryx.
“For some, this can be tied to a bias based on the solution’s name and ability to open access to non-technical workers,” Jacobson says. “This bias unfortunately leads to an incorrect assumption that these solutions are less powerful or less sophisticated.”
Organizations can address this misconception by ensuring their teams are learning and understanding the full capabilities of the tools to unlock their true value, realize their full benefits, and empower end users, Jacobson says.
{kind=link}
How pet projects fuel innovation and careers in tech 14 Apr 2025, 11:00 am
Call them pet projects, side projects, or hobby projects, projects pursued outside of one’s regular business activity are especially popular among software developers. After all, these projects serve as an excellent way to learn new skills and technologies or to test fresh concepts and approaches. Whether sparked by a spontaneous idea or driven by a constant passion, pet projects are often bolder and more challenging than a developer’s day-to-day work, offering an opportunity for growth.
Stack Overflow research shows that most developers code outside of work as a hobby (68%), and almost 40% code outside of work for professional development or self-paced learning from online courses. Only 12% of the developers Stack Overflow surveyed don’t code outside of work.
Developing smart home applications and games are popular side projects for developers:
- According to GitHub’s Octoverse report, a staggering one-billion contributions were made by developers worldwide to open-source and public repositories across GitHub in 2024. Home Assistant, an open-source home automation project, received a large portion of these contributions.
- The second most popular (28%) game engine for hobby projects after Unity (48%) is Godot. It’s completely free and open-source (through an MIT license) and has 21,000 forks on GitHub. According to the 2024 State of Game Technology Report by Perforce, Godot is emerging as a popular alternative to Unreal Engine and Unity in indie and mid-size studios, with a 9% share.
Coders never stop coding
At Microsoft Research, I met a computer graphics researcher who was keen on encoding everything he saw around him, including fireworks at Guy Fawkes Night. Another time I was surprised by a developer advocate at JetBrains who turned out to be the author of a conference’s travel system. Developers never stop coding, which helps them stay up-to-date with the rapid advancements in technology.
For many developers who experienced layoffs in recent years, working on a pet project became a way to stay in the loop. As reported in the JetBrains State of Developer Ecosystem Report 2024, 16% of respondents were laid off in the past two years, and 14% were working in companies that were affected by mass layoffs.
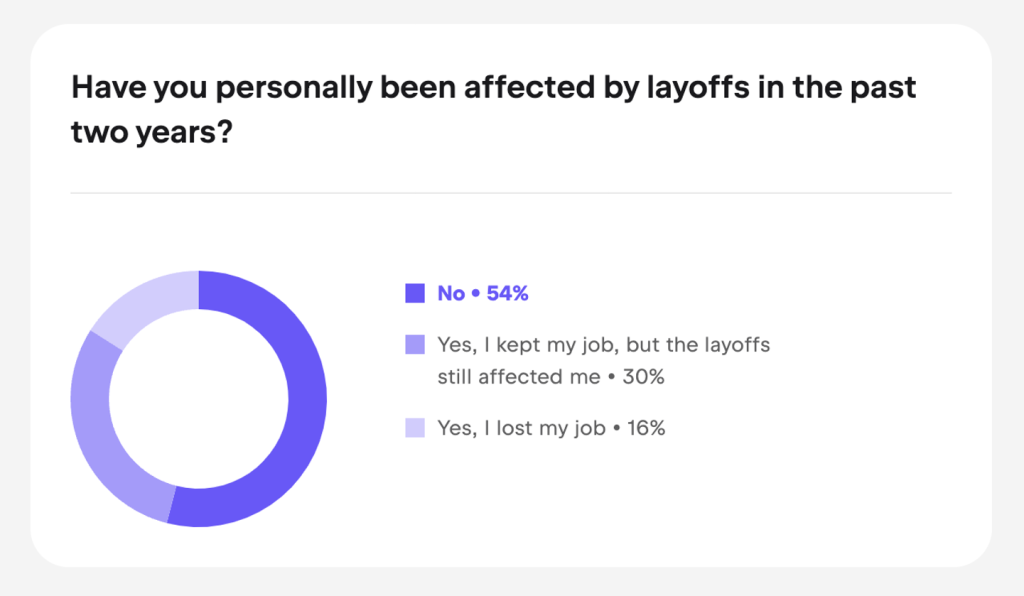
JetBrains
Developers who lose their jobs often use the downtime to expand their skill set. They might unpack the project they buried under everyday work many years ago and dedicate their time and effort to it, learning new skills and driving new ideas. Not everyone can afford a long break, however. Some developers who lose their jobs focus on educational courses to learn modern technologies and get new jobs quickly. This can still involve contributing to a small pet project as part of the course.
Pet projects can also become a first step in a developer’s professional career. The JetBrains State of Developer Ecosystem Report explored career switchers in tech in 2024, and found the following:
A substantial 22% of software developers who took part in our survey previously worked in different industries, which demonstrates the industry’s accessibility and appeal to professionals from diverse backgrounds. For career switchers, it’s crucial to focus on building a strong foundation in essential programming languages and software development principles. Gaining practical experience through projects, internships, or coding boot camps can help facilitate this significant life change.
Free online courses and coding schools are the second driving force that led respondents toward becoming developers, according to the report:
JetBrains
Pet projects are promoted by many educational courses or training materials as a key way of learning things. You can implement your independent idea or select from various open-source projects.
The pet project that changed C++ development
Compiler Explorer is now one of the most popular resources among developers. The surname of its creator, Matt Godbolt, became a verb (godbolting), describing the process of diving into the underlying assembly code to understand compiler optimizations and how modern compilers work.
Godbolt works in low-latency trading, where faster code means identifying profitable trading opportunities more quickly and efficiently. In his CppCon 2017 keynote presentation, What Has My Compiler Done for Me Lately?, Matt shared insights he learned from Compiler Explorer after building it. In an interview with JetBrains’s C++ team a month after that CppCon presentation, Godbolt shared the story of the project:
A friend and I were considering whether we could use range-for instead of a normal for-loop, but we wanted to be sure the compiler generated good code for the new feature. I hacked together a quick script to quickly dump the compiler output and Compiler Explorer was born!
What started as a pet project to help a trading systems developer in his daily work changed the whole community landscape. People are now using Compiler Explorer widely, posting permalinks on the site to share code samples. It has become standard practice for C++ standardization contributors to include links to the code examples in Compiler Explorer in their language proposals. Herb Sutter contributed heavily to this trend with links to metaclass examples running in Compiler Explorer in his proposal. The test implementation in the Clang branch was done before presenting the proposal to the committee, placed in Compiler Explorer, and referenced in the proposal. Nowadays, you can find many more Clang-based branches in Compiler Explorer referenced by one of the dozens of C++ language proposals. Creating a test implementation before getting a new idea approved for the language, or even discussed deeply within the committee, has become a trend.
JetBrains
Many other languages were added to Compiler Explorer by enthusiasts from all over the world. The service is now supported by big companies and their donations. Microsoft even provided Matt with the version of its proprietary MSVC compiler to work in Compiler Explorer. All of this began with a humble pet project.
From pet project to next big thing
A pet project culture can reap big rewards for businesses. By giving developers time to express their creativity and explore new ideas, pet projects foster employee satisfaction and spark creativity that can bring innovations to the company at a lower cost. Many well-known products started this way. Just to name a few:
- The story of Ken Kutaragi, the father of the Sony PlayStation, is worth a Hollywood screenplay. His proprietary CD-ROM-based video game system with 3D graphics faced criticism and disbelief from inside the company, but ended up becoming the leading game console globally.
- Another famous pet project is Gmail, by Paul Buchheit at Google. Paul started with the idea even before he joined the web giant. Project Caribou, as Gmail was called at that time, was a search engine for Paul’s email. The beta version was released in 2004. Since then, Gmail has become one of the world’s most widely used email services.
- X, formerly Twitter, or twttr as it was called originally, is another example of how the core business of a company can pivot with just one project. Originating from an internal SMS service for Odeo employees, the side project emerged to become one of the most successful internet businesses so far.
- JetBrains’s Toolbox App was born at a company-wide hackathon, with the idea to simplify the process of installing, updating, and uninstalling different JetBrains desktop tools. It’s now considered the main entry point to all JetBrains desktop tools and is used by more than one-million developers daily.
Like JetBrains’s Toolbox App, many of the pet projects that eventually contribute to a company’s core business are born or developed during company hackathons. These are events where employees can present their ideas, invite colleagues to support them, and work on a prototype non-stop for a day or two (sometimes around the clock). Companies encourage employees to participate by providing food, leisure resources like massage or sleeping rooms, and access to internal resources and services. Along with monetary prizes, company-wide award ceremonies are often held to recognize notable projects.
Pet projects can be one-time or recurring. Google’s 20% time policy for pet projects has been adopted by many other large organizations. For small companies or startups that can’t afford to free up 20% of their developers’ time, regular hackathons may be a good option. For companies that can afford a standard time policy, it’s often promoted to the employees as a company benefit, just like longer vacation times or extended insurance.
Drawbacks of pet projects
While there are clear advantages for employees, is a pet project culture beneficial for the company itself? Company leadership would understandably love to get another Gmail or PlayStation launched with minimal costs and without drawing significant resources away from the main business. However, quite often companies run into the following drawbacks of pet projects:
- Pet projects can take a considerable amount of employees’ time, diverting focus and energy from their main working tasks. It’s difficult to maintain the same level of inspiration across multiple projects simultaneously, and developers may become more engaged with the pet project than their core work. The effort impacts the results, slowing down core business tasks and lowering the level of innovation in them.
- When pet projects are done using company resources, costs are allocated from company budgets. Consider the use of company-wide cloud resources, CI/CD, large language models, etc. Given the experimental nature of pet projects, these costs may be high, unpredictable, and unmanaged by the teams responsible for such resources and costs.
- The risks of failing with pet projects, and the company getting nothing in return, are high. Additionally, risk assessment is rarely done for pet projects.
- The risk of losing the bright new product after the pet project evolves beyond a prototype is also high. Employees whose pet projects evolve into successful ventures tend to leave their original company to establish their own startups, find new investors, and work on their ideas independently.
Because many company managers have met the above risks in practice, you can find many articles online that will tell you how to turn a pet project into an official activity that benefits the company. They generally advise the following:
- Establish the area for research and manage the direction of pet projects to ensure they stay relevant to the company’s core business or target audience.
- Regularly review pet projects to keep them on track.
- Own the intellectual property to avoid losing the project and its core contributors.
- Track the deliverables and manage the projects and their KPIs.
However, balancing company needs with the freedom developers seek for pet projects can be challenging.
Take advantage of free tools
Finally, pet projects offer the opportunity to try out new or unfamiliar development tools. For 20% projects, the company might pay for the necessary tools. However, if the project is not part of a company program, then developers may want or need to turn to free tools. Fortunately, many tool vendors allow the use of their commercial technologies for free for non-commercial projects. For example:
- Leading paid game engines like Unity or Unreal Engine allow free usage below certain revenue thresholds.
- Microsoft provides developers with the Community version of Visual Studio to cover the needs of pet projects.
- In October 2024, JetBrains announced the shift to free non-commercial license tiers.
Non-commercial licenses suit learning and self-education, hobby development, and content creators. For example, if you plan to start learning game development, you could:
- Select one of the free crash courses or tutorials on YouTube or any other educational resources.
- Fork a free sample project from GitHub.
- Start with the game engine for free and learn it in practice.
- Try a free IDE according to tutorial recommendations or your own preferences.
And who knows, maybe game development will become the next big step in your career journey. Whatever the nature of your pet project, you will almost certainly gain knowledge, experience, and skills that your current or future company will find valuable.
Anastasia Kazakova is a C++ developer now working as head of marketing and business development at JetBrains.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
DeepSeek’s open source movement 14 Apr 2025, 11:00 am
DeepSeek may have originated in China, but it stopped being Chinese the minute it was released on Hugging Face with an accompanying paper detailing its development. Soon after, a range of developers, including the Beijing Academy of Artificial Intelligence (BAAI), scrambled to replicate DeepSeek’s success but this time as open source software. BAAI, for its part, launched OpenSeek, an ambitious effort to take DeepSeek’s open-weight models and create a project that surpasses DeepSeek while uniting “the global open source communities to drive collaborative innovation in algorithms, data, and systems.” If that sounds cool to you, it didn’t to the U.S. government, which promptly put BAAI on its “baddie” list. Someone needs to remind U.S. (and global) policymakers that no single country, company, or government can contain community-driven open source.
The moment that keeps on going
It’s increasingly common in AI circles to refer to the “DeepSeek moment,” but calling it a moment fundamentally misunderstands its significance. DeepSeek didn’t just have a moment. It’s now very much a movement, one that will frustrate all efforts to contain it. DeepSeek, and the open source AI ecosystem surrounding it, has rapidly evolved from a brief snapshot of technological brilliance into something much bigger—and much harder to stop. Tens of thousands of developers, from seasoned researchers to passionate hobbyists, are now working on enhancing, tuning, and extending these open source models in ways no centralized entity could manage alone.
For example, it’s perhaps not surprising that Hugging Face is actively attempting to reverse engineer and publicly disseminate DeepSeek’s R1 model. Hugging Face, while important, is just one company, just one platform. But Hugging Face has attracted hundreds of thousands of developers who actively contribute to, adapt, and build on open source models, driving AI innovation at a speed and scale unmatched even by the most agile corporate labs.
Hugging Face by itself could be stopped. But the communities it enables and accelerates cannot.
Through the influence of Hugging Face and many others, variants of DeepSeek models are already finding their way into a wide range of applications. Companies like Perplexity are embedding these powerful open source models into consumer-facing services, proving their real-world utility. This democratization of technology ensures that cutting-edge AI capabilities are no longer locked behind the walls of large corporations or elite government labs but are instead openly accessible, adaptable, and improvable by a global community.
It’s Linux all over again
In many respects, the rise of open source AI mirrors the trajectory of Linux from decades past. What started as the passion project of a lone developer quickly blossomed into an essential, foundational technology embraced by enterprises worldwide. Linux won not because it had superior backing from governments or major corporations, though it eventually earned both. No, Linux initially won out precisely because it captivated developers who embraced its promise and contributed toward its potential. Its inherent openness enabled rapid, organic growth driven by practical necessity and persistent innovation from a dedicated global community.
We are witnessing a similar phenomenon with DeepSeek and the broader open source AI ecosystem, but this time it’s happening much, much faster. AI adoption and innovation cycles now run in weeks and months rather than the years and decades typical of previous technology revolutions. Organizations that cling to proprietary approaches (looking at you, OpenAI!) or attempt to exert control through restrictive policies (you again, OpenAI!) are not just swimming upstream—they’re attempting to dam an ocean. (Yes, OpenAI has now started to talk up open source, but it’s a long way from releasing a DeepSeek/OpenSeek equivalent on GitHub.)
You can’t stop us now
This brings us to policymakers and the role governments imagine they can play. The current geopolitical approach to AI governance—epitomized by the restrictions imposed on BAAI—is at best shortsighted, and at worst, actively harmful. Open source isn’t subject to export controls or trade embargoes. It’s a pull request away, all day every day. Trying to block or slow the open source AI movement through policy edicts fundamentally misunderstands the decentralized, organic nature of technological evolution itself.
Indeed, the war between countries and corporations to dominate AI is already over. It’s too soon to say that open source AI has won (most models we regularly use are proprietary), but directionally, all signs point to open source. That said, it remains to be seen just how open the big players are willing to be: Meta’s Llama 4, for example, is exceptionally impressive but Meta seems determined to stick to its “open enough” licensing stance.
The recent history of technology underscores why policy-driven containment strategies inevitably fail. Open source ecosystems operate as living organisms, continuously mutating and adapting. Unlike centralized corporate projects, open source initiatives such as OpenSeek rapidly evolve, leveraging global collaboration at scale. Innovations that might take years in closed environments often happen within weeks when code, ideas, and data flow freely.
AI policymakers would do well to understand this dynamic sooner rather than later. Restrictive policies won’t just fail to halt the spread of open source AI; they’ll inadvertently harm domestic companies and push innovation—and critical technological leadership—away. (President Trump is madly attempting to shift the balance of AI innovation away from the U.S. with tariffs that threaten to halt AI infrastructure spending by Microsoft, Google, Amazon, and Meta, among others.)
The unstoppable nature of the open source AI movement—exemplified by DeepSeek and its global progeny—signifies a profound shift in technological development. No one can own this wave, no one can stop it, and no one can contain it. Embrace it, shape it, contribute to it, or risk being left behind. Open source AI isn’t just the future; it’s already reshaping the present.
{kind=link}
.NET 10 Preview 3 bolsters standard library, C#, WebAssembly 12 Apr 2025, 9:01 pm
Microsoft has released its third preview of .NET 10, a planned update to the company’s cross-platform, open-source, application development platform. Among the highlights, .NET 10 Preview 3 introduces an AOT-safe constructor for ValidationContext, more powerful C# language extensions, and Blazor WebAssembly improvements.
.NET 10 Preview 3 was unveiled April 10 and can be downloaded from dotnet.microsoft.com. It follows Preview 2, published March 18, and Preview 1, published February 25. .NET 10 is likely to ship as a production release in November.
Among the capabilities in third preview is an AOT-safe constructor for the ValidationContext class in the standard library. The ValidationContext class is used during options validation to provide validation context. However, because extracting the DisplayName can involve reflection, existing constructors of ValidationContext are currently marked as unsafe for AOT (ahead of time) compilation. The new constructor ensures AOT safety, enabling developers to use ValidationContextin native builds without bumping into errors or warnings.
Also with .NET 10 Preview 3, the standard library gains a deterministic option for the LightGBM trainer in ML.NET. This update exposes LightGBM’s deterministic, force_row_wise, and force_cos_wise options to allow developers to force deterministic training behavior when needed. And for C# 14, extensions now support static methods, instance properties, and static properties. More extension support is planned for an upcoming release, Microsoft said.
Other enhancements in .NET 10 Preview 3:
- Standalone Blazor WebAssembly apps now can reference static web assets using either a generated import map or a fingerprinted URL. Also in Blazor WebAssembly, response streaming is now enabled by default for
HttpClient. This improves performance and reduces memory usage when handling large responses, Microsoft said. - In the .NET runtime, improved code layout is featured via the JIT compiler, with an optimization related to block ordering.
- With the SDK and CLI, the
--interactiveflag will be enabled by default for all uses of the CLI believed to be interactive, specifically those where the command output has not been redirected, as well as those that are not running in an environment believed to be a CI/CD server. - For .NET MAUI (Multi-platform App UI), various performance improvements have been made. Also, a
CancellationTokennow may be passed toWebAuthenticator.AuthenticateAsync, enabling programmatic canceling of authentication. - OpenAPI support has been enabled by default in the ASP.NET Core Web API (native AOT) template.
- On .NET for Android, the release focused on quality improvements, experimental runtimes, and build performance.
.NET 10 Preview 2 offered improvements such as allowing callers to choose which encryption and digest algorithms are used to produce the output. .NET 10 Preview 1 introduced C# 14, with “first-class” support for System.Span and System.ReadOnlySpan in the language.
{kind=link}
Google Cloud Next 2025: News and insights 11 Apr 2025, 5:18 pm
Google Cloud Next ’25, which runs from April 9-11 in Las Vegas is highlighting the latest advancements and future directions of Google Cloud Platform and cloud computing. This year, artificial intelligence and machine learning, along with announcements of new AI-powered tools and services aimed at boosting productivity, automating tasks, and driving innovation across industries, are dominating the news.
Another theme will undoubtedly be data analytics and management. With the rise in the volume of data, Google Cloud Next is expected to unveil updates and new features for BigQuery, data lakes, and other data-centric services. The focus will likely be on making data more accessible, actionable, and secure for enterprises of all sizes. Expect discussions around real-time analytics, data governance, and the integration of AI/ML with data workflows.
Hybrid and multicloud strategies will also be a prominent topic. Google Cloud has been promoting its Anthos platform, and so you can expect further developments and success stories around enabling seamless workload migration and management across on-premises, Google Cloud, and other cloud environments. This will likely include updates focused on consistency, security, and cost optimization in hybrid and multicloud deployments.
Follow this page for ongoing coverage of Google Cloud Next.
Google Cloud Next news
Google unveils Firebase Studio for AI app development
Google is previewing Firebase Studio, a cloud-based agentic development environment designed to build, test, deploy, and run AI applications. Firebase Studio fuses tools such as the Project IDX cloud IDE, the Genkit framework for AI applications, and Gemini in Firebase, an AI-powered collaborative assistant, into a unified, agentic experience.
Google’s BigQuery and Looker get agents to simplify analytics tasks
April 10, 2025: Google added new agents to its BigQuery data warehouse and Looker business intelligence platform to help data practitioners automate and simplify analytics tasks. The data agents include a data engineering and data science agent — both of which have been made generally available.
Cisco, Google Cloud offer enterprises new way to connect SD-WANs
April 10, 2025: Cisco and Google Cloud have expanded their partnership to integrate Cisco’s SD-WAN with the cloud provider’s fully managed Cloud WAN service. For Cisco SD-WAN customers, the integration provides a new, secure way to tie together geographically dispersed enterprise data center sites with their Google Cloud workloads using Google’s core global network backbone.
Google Cloud introduces cloud app design center
April 10, 2025: Google Cloud has introduced Application Design Center, a service that helps platform administrators and developers design, deploy, and manage applications on the Google Cloud Platform. Application Design Center is designed to provide a visual, canvas-style approach to designing and modifying application templates.
Google launches unified enterprise security platform, announces AI security agents
April 9, 2025: Google has launched a new enterprise security platform, Google Unified Security, that combines the company’s visibility, threat detection, and incident response capabilities and makes it available across networks, endpoints, cloud infrastructure, and apps.
Google to add on-demand genAI data analyst to Workspace
April 9, 2025: Google’s on-demand generative AI analyst for spreadsheets stood out among a slew of new AI features for Google Workplace productivity suite announced at Cloud Next event . The upcoming “help me analyze” feature in the Google Sheets application in Workspace is designed to take information from tables and provide instant data analysis and insights. I
Google targets AI inferencing opportunity with Ironwood chip
April 9, 2025: Google has unveiled Ironwood, a new chip that could help enterprises accelerate generative AI workloads, especially inferencing — the process used by a large language model (LLM) to generate responses to a user request.
Google’s Agent2Agent open protocol aims to connect disparate agents
April 9, 2025: Google has taken the covers off a new open protocol — Agent2Agent (A2A) — that aims to connect agents across disparate ecosystems. Google said that the A2A protocol will enable enterprises to adopt agents more readily as it bypasses the challenge of agents that are built on different vendor ecosystems.
Google adds open source framework for building agents to Vertex AI
April 9, 2025: Google is adding a new open source framework for building agents to its AI and machine learning platform Vertex AI, along with other updates to help deploy and maintain these agents. Google said the open source Agent Development Kit (ADK) will make it possible to build an AI agent in fewer than100 lines of Python code. It expects to add support for more languages later this year.
Google adds natural language query capabilities to AlloyDB
April 9, 2025: Google is enhancing AlloyDB, its managed database-as-a-service (DBaaS), to help developers build applications underpinned by generative AI. Announced at Google’s annual Cloud Next conference, the updates could give the PostreSQL-compatible AlloyDB an edge over PostgreSQL itself or other compatible offerings such as Amazon Aurora.
Related Google Cloud News
Google acquires Wiz: A win for multicloud security
Mach 25, 2025: Google’s recent acquisition of Wiz positions the tech giant as a leader ready to tackle today’s multicloud challenges, potentially outperforming competitors such as Microsoft Azure and AWS. The collaboration aims to simplify complex security architectures and underscores Google’s commitment to addressing the gaps many enterprises face when combining different cloud ecosystems.
Who needs Google technology? Probably not you
March 3, 2025: Clearly Google is doing something right. Although Google Cloud’s revenue still lags AWS and Microsoft Azure, it’s growing much faster (albeit on a smaller base). But that’s not the real story of its growth. The story is that Google Cloud is growing at all.
Six key takeaways from Google Cloud Next ’24
April 10, 2025: Generative AI was the theme at Google Cloud Next ’24, as Google rolled out new chips, software updates for AI workloads, updates to LLMs, and generative AI-based assistants for its machine learning platform Vertex AI.
Google Cloud Next 2024: AI networking gets a boost
April 10, 2024: Google announced new cloud networking capabilities that aim to help enterprises securely connect AI and multicloud workloads. The new features expand on the company’s Cross-Cloud Network service and are focused on high-speed networking for AI/ML workloads, any-to-any cloud connectivity,
Gemini Code Assist debuts at Google Cloud Next 24
April 9, 2025: Gemini Code Assist provides AI-powered code completion, code generation, and chat. It works in the Google Cloud Console, and integrates into popular code editors such as Visual Studio Code and JetBrains,
{kind=link}
What is data fabric? How it offers a unified view of your data 11 Apr 2025, 4:00 pm
What is data fabric?
Data fabric is a type of architecture that aims to provide unified access to the data stored in various places across your organization. The data fabric concept recognizes that most enterprises aren’t able or willing to consolidate every department’s valuable data into one huge data lake.
A data fabric instead serves as an abstraction layer that interacts with individual data silos, weaving together important information stored in everything from massive traditional RDBMSes to small departmental NoSQL databases. The goal is to automate data discovery and hide the details of CRUD (create, read, update, and delete) transactions from the user so they can treat your company data as one big store of information.
This is, as you can imagine, easier said than done, but valuable if you can pull it off. The term data fabric was coined in the early 2000s by an analyst at Forrester, but the folks at rival consultancy Gartner have been the ones pushing the idea of this architecture as a distinct category. The concept isn’t fully formed yet — there isn’t universal agreement on what data fabric architecture looks like, for instance, and vendor offerings billied as data fabric don’t all do the same things. In a world where organizations are trying to extract as much value as they can from their data, but despair of ever fully rationalizing their data storage situation, the idea of a fabric that can weave together data from various organizational silos is attractive.
Data fabric architecture: Key components
Broadly speaking, data fabric consists of two parts: an app or web-based front end, where users can see and configure the various sources of data, and the systems on which they reside. From this front end, users can create data models and see all their organization’s data.
The front end is interacting with a back-end engine (or engines) that power the data connection under the hood. These engines automatically keep track of the connections to data sources and available storage, sync and tune data, and so on.
Usually when people talk about data fabric architecture, they’re talking about the back end, and the components necessary to make that magic happen. As noted, there’s no single universally accepted structure for a data fabric architecture. You can check out several different takes on the subject — IBM outlines Forrester’s definition, SAP has its own ideas, and Qlik, another vendor, offers a different version.
However, there are several components that these architectures have in common and you can consider them key to any data fabric architecture:
- Data ingestion and connectivity. This layer ensures data from various sources and silos is brought into the fabric, using multiple integration patterns (data pipelines, streaming, data virtualization, and so on).
- Data processing and orchestration. This layer refines, transforms, and integrates data while automating workflows for efficiency and scalability.
- Data semantics and discovery. This layer creates a shared understanding of data across the enterprise by defining relationships, terminology, and context.
- Data management and governance. This layer ensures data is secure, well-governed, and of high quality, with strong metadata management to provide context. Ideally, the layer can make use of AI/ML-driven metadata activation, enabling automated governance, integration, and intelligent recommendations.
- Data access and consumption. This layer ensures that the right users and systems can access the data they need, via dashboards, APIs, analytics tools, and compliance-based permissions.
Why is data fabric important?
InfoWorld’s Isaac Sacolick provides a deep dive into how you know if your organization needs a data fabric. He cites three indicators that data fabric can help you:
- Your data is siloed and fragmented
- You need real-time analytics for immediate decision-making
- You’re aiming to enable generative AI and empower self-service analytics for business users
Data fabric can solve these problems by providing an abstraction layer that provides the capability to immediately access, analyze, and process your organization’s data, wherever it lives. The issues that data fabric architectures aim to solve are not new: People have been trying to figure out how to get all an organization’s data under one umbrella for literally decades. The big advantage of data fabric — what makes it special — is that you don’t have to move your data into some centralized repository, and you don’t have to convince individual groups within your organization to change too much about the way they deal with data. In theory, a data fabric provides the benefits of a unified data set without the pain of creating one.
Risks of data fabric
Data fabric shares a major risk with all new technologies that promise to cut a gordian knot that’s been bedeviling the industry for years: It may get your hopes up too much. Much of data fabric’s promises rely on its capability to discover, tag, and classify data in your various heterogenous silos automatically. “Think Google Search for your data,” gushes Datafabric.com, a site set up by data fabric vendor Promethium.
But most IT veterans know that these tools don’t always live up to their promises. Implementing a data fabric in your organization may prove overly complex, and when you finally get things up and running, you may find that the level of data integration isn’t what you hoped. You may find yourself facing the task of manually cleaning up or consolidating some of your data, which you were probably hoping to avoid.
And if your data fabric rollout is a success, that can lead to another problem: data security. If you have easy access to all your data across various clouds and silos, then so does any attacker who manages to gain access to the system where your data fabric front end runs. You need to ensure that everything is locked down so that your data fabric doesn’t offer an easy front door to those looking to access sensitive organizational information.
Data fabric use cases
IBM — a major data fabric vendor — published a case study on banks using data fabric to better understand, serve, and sell to their customers. Customer service is in general one of the big use cases for data fabric, as many companies find that data on their customers is siloed across different departments, making it difficult for them to get the big picture and insights that they believe lurk in a more unified data view.
Other big use cases for data fabric include the following:
- Healthcare, where they it can consolidate a patient’s electronic health records from multiple sources
- Manufacturing and warehousing, where it can provide data for analysis across an entire supply chain and ingest information from IoT devices
- Retail, where it can enable customer tracking and personalization across channels
Data fabric implementation steps
A technical guide to implementing a data fabric at your organization is beyond the scope of this article. But we can offer-some big-picture steps you should take as you plan your data fabric rollout and move it forward.
Pre-implementation
- Assess your current data landscape. You need to have a handle on the different places where your data lives and the forms in which it’s stored before you can start planning to connect it at all.
- Understand the business requirements. Narrowing the focus of what your organization expects from data mesh can help you get a handle on the scope of the project.
- Establish strong data governance and security policies. You probably already had these, right? Well, if you didn’t, now’s a great time to lay down the law when it comes to company data.
- Choose a cross-functional data team. These could include data engineers, analysts, scientists, and stewards from all the departments that will be affected by the rollout.
Implementation and beyond
- Roll things out in phases. Start with your most critical use cases and then expand the scope for your data fabric from there. This can give you the chance to learn how data needs to be prepared from earlier rollout phases.
- Train your end users. Your users will get on board if they understand how they can make use of data from across the enterprise — but they’ll need help understanding how to do that. Pick enthusiastic volunteers to be the leaders on their teams.
- Monitor and optimize. Keep constant track of what’s going right — and wrong —with your data fabric architecture, and with the benefits data fabric is delivering to your organization.
Top data fabric vendors
There are plenty of data fabric vendors, both big companies and specialized vendors. Review aggregator site G2 currently ranks these as the top 5:
But there are many others in this space, and things are moving fast as vendors embrace new machine learning algorithms for data processing.
{kind=link}
A multicloud experiment in agentic AI: Lessons learned 11 Apr 2025, 11:00 am
Recently I undertook a project to design and validate agentic AI architectures capable of operating autonomously across various public cloud providers. It served as a dry run to ensure I could create these architectures for my clients, test their viability, and refine best practices for multicloud agentic AI deployments.
I’ve designed agentic AI systems before but in contained or hybrid environments. This time, I focused solely on using public cloud providers to see how well these platforms would support a decentralized decision-making AI. The system needed to analyze real-time availability, cost, performance, and other factors to dynamically allocate workloads across different clouds and ensure scalability, fault tolerance, and efficiency.
Beyond being a technical experiment, this project was an invaluable learning experience. I tested the limits of today’s cloud technologies, confronted practical challenges in cross-cloud orchestration, and honed adaptive design patterns. This project solidified the foundational strategies for developing autonomous, multicloud AI solutions, and I plan to share the lessons I learned with clients and colleagues to help them create their own intelligent agentic systems. Here’s how I approached the experiment, the tools and techniques I used, the obstacles I faced, and the outcomes.
System requirements
At its core, an agentic AI system is a self-governing decision-making system. It uses AI to assign and execute tasks autonomously, responding to changing conditions while balancing cost, performance, resource availability, and other factors. I wanted to leverage multiple public cloud platforms harmoniously. The architecture would have to be flexible enough to balance cloud-specific features while achieving platform-agnostic consistency. The framework would be able to:
- Dynamically allocate workloads to the most suitable cloud provider based on real-time analysis
- Maintain fault-tolerant processes by rerouting assignments during a failure or slowdown
- Operate distributed elements with seamless communication and data flow between components hosted across different cloud platforms
Architectural components
I’m not going to mention the specific cloud providers I used or their specific tools. I do not want this to become a vendor shootout or have the core purpose of the experiment overshadowed by individuals promoting their preferred provider or tool set.
I also do not want my inbox to fill up with email from PR people upset that their clients were not considered, or frustrated if my findings do not flatter their clients’ technology. After more than 30 years of being a tech pundit and influencer, I’m a bit wary of such responses to my work. It misses the point of why I do these exercises. With that said, let’s get started.
The decision-making layer was the heart of the system. It analyzed resource metrics such as latency, cost, throughput, and storage availability. Based on these inputs, it decided where to route workloads or execute tasks. This autonomous layer was designed to:
- Assess the current state of resources across clouds
- Prioritize tasks and allocate them to the most appropriate environment
- Detect issues (e.g., bottlenecks or service failures) and adapt in real time
These goals were achieved by implementing modular AI capabilities that could dynamically assess cloud environments and adjust resource allocation. The workloads had to be containerized and portable, ensuring they could run on different platforms without modification.
An orchestration layer was essential to deploy, scale, and manage these containers across clouds. The orchestration system would:
- Deploy workloads based on AI-generated decisions
- Monitor resource usage and performance to refine the AI’s decisions
- Automatically scale to accommodate fluctuating workloads across environments
A communication layer allowed services running in different clouds to interact seamlessly and ensured effective coordination across environments. Data consistency across providers was maintained via distributed storage mechanisms, where data was replicated, cached, or synchronized depending on use-case requirements.
A monitoring and observability framework allowed the system to function autonomously. As real-time visibility into performance was critical, the observability layer tracked several metrics and fed this information back into the core AI system to improve decision-making over time. This layer collected data on:
- Task execution performance
- Cloud-specific anomalies or bottlenecks
- Cost trends and resource consumption across all environments
The development process
The first step was to provision infrastructure across several cloud providers. Using an infrastructure-as-code approach, I deployed virtual networks, container orchestration environments, and storage solutions in each platform. Achieving connectivity between these environments required careful networking, such as configuring secure tunnels and peering connections to enable low-latency, cross-provider communication.
The AI core needed to be both intelligent and adaptable. I trained the models on simulated resource data to ensure they could make reliable decisions about workload routing. Deploying the AI logic as light, stateless services ensured scalability and allowed easy updates when models evolved.
The orchestration layer was tightly integrated with the AI core to enable dynamic decision-making. For example, when faced with heavy demand, the system could spin up additional resources in one cloud to offset latency in another. Likewise, workloads were seamlessly routed to alternate locations if one provider encountered downtime.
One of the most critical stages was stress-testing the system. I simulated everything from partial outages to full platform failures. For example, when a server cluster in one cloud went offline, the system redirected processing jobs to resources in another without losing data or state. These scenarios exposed weaknesses, such as inconsistent response times during failover, which I remediated by optimizing workload reprioritization.
Challenges and solutions
Connecting workloads across clouds presented significant hurdles. Latency, security, and compatibility issues required fine-tuning network architectures. I implemented a combination of secure tunnels and overlay networks to improve data exchange reliability.
Tracking costs across clouds was another challenge. Each provider’s billing models were unique, making predicting and optimizing expenses difficult. I integrated APIs to pull real-time cost data into a unified dashboard, which allowed the AI system to include budget considerations in its decisions.
Cloud-specific variances sometimes caused misalignments, despite efforts to standardize deployments. For example, storage solutions handled certain operations differently across platforms, leading to occasional inconsistencies in how data was synchronized and retrieved. I resolved this by adopting hybrid storage models that abstracted platform-specific traits.
Autoscaling wasn’t consistent across environments, and some providers took longer than others to respond to bursts of demand. Tuning resource limits and improving orchestration logic helped reduce delays during unexpected scaling events.
Key takeaways
This experiment reinforced what I already knew: Agentic AI in multicloud is feasible with the right design and tools, and autonomous systems can successfully navigate the complexities of operating across multiple cloud providers. This architecture has excellent potential for more advanced use cases, including distributed AI pipelines, edge computing, and hybrid cloud integration.
However, challenges with interoperability, platform-specific nuances, and cost optimization remain. More work is needed to improve the viability of multicloud architectures. The big gotcha is that the cost was surprisingly high. The price of resource usage on public cloud providers, egress fees, and other expenses seemed to spring up unannounced. Using public clouds for agentic AI deployments may be too expensive for many organizations and push them to cheaper on-prem alternatives, including private clouds, managed services providers, and colocation providers. I can tell you firsthand that those platforms are more affordable in today’s market and provide many of the same services and tools.
This experiment was a small but meaningful step toward realizing a future where cloud environments serve as dynamic, self-managing ecosystems. Current technologies are powerful, but the challenges I encountered underscore the need for better tools and standards to simplify multicloud deployments. Also, in many instances, this approach is simply cost-prohibitive. What’s my overall recommendation? This is another “it depends” answer that people love to hate.
{kind=link}
More and faster: New proposals changing Python from within 11 Apr 2025, 11:00 am
Top picks for Python readers on InfoWorld
Making Python faster won’t be easy, but it’ll be worth it
Python’s malleability and dynamism make it powerful, but also very hard to speed up. Here’s a look at some of the ways developers are working to make Python faster from within.
Understand Python’s new lock file format
Lock files for project dependencies have long been missing from Python, but that’s about to change. Here’s what you need to know about using the new common lock file format in your Python projects.
The power of Python’s editable package installations
Want to unlock a new superpower for working with Python packages? Here’s how to install a package, edit changes to the source, and have the changes show up automatically wherever it’s installed.
Exploring new features in Cython 3.1
The next version of the Python-to-C compilation tool isn’t quite out yet, but you can get a head start on all its powerful new features, including support for Python’s free-threaded/“no-GIL” build.
More good reads and Python updates elsewhere
Is Python code sensitive to CPU caching?
You might think Python’s too high-level for CPU caches to matter, but Lukas Atkinson’s research reveals something different.
NVIDIA adds native Python support to CUDA with cuda.core
This latest addition to NVIDIA’s CUDA toolkit lets you plug straight into CUDA on supported systems with a single pip install. (Also see the discussion at The New Stack.)
How to run PyTorch on the free-threaded builds of Python
Here’s how to achieve faster inference for PyTorch models—and by an order of magnitude in this case! It’s all thanks to Python’s new “no-GIL” build.
Just for fun: How C code becomes assembly
It isn’t always obvious how C maps to assembly, but this deep dive into the Clang/LLVM compiler system will take you there.
{kind=link}
Grok 3 gets an API — but will enterprises trust it? 11 Apr 2025, 10:51 am
Once just a chatbot, xAI’s Grok 3 large language model family is now available in a beta version via an API, enabling developers to integrate Grok 3 into custom applications.
The company is offering two new LLMS, one with deep domain knowledge in finance, healthcare, law, and science, and a lightweight model without domain knowledge but with the ability to show how it thinks about its answers. A faster version of each model is available for an additional fee.
Like all AI models, their adoption is tempered by security concerns such as their vulnerability to adversarial inputs.
The API supports multimodal capabilities, including image analysis, and aligns with developer-friendly standards similar to OpenAI’s and Anthropic’s frameworks.
The context window — how much information the model can process at once — for all versions of the Grok 3 API is capped at 131,072 tokens.
Pricing is $3 per million input tokens and $15 per million output tokens for grok-3-beta, the model with deep domain knowledge, or $5 and $25, respectively, for its faster sibling. For grok-3-mini-beta, the model with reasoning capabilities, pricing is $0.30 per million input tokens and $0.50 per million output tokens (or $0.60 and $4, respectively, for the faster version).
In comparison, the charge for the older grok-2 API is $2 per million input tokens and $10 per million output tokens.
Security questions
However, as enterprises consider adopting this technology, cybersecurity leaders are raising urgent questions about its risks and readiness for business use. The Grok 3 API arrives with bold promises like advanced reasoning capabilities, real-time web search through DeepSearch, and multimodal processing. When Musk first launched Grok he wanted to position it as the “anti-woke” alternative to more filtered AI systems, claiming it offered greater transparency and less restrictive responses.
However, this approach is causing concerns among CISOs evaluating the technology.
“Before an AI model like this is approved for use, a rigorous vetting process would be essential,” said Dina Saada, cybersecurity analyst and member of Women in Cybersecurity Middle East (WISCME). “From an intelligence standpoint, this would involve multiple layers of testing such as code reviews for vulnerabilities, penetration testing, behavioral analysis under stress conditions, and compliance checks against security standards.”
“To earn trust, xAI must show two things: first, transparency and second, resilience,” Saada added.
Musk’s team at xAI faces an important task in the coming months. While the Grok 3 API showcases promising capabilities, it presents an opportunity to assure enterprises that xAI can meet their expectations for model integrity and reliability.
Enterprise adoption will depend on it demonstrating robust model integrity and reliability alongside technical performance. While developers have already tested Grok 3’s capabilities for weeks through existing chat interfaces, the API’s scalability and adherence to enterprise-grade security protocols will determine its viability for large organizations.
{kind=link}
Page processed in 1.706 seconds.
Powered by SimplePie 1.3.1, Build 20121030095402. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.