Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
JDK 25: The new features in Java 25 | InfoWorld
Technology insight for the enterpriseJDK 25: The new features in Java 25 14 Mar 2025, 11:52 pm
Java Development Kit (JDK) 25, a planned long-term support release of standard Java due in September, now has two features officially proposed for it. The first is a preview of an API for stable values, a feature that promises to speed up the startup of Java applications. The second is the removal of the previously deprecated 32-bit x86 port.
JDK 25 comes on the heels of JDK 24, a six-month-support release due to arrive March 18. As a long-term support release, JDK 25 is set to get at least five years of premier-level support from Oracle.
Stable values are objects that hold immutable data. Because stable values are treated as constants by the JVM, they enable the same performance optimizations that are enabled by declaring a field final. But compared to final fields, stable values offer greater flexibility as to the timing of their initialization. A chief goal of the proposal is improving the startup of Java applications by breaking up the monolithic initialization of application state. Other goals include enabling user code to safely enjoy constant-folding optimizations previously available only to JDK code; guaranteeing that stable values are initialized at most once, even in multi-threaded programs; and decoupling the creation of stable values from their initialization, without significant performance penalties.
Removal of the 32-bit x86 port, currently proposed to target JDK 25, involves removing both the source code and build support for this port, which was deprecated for removal in JDK 24. In explaining the motivation, the JEP states that the cost of maintaining this port outweighs the benefits. Keeping parity with new features, such as the foreign function memory API, is a major opportunity cost, according to the JEP. Deprecating and removing the port will allow OpenJDK developers to accelerate development of new features and enhancements.
Other features that could find a home in JDK 25 include the features previewed in JDK 24, such as a key derivation function API, scoped values, structured concurrency, flexible constructor bodies, and module import declarations.
{kind=link}
Stupendous Python stunts without a net 14 Mar 2025, 6:35 pm
In this week’s Python Report: Sly tricks for setting up Python on a machine with no network, snappier Python code with asyncand await, swifter Python programs with Zig, and slicker web apps with HTMX and Django.
Top picks for Python readers on InfoWorld
Air-gapped Python: Setting up Python without a net(work)
Flaky connection? No connection at all? Air gapped by design? You can still get Python, and Python packages, set up and running with a little juggling.
Get started with async in Python
Speaking of juggling… Do you want to interleave tasks in Python more efficiently without threads or multiple processes? Python’s async and await help you get more done in less time.
How to boost Python program performance with Zig
Old and venerable Python meets the hot new Zig, and both win. See how you can write fast, machine-native code with Zig, and wrap it in Python for ease and convenience.
Dynamic web apps with HTMX, Python, and Django
Use HTMX to give HTML the easy interactivity it always needed. Combine HTMX with Python and its super-powered Django framework, and you’ve got a web stack to beat them all.
More good reads and Python updates elsewhere
Proposed Linux kernel patches would allow access to libperf from Python
Imagine having access to a low-level Linux subsystem through a Python library—one supported natively by the Linux kernel. IBM’s proposal prepares to make that happen.
Fastplotlib: Interactive plotting in Python powered by the GPU
Create snappy, live-updating graphs and plots that can run in a variety of contexts (Jupyter notebooks, PyQt-powered windows, and more). The current release is considered a late alpha, but you’re encouraged to give it a whirl outside production.
A map of Python
A highly granular, interactive map of the package dependencies on PyPI, along with details about how to generate the same sort of interactive graph from a similarly sprawling data set. (Caution: Don’t try to plot everything!)
An oral history of Bank Python
How Python has been used, in proprietary forks, by various investment firms. Prepare to be stupefied at the flagrant abuse of Python’s object system and at the bizarre, proprietary data structures, like pre-Pandas tables.
{kind=link}
What is Llama? Meta AI’s family of large language models explained 14 Mar 2025, 10:00 am
Llama, a family of sort-of open-source large language models (LLMs), was introduced in February 2023, and has been updated periodically ever since. Llama shook up the world of LLMs, which had previously been dominated by ever-larger closed-source models from OpenAI and Google. With Llama, Meta AI touted the fact that smaller generic models trained on more tokens are easier and cheaper to use for retraining and fine-tuning specialized models than huge models.
Why do I say “sort-of open-source?” It’s because the Meta Llama license has restrictions on commercial use (aimed at large, for-profit organizations, such as AWS, Google Cloud, and Microsoft Azure) and acceptable use (forbidding it, for example, from being used to develop weapons or drugs). They’re reasonable restrictions, but the Open Source Initiative maintains that they violate the official definition of open source.
I discussed the Llama 2 models in September 2023. I also explored the use of Llama Chat and Code Llama for code generation.
Meta Llama lawsuits
Two class action lawsuits were filed by authors against Meta in 2023 claiming misuse of their copyrighted books as training material for Llama. The courts haven’t been terribly sympathetic to the authors. The first case, Kadrey et al. v. Meta Platforms, was filed in July 2023. The second, Chabon v. Meta Platforms, was filed in September 2023. The two cases were combined, and the combined case was dismissed on all but one count, direct copyright violation, in December 2023. It still dragged on with amended complaints for another year; in September 2024 the judge ordered “Based on previous filings, the Court has been under the impression that there’s no real dispute about whether Meta fed copyrighted works to its AI programs without authorization, and that the only real legal question to be presented at summary judgment is whether doing so constituted ‘fair use’ within the meaning of copyright law.” Summary judgement was scheduled for March 2025, although there has been plenty of activity from both sides through February 2025.
Meta Llama models (since Llama 2)
Below I’ll discuss the progress Meta AI has made with the Llama family of models since the fall of 2023. Note that they’re no longer just language models. Some models are multi-modal (text and vision inputs, text output), and some can interpret code and call tools. In addition, some Llama models are safety components that identify and mitigate attacks, designed to be used as part of a Llama Stack. The following model write-ups are condensed from Meta AI’s model cards.
Llama Guard 1
Llama Guard is a 7B parameter Llama 2-based input-output safeguard model. It can be used for classifying content in both LLM inputs (prompt classification) and in LLM responses (response classification).
The six-level taxonomy of harms used by Llama Guard is Violence & Hate; Sexual Content; Guns & Illegal Weapons; Regulated or Controlled Substances; Suicide & Self Harm; and Criminal Planning.
Model release date: December 13, 2023
Code Llama 70B
With the introduction of Code Llama 70B, Code Llama comes in three variants:
- Code Llama: Base models designed for general code synthesis and understanding.
- Code Llama – Python: Models designed specifically for Python.
- Code Llama – Instruct: Models designed for following instructions and safer deployment.
All variants are available in sizes of 7B, 13B, 34B, and 70B parameters. Code Llama and its variants are intended for commercial and research use in English and relevant programming languages. Code Llama is indeed good at coding; see my review.
Model release date: January 29, 2024
Llama Guard 2
Llama Guard 2 is an 8B parameter Llama 3-based LLM safeguard model. The model is trained to predict safety labels on 11 categories, based on the MLCommons taxonomy of hazards.
Hazard categories
| S1: Violent Crimes | S2: Non-Violent Crimes |
| S3: Sex-Related Crimes | S4: Child Sexual Exploitation |
| S5: Specialized Advice | S6: Privacy |
| S7: Intellectual Property | S8: Indiscriminate Weapons |
| S9: Hate | S10: Suicide & Self-Harm |
| S11: Sexual Content |
Model release date: April 18, 2024
Meta Llama 3
Meta Llama 3 comes in two sizes, 8B and 70B parameters, in pre-trained and instruction-tuned variants. Instruction-tuned models are optimized for dialogue.
Model release date: April 18, 2024
Prompt Guard
Prompt Guard is a classifier model that is capable of detecting both explicitly malicious prompts (jailbreaks) and prompts that contain injected inputs (prompt injections). Meta AI suggests fine-tuning the model to application-specific data to achieve optimal results.
Prompt Guard is a BERT model that outputs only labels. Unlike Llama Guard, Prompt Guard doesn’t need a specific prompt structure or configuration. The input is a string that the model labels as safe or unsafe (at two different levels).
Model release date: July 23, 2024
Llama Guard 3
Llama Guard 3 comes in three flavors: Llama Guard 3 1B, Llama Guard 3 8B and Llama Guard 3 11B-Vision. The first two models are text only. The third supports the same vision understanding capabilities as the base Llama 3.2 11B-Vision model. All the models are multi-lingual (for text-only prompts) and follow the categories defined by the MLCommons consortium.
You can use Llama Guard 3 8B for category S14 Code Interpreter Abuse. Note the Llama Guard 3 1B model was not optimized for this category.
Hazard categories
| S1: Violent Crimes | S2: Non-Violent Crimes |
| S3: Sex-Related Crimes | S4: Child Sexual Exploitation |
| S5: Defamation | S6: Specialized Advice |
| S7: Privacy | S8: Intellectual Property |
| S9: Indiscriminate Weapons | S10: Hate |
| S11: Suicide & Self-Harm | S12: Sexual Content |
| S13: Elections | S14: Code Interpreter Abuse |
Model release date: July 23, 2024
Meta Llama 3.1
The Meta Llama 3.1 collection of multi-lingual large language models includes pre-trained and instruction-tuned generative models in 8B, 70B, and 405B sizes (text in, text out).
Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
Model release date: July 23, 2024
Meta Llama 3.2
The Llama 3.2 collection of multi-lingual large language models is a collection of pre-trained and instruction-tuned generative models in 1B and 3B sizes (text in, text out). There are also quantized versions of these models. The Llama 3.2 instruction-tuned text-only models are optimized for multi-lingual dialogue use cases, including agentic retrieval and summarization tasks. Llama 3.2 1B and 3B models are smaller and less capable derivatives of Llama 3.1.
Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. Note that Llama 3.2 has been trained on a broader collection of languages than these eight officially supported languages.
Model release date: October 24, 2024
Llama 3.2-Vision
The Llama 3.2-Vision collection of multi-modal large language models is a collection of pre-trained and instruction-tuned image reasoning generative models in 11B and 90B sizes (text and images in, text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image.
Supported languages: For text only tasks, English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported. Llama 3.2 has been trained on a broader collection of languages than these eight supported languages. Note that for image+text applications, English is the only language supported.
Model release date: September 25, 2024
Meta Llama 3.3
The Meta Llama 3.3 multi-lingual large language model is a pre-trained and instruction-tuned generative model in 70B (text in, text out).
Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
Model release date: December 6, 2024
Large language models, including Llama 3.2, are not designed to be deployed in isolation but instead should be deployed as part of an overall AI system with additional safety guardrails as required. Developers are expected to deploy system safeguards when building agentic systems.
Llama 3.3, Llama 3.2 text-only models, and Llama 3.1 support the following built-in tools:
- Brave Search: A tool call to perform web searches.
- Wolfram Alpha: A tool call to perform complex mathematical calculations.
- Code Interpreter: A tool call that enables the model to output python code.
Note the Llama 3.2 vision models don’t support tool calling with text+image inputs.
The Llama Stack
At this point, you may be confused about which of the many Llama models to use for any given application and environment, and how they all fit together. You may find the Llama Stack (see block diagram below) helpful and useful. While Llama Stack emphasizes Llama models, it also provides adapters to related capabilities, such as vector databases for retrieval-augmented generation (RAG).
Llama Stack currently supports SDKs in Python, Swift, Node, and Kotlin. There are a number of distributions you can use, including a local distribution using Ollama, on-device distributions for iOS and Android, distributions for GPUs, and remote-hosted distributions at Together and Fireworks. The general idea is that you can develop locally and then switch to a production end-point easily. You can even run an interactive Llama Stack Playground locally against a remote Llama Stack.
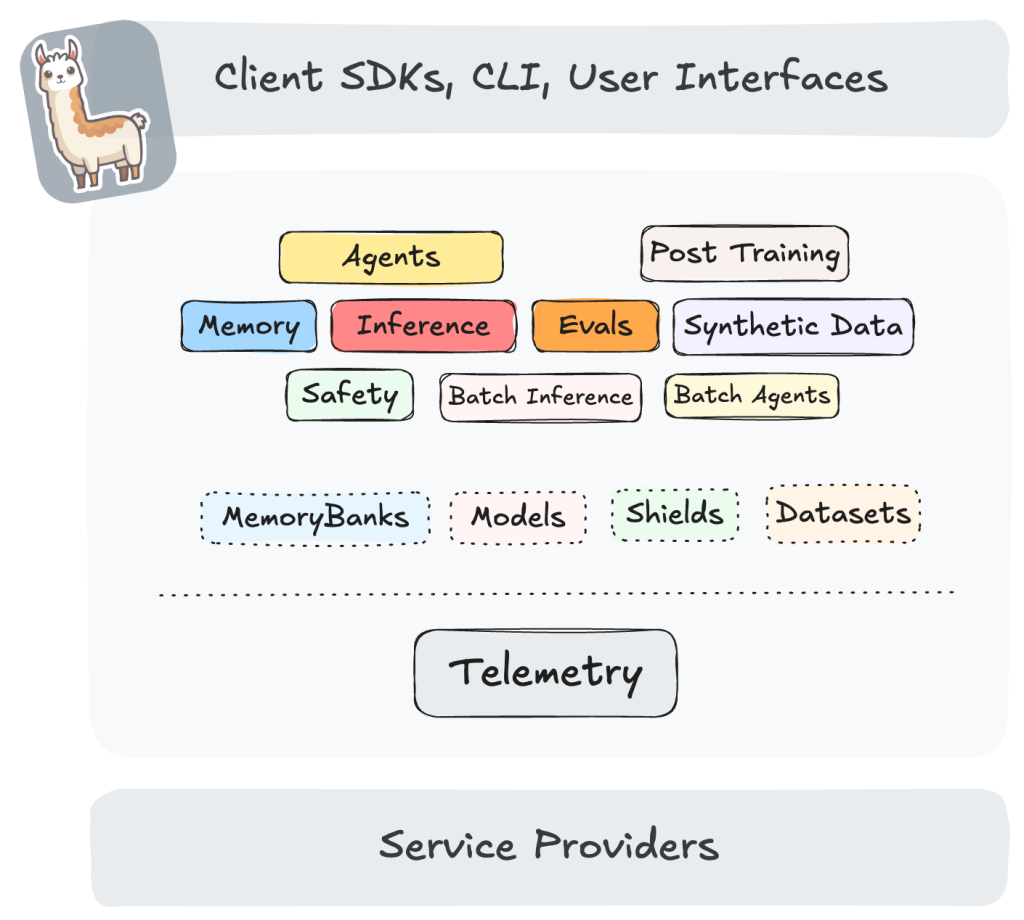
Meta AI’s Llama stack.
Meta AI
Running Llama Models
You can run Llama models on Linux, Windows, macOS, and in the cloud. I’ve had good luck running quantized Llama models on a M4 Pro MacBook Pro using Ollama, specifically Llama 3.2 and Llama 3.2-Vision.
It’s worth going through the Llama how-to guides. If you like the LangChain or LlamaIndex frameworks, the Llama integration guides will be helpful.
Llama has evolved beyond a simple language model into a multi-modal AI framework with safety features, code generation, and multi-lingual support. Meta’s ecosystem enables flexible deployment across different platforms, but there are some ongoing legal disputes over training data, and disputes over whether Llama is open source.
{kind=link}
IT leaders are driving a new cloud computing era 14 Mar 2025, 10:00 am
At fictional Tech Innovations Inc., a midsize software company, the rapid adoption of cloud technology was once seen as a transformative stepping stone toward agility and scalability. Initially, the company migrated its applications to a well-known public cloud provider, captivated by promises of cost savings and effortless management. However, just months into their cloud journey, it became apparent that the financial forecasts were overly optimistic.
Unexpected data transfer fees. Tiered storage expenses. Projects that required compliance with stringent data regulations. As a result, Tech Innovations’ CIO Martha Lee found herself in a predicament. Forced to explore alternative approaches and vendors, she realized the need for a paradigm shift in the company’s cloud strategy.
Like Martha, many of today’s CIOs and IT leaders are reevaluating the role of traditional cloud service providers. Public clouds from major players such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud have been instrumental in driving digital transformation, but many organizations are now pushing back against these giants.
The gradual realization that cloud providers might not deliver on their initial promises created a ripple effect across industries. Leadership teams are now aware that the idyllic visions of great savings and seamless scalability often fall short of reality, especially when unexpected costs come into play.
The surprise costs of cloud
Although cloud computing is generally marketed as a cost-effective solution, this is typically far from reality. As noted in recent findings from various sectors, organizations are blindsided by complex pricing structures, including data retrieval charges, inter-zone transfer fees, and evolving storage needs.
Tech Innovations Inc., is a fictional stand-in for a lot of very real companies that have encountered these hidden costs. Most enterprises watched cloud expenses climb at an alarming rate before they realized the implications of their spending.
CIOs have become increasingly frustrated with vendor pricing models that lock them into unpredictable and often unfavorable long-term commitments. Many find that mounting operational costs frequently outweigh the promised savings from cloud computing. It’s no wonder that leadership teams are beginning to shift gears, discussing alternative solutions that might better serve their best interests.
Popular cloud alternatives
As cloud dependence begins to decline, we see alternative options on the rise. Managed service providers (MSPs) and colocation services are becoming increasingly relevant. These alternatives offer organizations more control over their infrastructure while avoiding the relentless surges in pricing tied to major cloud providers.
MSPs provide a comprehensive suite of services that support organizations in managing their cloud environments, ensuring that costs remain predictable through tailored, flat-rate plans. Colocation services enable businesses to house their servers in third-party facilities, granting them more autonomy over hardware and corresponding expenses. Companies avoid excessive fees while maintaining compliance and security standards by resuming direct control over key hardware components.
Alongside traditional alternatives, specialized public cloud providers have gained traction. Players like CoreWeave are carving out niches, such as machine learning or rendering workloads. They emphasize flexibility and price over the more generic offerings from major players. Their bespoke cloud solutions allow organizations to choose services tailored to their operational demands rather than conforming to the one-size-fits-all approach that larger cloud providers may impose.
Regional or sovereign clouds offer significant advantages, including compliance with local data regulations that ensure data sovereignty while meeting industry standards. They reduce latency by placing data centers nearer to users, enhancing service performance. Security is also bolstered, as these clouds can apply customized protection measures against specific threats.
Additionally, regional clouds provide customized services that cater to local needs and industries and offer more responsive customer support than larger global providers. This combination of benefits makes regional clouds an appealing alternative for organizations seeking agility and security in their IT infrastructures.
Strategic reevaluation
Amidst this multitude of options, the narrative among CIOs is evolving. They are carefully evaluating their current cloud strategies and questioning whether the advantages of traditional cloud providers still surpass the drawbacks. A strategic reassessment typically includes audit-like evaluations of current operations that balance the actual costs with productivity gains and compliance needs.
Furthermore, IT leaders must recognize the importance of both flexibility and integration. Organizations aiming to optimize costs can explore hybrid models that combine the benefits of on-premises resources with the scalability of the cloud, allowing them to refine their strategies.
The changing perspective of CIOs and IT leaders is part of a broader transformation within the IT landscape. The pushback against traditional cloud providers is not driven only by unexpected costs; it also reflects enterprise demand for greater autonomy, flexibility, and a skillfully managed approach to technology infrastructure. Effectively navigating the complexities of cloud computing will require organizations to reassess their dependencies and stay vigilant in seeking solutions that align with their growth strategies.
The future depends not on an unwavering reliance on a single cloud vendor but on the willingness to adapt and explore diverse options that enhance operational efficiency while optimizing costs. At this critical juncture, organizations that embrace such changes will emerge resilient and positioned for sustained success in the ever-evolving digital marketplace. Cloud computing is here to stay, but service providers must adapt to meet the new demands of their clients—an evolution that now promises a sea change in the industry.
{kind=link}
Java hiring plans slip, survey says 14 Mar 2025, 3:51 am
Slightly more than half of Java shops surveyed (51%) have plans to add more Java developers in the coming year, down from 60% in 2024, according to a report by Perforce, a provider of Java development and devops tools. And while 34% plan to increase the Java tool budget in 2025, that compares to 42% that planned to do so in 2024.
These findings were cited in the company’s 2025 Java Developer Productivity Report, published March 4. Perforce, which offers the JRebel Java development tool, this year surveyed 731 developers, team leads, managers, and executives who work in the Java realm. While 51% said they planned to add Java developers in 2025, 16% had no plans to add to developer headcount and 32% were unsure. Thirty-four percent planned to increase the Java tool budget this year, compared to 42% last year.
In other findings, only 12% of respondents said they do not use AI tools, while 12% responded that their companies do not allow tje use of AI tools. Top AI tools among respondents included “generic juggernaut“ ChatGPT (used by 52%) and GitHub Copilot (used by 42%), with IDE-integrated AI tools trailing (used by 25%). Developers were most likely to turn to AI tools for code completion (60%) and refactoring (39%). Error detection (30%), documentation generation (28%), debugging assistance (26%), and automated testing (21%) were also cited as common use cases.
Elsewhere in the 2025 Java Developer Productivity Report:
- 61% of respondents use Java 17, 45% use Java 21, 35% use Java 8, and 32% use Java 11. These are the four most recent long-term support releases.
- 72% reported using Oracle distributions that are no longer supported including Java 11 and Java 8.
- For main applications, use of Java 17 led the way at 61% while use of Java 7 or older was only 5%. Respondents also reported using Kotlin (10%), Groovy (7%), and Scala (3%) for their main applications.
- For primary JRE/JDK (Java Runtime Environment/Java Development Kit) distribution, Oracle led the way at 42%, followed by OpenJDK at 35%, AdoptOpenJDK/Adoptium at 24%, Amazon Corretto at 23%, and Azul Zulu at 12%.
- For Java IDE, JetBrains IntelliJ was tops at 84%, followed by Visual Studio Code at 31% and Eclipse at 28%. Eclipse notched 39% a year ago.
{kind=link}
How DeepSeek innovated large language models 13 Mar 2025, 10:00 am
The release of DeepSeek roiled the world of generative AI last month, leaving engineers and developers wondering how the company achieved what it did, and how they might take advantage of the technology in their own technology stacks.
The DeepSeek team built on developments that were already known in the AI community but had not been fully applied. The result is a model that appears to be comparable in performance to leading models like Meta’s Llama 3.1, but was built and trained at a fraction of the cost.
[ Related: More DeepSeek news and analysis ]
Most importantly, DeepSeek released its work as open access technology, which means others can learn from it and create a far more competitive market for large language models (LLMs) and related technologies.
Here’s a glimpse at how DeepSeek achieved its breakthroughs, and what organizations must do to take advantage of such innovations when they emerge so quickly.
Inside the DeepSeek models
DeepSeek released two models in late December and late January: DeepSeek V3, a powerful foundational model comparable in scale to GPT-4; and DeepSeek R1, designed specifically for complex reasoning and based on the V3 foundation. Here’s a look at the technical strategy for each.
DeepSeek V3
- New mix for precision training: DeepSeek leveraged eight-bit precision matrix multiplication for faster operations, while implementing custom logic to accumulate results with the correct precision. They also utilized WGMMA parallel operators (pronounced “wagamama”).
- Taking multi-token prediction to the next level: Clearly inspired by Meta’s French research team, which pioneered predicting multiple tokens simultaneously, DeepSeek utilized enhanced implementation techniques to push this concept even further.
- Expert use of “common knowledge”: The basic concept of Mixture-of-Experts (MoE) is akin to activating different parts of the brain based on the task—just as humans conserve energy by engaging only the necessary neural circuits. Traditional MoE models split the network into a limited number of “experts” (e.g., eight experts) and activate only one or two per query. DeepSeek introduced a far more granular approach, incorporating an idea originally explored by Microsoft Research—the notion that some “common knowledge” needs to be processed by model components that remain active at all times.
DeepSeek R1
- Rewarding reasoning at scale: Much like AlphaGo Zero learned to play Go solely from game rules, DeepSeek R1 Zero learns how to reason from a basic reward model—a first at this scale. While the concept isn’t new, successfully applying it to a large-scale model is unprecedented. DeepSeek’s research captures some profound moments, such as the “aha moment” when DeepSeek R1 Zero realized on its own that spending more time thinking leads to better answers (I wish I knew how to teach that).
- Curating a “cold start”: The DeepSeek R1 model also leverages a more traditional approach, incorporating cold-start data from DeepSeek V3. While no groundbreaking techniques seem to be involved at this stage, patience and meticulous curation likely played a crucial role in making it work.
These DeepSeek advances are a testament to open research, and how it can help the progress of humankind. One of the most interesting next steps? The great team at Hugging Face is already working to reproduce DeepSeek R1 in its Open R1 project.
The importance of LLM agnosticism
The limiting factor for AI will not be uncovering business value or model quality. What is critical is that companies maintain an agnostic strategy with their AI partners.
DeepSeek shows that betting on a single LLM provider will be a losing game. Some organizations have locked themselves into a single vendor, whether OpenAI, Anthropic, or Mistral. But the ability of new players to disrupt the landscape in a single weekend makes it clear: companies need an LLM-agnostic approach.
A multi-LLM infrastructure avoids the dangers of vendor “lock-in” and makes it easier to integrate and switch between models as the market evolves. Essentially, this future-proofs any LLM decision by ensuring optionality through a company’s AI journey.
Enterprises must also maintain control through careful governance. DeepSeek and the fast-emerging world of agentic AI show how chaotic and fast-moving the AI landscape has become. In a world of open-source reasoning models and rapidly multiplying vendors, engineering teams will need to maintain rigorous testing, robust guardrails, and continuous monitoring.
If you can meet these needs, technologies like Deepseek will be a huge positive for all businesses by increasing competition, driving down costs, and opening new use cases that more companies can capitalize on.
Florian Douetteau is co-founder and CEO of Dataiku, the universal AI platform that provides the world’s largest companies with control over their AI talent, processes, and technologies to unleash the creation of analytics, models, and agents.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
{kind=link}
Speeding up .NET application development with Uno Studio 13 Mar 2025, 10:00 am
Developer productivity is one of those topics that never goes away. How can we not only make it easier to deliver code but also make that code more reliable and resilient? As a result, we’re seeing something of a renaissance in developer tools, from AI-based pair programming to low-level refactoring services, and even better ways of highlighting both syntax and errors before we’ve even started to run a compiler or a debugger.
We’ve seen a lot of new tools from advances in compilers and languages; .NET’s Roslyn compiler allows editors to examine what code will do, line by line, as you write it. At the same time, it allows developers to edit code as it’s being debugged so you can evaluate fixes or try novel approaches without having to switch context. It’s a more efficient way to work, using debugging tools at the same time as an editor, so you can see your code in a live application while you’re writing it.
This is an excellent way of working with business logic, but it doesn’t work well with a control-based layout tool such as XAML. Here you’re working with interactions between code and layout, both working through different sets of tools in the same IDE. With layout prerendered, you’re unable to use the default hot-reload tools to change design on the fly.
This puts a blocker on developer collaborations with designers. There’s no way to have the same type of pair-programming relationship where both disciplines can update a running application at the same time and see the effects on user experience and the back-end code that drives that experience. No matter what changes need to be made, whether something as small as changing a font size or as big as adding a whole new view, code needs to be passed from developer to designer and back again each time a change needs to be made. This slows down development and forces both sides to stop and start, breaking flow and switching contexts.
Bringing live development to design
Back in the early days of the web, Dreamweaver and other tools pioneered live page design, showing how a page would look to a user as you edited its layout. Today’s application development world has some of that capability through tools like Visual Studio’s Expression Blend XAML designer, but there is still a gap between the tools used by designers and by developers.
How can we allow designers and developers to work on code and design at the same time on the same screen, making changes to live applications as they’re running? Working with separate design-time tools has one big flaw—you’re never using live data. There’s often a need for developers to extract a set of placeholder data and build mock APIs so that designers can at least get a feel for what a running application should contain.
Hot Design in Uno Studio
The team behind the cross-platform Uno .NET tool recently announced a possible solution: the new Hot Design tool, shipping as part of Uno Studio. This brings a similar experience of Microsoft’s code-centric .NET dynamic development tools to XAML UI development. Instead of going through a long development/design cycle to update code, designers and developers can collaborate on quick edits to XAML layouts while debugging and testing code.
The new Hot Design tool allows you to inject new XAML code into a running application, opening a design tool inside your running application and letting you change the parameters and properties of the controls in a view. There’s no need to back out of your code either; you can be deep inside a stack and still edit the design of the current page.
The tool is part of the Uno Studio libraries, so when you’re debugging code with it enabled, a small overlay icon in your application title bar can be clicked to open the Hot Design view. This replaces the application window, giving you tools to navigate the control tree or simply select a control for editing from the application canvas. When the Hot Design window is active, the application is paused (much like using a debugger breakpoint), so you don’t have to contend with a live UI.
Uno calls this the Heads-Up Display, and it gives you access to the complete control hierarchy, starting with the window and going down to individual text items and more. The tool is only active when you’re running inside a debug environment, so there’s no worry about it activating when code is compiled and shipped, as it’s removed by the build process.
Changes made in the Hot Design tool are reflected in the application XAML. At the same time, if you’re editing the XAML in Blend or Visual Studio, any changes can be shown via the Hot Design process in the context of the application you’re building. The idea is to have a two-way process that lets designers and developers work in the tools they prefer. This matches well with Microsoft’s philosophy of going to where the developers are.
At the same time, you can use the Hot Load tools to change the underlying C# code, tying new data sources to grid controls and working with data bindings at the same time the design is being modified to fit new fields and controls. Maybe you’re adding a gallery to a shopping application or new, richer inputs and outputs to a customer support platform. You’re not limited to the built-in Uno WinUI 3 controls; you can use your own custom controls as well.
Getting started with Hot Design
Uno recently made a preview of its Hot Design tool available to any registered user, even those with a free account. I decided to give it a spin in a Windows desktop application in Visual Studio.
There are a lot of prerequisites before you can get started, but a simple command line tool checks for missing requirements and then tries to install them where necessary. For my development PC that meant ensuring that the latest version of Microsoft’s JDK and Google’s Android developer tool were installed and that I had the right version of Visual Studio with the correct workloads configured.
The uno-check tool is installed via the .NET command line and, once installed, you can run it from the same terminal. You may need a couple of reboots to ensure everything is in place. There was one requirement that uno-check couldn’t automate: installing an Android device emulator. You need to do this from inside Visual Studio, which launches the official Android device manager so you can quickly set up a local virtual machine (in my case, a Pixel 8 Pro running x64 code).
With everything in place, you can install the Uno Platform tool from the Visual Studio Marketplace. Installation can take a little time and requires restarting the IDE. Once installed, the Uno extension adds application templates and the Hot Reload and Hot Design plug-ins, ready for use. Initial code can be built from Uno’s web site.
If you haven’t logged into your Uno account from Visual Studio, you’re now prompted to do so. This gives both free and paid users access to the core Uno Studio services, with paid users able to use the platform’s Figma integration.
Once the tool is installed and you’ve started working in an Uno template, you can add some code. I built a basic two-view application that had an input box in one view and a text area to display my input in the second. To launch Hot Design, I simply set the target environment to desktop and launched the Visual Studio debugger. To switch to the Hot Design view, I clicked the icon in the Uno toolbar and started editing.
Having tools like this in Visual Studio (and VS Code and other .NET development tools) is a good way to speed up the developer/designer loop. You gain improved collaboration and integration with both code and XAML editing tools—with support for desktop, mobile, and WebAssembly—to get your code looking good quickly.
With application development deadlines getting ever shorter, a tool like this is essential. We need to avoid forcing context shifts on designers and developers. Keeping them in the flow of their code reduces the risks of errors and bugs. Uno may be best known as a set of cross-platform design controls, but developing and building applications with it has taught the team many lessons, and they’re passing that experience on to the rest of us.
{kind=link}
Google unveils Gemma 3 multi-modal AI models 13 Mar 2025, 3:39 am
Google DeepMind has introduced Gemma 3, an update to the company’s family of generative AI models, featuring multi-modality that allows the models to analyze images, answer questions about images, identify objects, and perform other tasks that involve analyzing and understanding visual data.
The update was announced March 12 and can be tried out in Google AI Studio for AI development. Gemma 3 also significantly improves math, coding, and instruction following capabilities, according to Google DeepMind.
Gemma 3 supports vision-language inputs and text outputs, handles context windows up to 128k tokens, and understands more than 140 languages. Improvements also were made for math, reasoning, and chat, including structured outputs and function calling. Gemma 3 comes in four “developer friendly” sizes of 1B, 4B, 12B, and 27B and in pre-trained and general-purpose instruction-tuned versions. “The 128k-token context window allows Gemma 3 to process and understand massive amounts of information, easily tackling complex tasks,” Google DeepMind’s announcement said.
Developers have multiple deployment options, such as Cloud Run and Google GenAI API. An open-weight LLM library, Gemma 3 features a revamped code base, with recipes for inference and fine-tuning. Gemma 3 model weights can be downloaded from Kaggle and Hugging Face.
Nvidia has direct support for Gemma 3 models for maximum performance on GPUs of any size, from Jetson Nano to the most-recent Blackwell chips. Gemma 3 also is optimized for Google Cloud TPUs and integrates with AMD GPUs. For executing on GPUs, users can leverage Gemma.cpp.
Google DeepMind on March 12 also announced ShieldGemma 2, a 4B parameter model built on Gemma 3 that checks the safety of synthetic and natural images against key categories to help build robust data sets and models. ShieldGemma 2 is recommended for use as an input filter to vision language models or as an output filter of image generation systems. ShieldGemma 2 allows developers to minimize the risk of harmful content such as content that is sexually explicit, dangerous, or violent, Google DeepMind said.
{kind=link}
GitHub to unbundle Advanced Security 12 Mar 2025, 10:06 pm
GitHub announced plans to unbundle its GitHub Advanced Security (GHAS) product, breaking it up into two standalone products: GitHub Secret Protection and GitHub Code Security. The unbundling is set to happen on April 1.
GitHub Secret Protection will detect and prevent secret leaks before they happen, using push protection, secret scanning, AI-powered detection, security insights, and other capabilities. GitHub Code Security, meanwhile, will help developers identify and remediate vulnerabilities faster with code scanning, Copilot autofix, security campaigns, dependency review action, and more, according to GitHub.
Announced March 4, the unbundling is intended to make GitHub’s security offering easier to access and more cost-effective. Currently, GitHub Advanced Security provides private repositories with capabilities to scan for security vulnerabilities and secrets. The new product plan will not require a GitHub Enterprise subscription. Expanded access to the security platform allows organizations of all sizes to get enterprise-grade security features as they build and offer code, GitHub said.
In addition to unbundling Advanced Security, GitHub is launching a free secret risk assessment for users to understand secret leak exposure across GitHub. This service will also be available on April 1 in the Security tab.
{kind=link}
At long last, OpenStack (now known as OpenInfra Foundation) joins Linux Foundation 12 Mar 2025, 9:52 pm
After more than a decade as an independent open-source foundation, the OpenStack project is joining the Linux Foundation in a move aimed at accelerating collaboration across the open infrastructure ecosystem.
Fifteen years ago, Rackspace got together with NASA and created the open-source OpenStack project. Over the next two years, as OpenStack’s technology and user base grew, there were many discussions among participants about moving the technology to an open-source foundation. One of the leading options was to join the Linux Foundation, but that didn’t happen. Instead, in 2012, the OpenStack Foundation was created, which changed its name to the Open Infrastructure (OpenInfra) Foundation in 2020.
{kind=link}
OpenAI takes on rivals with new Responses API, Agents SDK 12 Mar 2025, 7:38 pm
OpenAI’s new Responses API and an upgraded Agents SDK will help enterprises more easily build agents with advanced reasoning and multimodal capabilities, the company said Wednesday.
The new tools may help it fend off challenges from rivals such as Anthropic or up-and-coming Chinese competitors including DeepSeek and Butterfly Effect, the developer of Manus, looking to capture a chunk of the agentic automation market.
OpenAI has upgraded its Agents SDK with new integrated observability tools to trace and inspect agent workflow execution
The Responses API combines capabilities of the existing Chat Completions and Assistants API, and will become the de facto API that enterprises use to build agents to handle complex tasks.
OpenAI said that repackaging the capabilities in this way will help developers incorporate its built-in tools into their apps, without the complexity of integrating multiple APIs or external vendors.
“Developers feel like they’re having to cobble together different low level APIs from different sources. It’s difficult, it’s slow, it often feels brittle,” Kevin Weil, chief product officer at OpenAI, explained in a webcast with reporters.
Capabilities packaged in the Responses API
For now, the LLM provider is packaging three capabilities — web search, file search, and computer use — to help developers connect models to the real world and make them more useful in completing tasks.
The web search tool is the same one that powers ChatGPT Search, underpinned by a fine-tuned GPT-4o and GPT-4o mini models, said Nikunj Handa, an engineer in OpenAI’s product team, in the same webcast.
The file search tool, initially introduced last year as part of the Assistants API to help developers perform RAG on documents, now includes metadata filtering so developers can search on file attributes and a direct search endpoint that can comb data stores without queries being filtered through the AI model, explained Steve Coffey, an engineer with OpenAI, during the webcast.
The third tool packaged inside the Responses API is the computer use tool, which uses the same operator model found in ChatGPT.
“The computer use tool is operator in the API, but it allows you to control the computers that you are operating. So, this could be a virtual machine or a legacy application that just has a graphical user interface and developers have no API access to it,” Handa explained during the webcast.
Rival Anthropic introduced such a computer-use capability accessible through an API in its Claude 3.5 Sonnet LLM last October. This can read and interpret what’s on the computer’s display, type text, move the cursor, click buttons, and switch between windows and applications.
There are significant differences between the two companies’ approaches.
Moor Insights and Strategy principal analyst Jason Andersen noted that OpenAI’s system is screenshot based, whereas Anthropic can work with command outputs from tools.
In the same vein, Forrester vice president and principal analyst Charlie Dai pointed out that the two LLM providers have different design philosophies, safety considerations, and ecosystem integration, which may lead to variations in how abilities such as computer use are implemented and constrained.
“OpenAI’s models might feel more versatile and widely applicable, while Anthropic’s models might prioritize safety and alignment in their approach to computer use based on their claims, such as ‘We’ve trained the model to resist these prompt injections and have added an extra layer of defense,’” Dai said.
Andersen said one advantage of the new API is that it opens up an avenue for developers to automate tasks without a major migration effort. But he warned that the cost of this approach may add up over time as users and task complexity scale.
The Responses API is currently available and is not charged separately, which means that enterprises pay for the tokens and tools at OpenAI’s standard rates.
Chat Completions: not dead yet
OpenAI said it will continue to support Chat Completions, its most widely adopted API, and add new models to it, even though it is now subsumed within the Responses API. If developers don’t use built-in tools they can continue to use the Chat Completions API, but if they require built-in tools, especially for newer integrations, the Responses API should be the preferred choice, the company said.
As for the Assistants API, OpenAI’s plan is to include every tool and feature into it along with the Responses API, before phasing it out in mid-2026. When it formally announces the API’s deprecation, it said, it “will provide a clear migration guide from the Assistants API to the Responses API that allows developers to preserve all their data and migrate their applications.”
What is OpenAI’s Agents SDK?
The open source Agents software development kit (SDK) is an upgraded version of Swarm, an experimental SDK that OpenAI released last year to help developers orchestrate agentic workflows. Despite Swarm’s experimental status, OpenAI said several enterprises have already adopted it.
Some of the improvements that accompany its rebranding as Agents SDK include new agents, handoffs between agents, guardrails, and observability tools to debug agents and trace their performance.
Andersen said the SDK is a “big deal” since platforms such as Amazon Bedrock and Google’s Vertex AI are rapidly expanding into providing workflow and agent-to-agent collaboration support.
“But, it’s also significant since OpenAI has been a proponent of very large broadly trained models. The idea of collaborative agents suggests that OpenAI is also open to the idea of small, focused models for specific tasks working with other models,” he said.
The Agents SDK, according to OpenAI, works with the Responses API and Chat Completions API.
The SDK will also work with models from other providers, as long as they provide a Chat Completions-style API endpoint, the LLM provider wrote, adding that developers can immediately integrate it into their Python codebases, with Node.js support coming soon.
{kind=link}
Designing a dynamic web application with Astro 12 Mar 2025, 10:00 am
Astro.js is among the most popular meta-frameworks for JavaScript developers, and for good reason. Astro makes it relatively easy to structure web applications for maximum effect with minimal effort. It can be hard to get your head around how Astro works, however, due to the ways it breaks from more traditional front-end JavaScript frameworks.
In this article, we’ll take a hands-on approach to Astro. My goal is to leave you with a good overall understanding of how the framework handles web development essentials like pages, endpoints, routes, and deployment. See my recent introduction to plug-and-play web development with Astro for an overview of the framework.
The demo application
The to-do application is a classic way to explore a new tech stack and see how it handles standard development requirements. The online to-do list requires a small feature set but lets you explore all the basic elements of listing data and performing CRUD operations. Once you have these basics down, the sky is the limit for adding new features. How about adding drag-and-drop columns and infinite scrolling, or delivering your to-do list as an RSS feed? It’s no problem once you understand how the tech stack works.
Web application components are notoriously diverse, and sometimes getting them to work together nicely is like herding kittens. I might start off wanting to deploy a snappy, attractive page with simple functionality, but I’m soon elbow-deep in arcane configuration files. Astro alleviates some of that complexity by providing a universal layer that handles many of the common back-end infrastructure and engine concerns. And it lets you use or even combine a variety of familiar front-end frameworks.
SPA, MPA, or something in the middle?
There are a few considerations to designing the to-do application using Astro. One immediate decision point is whether you want a single-page application (SPA) or muti-page application (MPA). The type of application you choose determines how the app will load its data into the client.
The defining characteristic of SPAs is that most (if not all) interactions are driven by the client issuing API requests in the background and updating the UI accordingly. The idea of a single-page app is that you load everything you need, including the JavaScript, and then do the work from there. The result is essentially a thick or fat client in the browser.
MPAs are more in the tradition of Web 1.0: a collection of static pages connected with hyperlinks. Whereas SPAs are more modern and dynamic, MPAs can be more reliable. While the two styles are often pitted against each other, the truth is many modern applications blend these styles. Ideally, we want to maximize the strengths and minimize the weaknesses of each one. It is common to load as much content as possible statically, and then apply the dynamic elements where they make an impact. In both cases, you want to apply the best practices for the style you are using.
That’s the idea, anyway. But anyone who has set out to code a blended application can tell you it gets tricky fast! Astro employs an islands architecture to make the hybrid format more manageable. Islands essentially divvy up the application layout into discrete parts, which can then be loaded using best practices for the given type of content.
Taking the to-do app as our example, it makes sense to render any framing content (like headings) in a way that supports maximum speed and SEO-friendliness. Then, for the dynamic to-do list, we have a few options. We could use a reactive framework like React in full SPA mode, in which case we’d send the client assets over and then load the data from a server API. Another option is to use the same component and pre-render it on the server, a kind of middle-ground between SPA and MPA. Another option altogether is using plain JavaScript or HTMX to create and render the list.
Regardless of the style you choose, Astro does much of the upfront thinking for you. It walks you through deciding how parts of the UI should be rendered, then lets you use the same process to construct your server-side APIs.
Static or server-side rendering?
Astro offers both static and server-side rendering of web application pages and components. In static mode, the content is rendered ahead of time on the server and packaged for utmost efficiency in delivery and display on the client. In server-side rendering (SSR) the content is rendered live upon every request. (Static rendering is sometimes called SSG or server-side generation, to contrast it with SSR.)
Astro is best known for its ability to generate front-end views using reactive frameworks like React, but it can also handle back-end needs like API endpoints. In both cases, the static vs. SSR question comes into play. A statically generated endpoint or page is essentially a hard-coded file that is created at runtime and serves the same content for every request.
In Astro, pages and endpoints are generated on the server by default. This pre-rendering is intended to give you maximum efficiency in terms of bits going over the wire and minimizing processing power being used at the client.
You tell a page or endpoint to use dynamic rendering with the following syntax:
export const prerender = false;
Setting the deployment target
Keep in mind that when you are running in dev mode, you don’t necessarily see the effect of static loading because the dev-mode serving is constantly reloading your changes. That’s why it’s important to mention Astro’s adapter concept, which is used to prepare your application for deployment.
Adapters might seem complex at first, forcing you to deal with another concern in the midst of trying to just build your application. But adapters can greatly simplify the question of deployment. (SvelteKit is another framework that employs adapters.)
Astro includes several deployment targets in its adapter providers, including Netlify, Vercel, and Node. If you think about it, only SSR components require an adapter. If a component is SSG, then it ultimately is turned into a static asset—either a bundled-up HTML page or a JavaScript file in the case of endpoints.
Adapters provide a clear-cut path to deployment and flexibility in targets, similar to the flexibility Astro gives you when choosing a front-end framework.
Routing
Like Next.js, Astro provides file-based routing. This is nice because your URL mapping is defined simply by where you put your files and what you name them. Of course, Astro also supports other needful things like route parameters.
In Astro, the /src/pages directory holds your routes. So your main index landing page would be defined as:
/src/pages/index.astro
While the URL /test would live at:
/src/pages/text.astro
Similarly, your endpoint routes follow a similar convention. You could define a /data.json endpoint like so:
/src/pages/data.json.ts
Note that the .ts extension will be stripped off in the URL. Astro uses the .astro versus .ts distinction to tell if you want a web page or an endpoint. Astro is also happy to use the following if you like your JavaScript untyped:
/src/pages/data.json.js
Sometimes, I do like my JavaScript untyped. So sue me.
HTMX on the front end
Regular readers will know that I’m a fan of HTMX. I’ll even go so far as to predict it’ll be added to the HTML spec at some point. I’ve previously explored using Astro with front-end frameworks like Svelte and React. This time, I’m interested to see how it works when combined with HTMX.
This should be a neat way to get a look at both HTMX and several of Astro’s powers, like SSG pages and SSR endpoints. Of course, React, Svelte, or Vue could also work very well. The snazzy part of HTMX is that it provides much of the interactivity we need, like AJAX requests and partial view updates, without stepping outside of HTML.
Combined with Astro’s server-side and deployment capabilities, HTMX should give us a good foundation for doing everything we need. Hopefully, we can try adding something more sophisticated as well, like infinite scrolling. Check back next week for the next article in this series.
{kind=link}
Air-gapped Python: Setting up Python without a net(work) 12 Mar 2025, 10:00 am
The vast majority of modern software development revolves around one big assumption: that you always have a network connection. If you don’t, it’s typically because you’re on an airplane with no Wi-Fi, and that’s temporary.
But what about when you’re in an environment where there’s no connection by design? How do you, a Python developer, deal with working on a system that has either undependable network connectivity or none at all?
The good news is, you can make it work, provided you have two basic requirements in place. First, you must have another computer with network connectivity. Second, you must be able to copy files manually to and run software installs on the no-or-low-network machine. Then you can set up Python and pip install packages as needed.
The downside of the process are the steps involved (more than normal) and the loss of flexibility. You’ll have to know in advance what you need to install. Things may also get more complicated if you have dependencies that aren’t part of the Python ecosystem, like a C compiler.
But, if air-gapped Python is what you need, here’s how to get it.
Step 1: Gather the components
To start the process, figure out a list of what you’ll need to obtain for your Python projects. This breaks down to two basic categories:
1) Python itself
If you don’t have the Python runtime on the target system, or the proper edition for your use, you’ll need to obtain an installer for that version of Python. On Microsoft Windows or macOS, this doesn’t involve much more than downloading the installer executable.
On Linux, the process is far more complex and varies between package management systems. For instance, Ubuntu/Debian systems can use a utility, apt-offline, to obtain packages for offline installation.
2) Python packages you want to install
Python packages can be distributed as self-contained .whl files. Installing them is easy: pip install /path/to/file.whl.
It’s also not hard to download wheels as files using pip. The pip download command will obtain the .whl file for the package in question and save it in the current working directory.
You can also use download to snag all the requirements needed for a package from a requirements.txt file: pip download -r .
There are two important things to keep in mind about using pip download. First, Python packages can have dependencies, and you probably want the most proper list of the dependencies for the project(s) you want to port to the target system. It’s best to get that list from an actual installed copy of the packages:
- Create a virtual environment.
- Install everything you need into it.
- Use
pip freezeto dump the package list to a file. This file can then be used as yourrequirements.txtfile to download everything.
Many packages depend on Python tooling like setuptools and wheel, so this is a convenient way to include those tools in the requirements list.
Important: With pip download, keep in mind that you should always run pip from the same version of Python you intend to use on the target machine. If, for instance, you’re using Python 3.12 on the air-gapped machine, you’ll need to run pip download using Python 3.12 on the networked machine. If you can’t do this, you can pass --python-version . This flags pip download to specify the version of Python so you obtain wheels for that version.
If you want to download .whl files manually from PyPI, you can directly download installation files for any PyPI-hosted project from its PyPI page. Click on Download files in the left-hand Navigation column, and you’ll see a list of all the files available.
Note that you might not see a download that matches precisely your version of Python. This isn’t always a problem. Wheels files with an identifier in the name like py3-none-any are typically compatible with most any current version of Python. The Classifiers | Programming Language list in the bottom left-hand side of the PyPI project page typically lists the specific versions of Python you can use.
If you only see .tar.gz files instead of .whl files, that is a distribution of the original source code, which can also be installed with pip. Note that there may be build requirements involved for installing from source, so you’d need to also install on the target system any such requirements, like a C compiler. (More on this later.)
Step 2: Transport the files and set up the interpreter and apps
Once you’ve copied the files over, setting up the interpreter will (again) depend on the operating system you’re using. On Windows and macOS the process is as easy as running the installer executable. For Linux, each package manager will have its own behavior and syntax for installing from an offline package. You’ll need to consult your distribution’s package manager documentation for those details.
When you want to set up your Python application’s requirements, create a virtual environment for the app as you usually would, then run pip:
pip install --no-index -f /path/to/wheels Here, --no-index forces pip to ignore checking PyPI for packages. The -f option lets you provide a path for pip to search for Python .whl files. This is where you provide the directory where you’ve copied those files.
if you’re doing an in-place editable install of the package, use this variant:
pip install -e . --no-index -f /path/to/wheelsThis uses whatever requirements are in pyproject.toml for the project. Note, again, that if you haven’t copied all the needed requirements over, the installation will fail. This is another argument for obtaining the requirements list using pip freeze in a venv where the app is already installed.
Installing third-party Python package dependencies offline
The most complex installations involve third-party dependencies that aren’t packaged as Python wheels. For instance, if you’re using a Python package that has a C extension, and you’re not installing from a precompiled binary wheel, the install process will attempt to find a C compiler to build the extension.
To that end, you’ll also need to copy over and set up any of those third-party build dependencies. The bad news: It’s possible not all of those will be tracked explicitly in Python package manifests. In fact, most aren’t, since Python’s packaging system has no mechanism for doing this. Third-party Python distributions like Anaconda do have that power, but at the cost of having to use an entirely different Python distribution.
A common missing component for Python packages is a C compiler, typically for building CPython extensions from source. On Microsoft Windows, that C compiler is typically the Microsoft Visual C++ Compiler (MSVC), since CPython is compiled with it on Windows. You don’t need all of Visual Studio to use it, though; you can install a minimal, command-line-only version of MSVC, a package called the Visual Studio C++ Build Tools.
Unfortunately, creating an offline installation package for Visual Studio C++ Build Tools is a complex process. It involves making a “local layout” installation of the needed files—essentially, creating an install of Visual Studio on a networked machine with only the command-line components you need, then transferring that layout to the target machine and installing from there.
{kind=link}
How Wasm reinvents web development 12 Mar 2025, 10:00 am
WebAssembly fascinates me.
The notion of assembly language is as old as computing. Typically, assembly meant specific instructions for moving data around inside of a physical central processor. Everything in a computer is ones and zeros, but a layer above that is assembly code. To say that it is “human readable” is a bit of a stretch, but there are humans who can look at assembly and understand exactly what is going on, and even some who can use assembly to fine-tune things.
Normally, we rely on a compiler to turn our higher-order languages like C++ or Object Pascal into assembly language that will run on bare metal. Each different processor would have its specific assembly language, and thus an executable from an Intel processor won’t run on an Arm-based system, and vice versa. Assembly usually ties you to a specific piece of physical hardware.
But WebAssembly, or Wasm, is different. The idea behind Wasm is that it can be run anywhere. It represents a fundamental shift from hardware-based assembly languages. Wasm is designed from the ground up to be portable and to run securely across different environments.
Up from assembly
Much of the progression of computing has been to build layers of abstraction on top of previous layers that are more complex. Ones and zeros became assembly language. Assembly became Fortran, Cobol, and C. These languages compiled down to assembly. Then we added API levels like Windows that drove graphical user interfaces.
Then came abstractions like the Java Virtual Machine (JVM) and the .NET runtime that separated us further from the raw machine code. They drove the notion of an executable to something that could theoretically be run on any operating system.
From there, we abstracted things even further to running code in a browser. These days, the browser functions almost as an operating system, minimizing the developer’s dependency on the underlying OS. Chrome, for example, runs in Windows, Android, iOS, and macOS, executing code within its own controlled sandbox. It is a deeper abstraction than even the JVM or .NET runtime.
And this is why Wasm fascinates me. It has the potential to really answer the call of “Write once, run everywhere.” That was the great hope of Java, but it didn’t take long for that aphorism to become “Write once, debug everywhere.”
While Wasm doesn’t yet “run everywhere,” its use is steadily expanding beyond the browser. Broader adoption, particularly on the server side, seems inevitable. Right now, Wasm is most useful for doing computationally intense operations like gaming and encryption. Since the browser is the target for a large and ever-increasing portion of applications, it stands to reason that Wasm will become even more widely used.
Rust, C/C++, and Go are probably the best known Wasm-capable languages, but any language can be compiled into Wasm. Part of my fascination is that TypeScript has yet to follow suit. It seems obvious to me that every day, it becomes more likely that the code we write will end up running in the browser, and a language targeted at web development seems like a natural candidate to support Wasm.
The last mile
Probably the biggest barrier right now is that Wasm doesn’t have an official way to access system-level resources like the file and networking systems. The WebAssembly System Interface (WASI) exists but is yet to be widely accepted and supported, particularly on the server side. Nor does Wasm have the notion of garbage collection, making support for languages like Java and C# difficult. Binding to web frameworks like React is still quite kludgy and requires interfacing with JavaScript. The bottom line is that Wasm has a way to go before it can be used as the language of the web.
But, oh, the potential. Imagine a world where Wasm and WASI are common, bindings to the DOM enable web user interfaces, and the potential to build web applications in any programming language becomes a reality.
In the medium term, Wasm’s utility will continue to grow and its ability to complement JavaScript will increase. It has its problems, and for at least the near-term, JavaScript will continue to be the lingua franca of the web. But it isn’t outlandish to think that it is merely a matter of time before Wasm turns the browser into a universal operating system that hosts all programming languages.
And I find that fascinating.
{kind=link}
JavaOne 2025 heralds Java’s 30th birthday 12 Mar 2025, 1:32 am
With Java advancing toward its 30th anniversary, Oracle will hold its annual JavaOne conference next week, centering around the Java language, the evolution of the Java platform, and the role of Java in areas such as generative AI and machine learning.
The March 18-20 event will be at the Oracle campus in Redwood City, Calif., just about two months ahead of Java’s 30th anniversary on May 23. The conference will have a three-pronged theme: the platform evolution toward a better, faster, and smaller Java; a look back on 30 years of Java; and a look ahead toward the future of Java and its use cases. Perhaps one of the highlights of the event, officially called JavaOne 2025, will be a keynote presentation by the former CEO of Java founder Sun Microsystems, Scott McNealy.
JavaOne 2025 also will host the introduction of Java Development Kit 24, the latest release of the JDK with 24 new features including garbage collection improvements, improved virtual threads, and quantum-resistant algorithms. Topics such as using Java for AI model training and deployment, and using AI assistants for Java development, also will feature in the program.
Several dozen sessions are planned for JavaOne 2025 including:
- AI and Java: From Exploration to Deployment. This session will feature a walkthrough of AI platforms that simplify the life cycle for Java developers.
- Interested in Where the Java Language is Going? The focus of this talk will be recent Java enhancements and future directions.
- Introduction of AI/ML for Java Developers. This session will cover AI/ML fundamentals along with related topics such as vector databases and RAG (retrieval-augmented generation) strategies.
- A New Model for Java Object Initialization. This presentation will discuss the co-evolution of the Java language, JVM, and coding practices to improve how fields, arrays, and objects are initialized.
- JavaFX and Beyond. This session will cover the JavaFX graphical UI toolkit and features such as RichTextArea, CSS transitions, and platform preferences.
- Java for Small Coding Tasks. This presentation will discuss how Java can be used for scripts, Jupyter notebooks, and code that runs in the browser.
{kind=link}
Go-based TypeScript to dramatically improve speed, scalability 11 Mar 2025, 4:00 pm
Microsoft is developing a native TypeScript implementation based on Google’s Go language. The initiative promises dramatic improvements in editor startup speed, build times, and memory usage, making it easier to scale TypeScript to large code bases, Microsoft said.
Announced March 11, the plan involves porting the TypeScript compiler, tools, and code base from JavaScript to Go. Microsoft’s TypeScript team expects to be able to preview command-line type-checking in Go-based tsc by mid-2025, and to deliver a feature-complete Go implementation of TypeScript by the end of the year.
Developers who use Go-based TypeScript in the Visual Studio Code editor will feel the increased speed in the editor, Microsoft said. The company promises an 8x improvement in project load times, instant comprehensive error listings across entire projects, and greater responsiveness for all language service operations including completion lists, quick information, go to definition, and find all references. The new TypeScript will also support more advanced refactoring and deeper insights that were previously too expensive to compute, the company said. A demo video of the project is available here.
Microsoft expects developers to be “extremely excited” about this new development, because one of the most common pain points for users of the current, JavaScript-based TypeScript is that performance slows when it is used for large-scale apps, according to Microsoft.
Developers can build and run the Go code from a new working repo, offered under the same Apache License 2 license as the existing TypeScript code base. The JavaScript code base will continue development into the 6.x series. TypeScript 6.0 will introduce some deprecations and breaking changes to align with the upcoming native code base. When the native code base has reached sufficient parity with the current TypeScript, Microsoft will release it as TypeScript 7.0.
While some projects may switch to TypeScript 7.0 upon release, others may depend on certain API features, legacy configurations, or other constraints that require the continued use of TypeScript 6.0, Microsoft said. The JavaScript code base will be maintained in the 6.x line until TypeScript 7.x reaches sufficient maturity and adoption.
{kind=link}
Weaviate adds agents to its tech stack to ease gen AI app development 11 Mar 2025, 10:36 am
Vector database provider Weaviate has added three new agents to its development stack to facilitate the development of generative AI-based applications.
These agents are modular agentic workflows that use large language models (LLMs) and prompts to interact dynamically with data in Weaviate.
“Each Weaviate Agent uses an LLM pretrained on Weaviate’s APIs to perform tasks. Agents can be easily swapped, rearranged or used together, speeding up development with their simple APIs and powerful functionality,” a Weaviate spokesperson said.
While the vector database provider plans to launch more such agents, for now it has showcased three — Query Agent, Personalization Agent, and Transformation Agent.
The agents, which are expected to be made available as a separate service, could help developers automate their processes for building AI applications and enable natural language interactions with data, said Noel Yuhanna, principal analyst at Forrester.
“These Weaviate agents automate tasks such as vector queries, data transformation, and other processes using natural language while facilitating the search, retrieval, and orchestration of related data,” Yuhanna explained.
The Futurum Group’s global technology analyst Bradley Shimmin sees these agents as clever marketing and believes that Weaviate is the first vector database provider that is marketing agents as a family of developer-focused tools.
However, he pointed out that they are not the first vendor to use generative AI to augment and automate tasks for developers, database administrators, data scientists, and even business users.
What are the Query, Transformation, and Personalization Agents?
The Query Agent is aimed at helping developers simplify complex query workflows and boost RAG pipelines by querying data using natural language, Weaviate said.
In the absence of the agent, developers would have to construct a query understanding pipeline, which Weaviate claims is challenging to build, maintain, and requires specialized expertise.
The Query Agent, according to Victoria Slocum, machine learning engineer at Weaviate, ditches SQL-to-text querying and uses function calling.
Function calling, in turn, uses an LLM to structure queries using predefined function calls in JSON format, with optional arguments for search, filters, aggregation, and grouping, Slocum explained in a LinkedIn post.
The Query Agent also has the ability to chain commands together, taking the results of a previous query and extending it with a new prompt, the database provider said.
The Transformation and Personalization Agents are targeted at organizing datasets and personalizing agent behavior respectively.
The Transformation Agent allows developers to augment and organize datasets with a single prompt and use cases include cleaning and organizing raw data for AI, generating and enriching metadata, automatically categorizing, labelling and preprocessing data, or even translating the entire dataset, the database provider said.
Changing database landscape, availability, and pricing
The release of Weaviate agents, according to Yuhanna, is in tune with the growing trend of integrating agents to automate various functions and processes to accelerate AI workloads.
“The advantages of these agents are that they can evolve independently, making it easier for enterprises to adopt them quickly than committing to a single, all-encompassing AI solution,” he explained.
However, Shimmin pointed out that there is no shortage of vector databases to choose from right now, particularly among stand-alone players like Weaviate, Qdrant, Faiss, Chroma, and Milvus.
“This move by Weaviate I think may help the company compete somewhere between stand-alone and traditional database offerings, such as PostgreSQL, Oracle Database, or Microsoft Cosmos DB. I would imagine Weaviate would favor establishing a rich developer ecosystem, building upon these agents as a means of becoming perhaps the next MongoDB,” Shimmin explained.
When asked about its target customers, a Weaviate spokesperson said that the agents are suitable for businesses of any size that want to make their data operations more efficient.
Weaviate’s Query Agent is currently available in Public Preview and the Transformation and Personalization Agents will be available in Preview later this month. During Preview, these Agents will be free to use as part of Weaviate Serverless Cloud and its free developer sandbox, Weaviate said, adding that detailed pricing will be updated in the future.
{kind=link}
Has AWS lost its edge? 11 Mar 2025, 10:00 am
Amazon Web Services (AWS) has long maintained its dominance in the cloud computing market, serving as the backbone for many enterprises’ digital transformation efforts for more than a decade. However, recent shifts in strategy suggest that AWS may be faltering in its ability to pioneer meaningful innovations in enterprise technology.
Case in point: AWS’s recent announcement regarding agentic AI, which feels more like a press release chasing relevance than a proactive attempt to lead the industry into the next era of technology. The company is not announcing a specific product or service but is forming a group that will focus on agentic AI. This is pretty weak tea.
Delayed innovation
As reported by Reuters, the formation of a dedicated group within AWS help customers “automate more of their lives” using agentic AI could have been an opportunity for Amazon to highlight technological breakthroughs or specific innovations that set it apart from its competitors. The pitch that agentic AI will be “the next multi-billion-dollar business for AWS,” per an email from AWS CEO Matt Garman, seems more like a strategy to buy Amazon time.
In the highly competitive world of cloud computing, “fast follower” strategies don’t cut it anymore. Amazon built its early success on bold innovation, popularizing cloud services with EC2 and S3, building AWS into a juggernaut that essentially invented the infrastructure-as-a-service (IaaS) market. However, recent patterns suggest that AWS is no longer proactively innovating. The company appears increasingly reactive to what others in the market are doing.
I would advise AWS to make a strong case for generative AI and now agentic AI as clear trends for enterprise technology. Right now it looks like they are waiting to see if these technologies will be genuinely worthwhile to invest in. As somebody who has been a technology CTO about a half-dozen times, that’s a recipe for failure and death by a thousand cuts. It is better to innovate and fail than not to innovate at all.
Agentic AI and beyond
The AWS announcement comes after key competitors such as OpenAI, Microsoft, Salesforce, and even Google began carving out market opportunities for AI tools beyond conversational systems. AWS appears late to the party, offering little more than a promise of agentic AI tools without many specific enterprise-ready capabilities to back it up. Yes, there were demos of Alexa+ autonomously booking Ubers and navigating websites, but these mostly appeal to consumers and lack the sophistication that enterprises genuinely need. It feels like a big idea with very little underneath it.
Enterprises will no longer settle for vaporware. They expect actionable innovations—tools and systems that can immediately be deployed and provide value. AWS’s inability to deliver on these expectations, coupled with the glacial pace at which new enterprise-ready solutions are rolled out, is prompting enterprises to reconsider whether AWS is still the partner they need for innovation-driven growth.
The slowdown in cloud innovation comes at a critical moment for AWS and other public cloud providers. Enterprises are no longer simply weighing AWS versus Microsoft Azure or Google Cloud Platform; they are rethinking their reliance on public cloud providers altogether. Public cloud was once heralded as the inevitable path forward for enterprise IT, but that assumption is now being challenged as organizations seek alternatives.
A growing segment of enterprises is pivoting toward a more hybrid or diversified technology strategy. They’re turning to private clouds for tailored workloads that don’t require the scale or shared infrastructure of public cloud providers. They’re also investing in colocation (colo) providers, which offer physical data center infrastructure that blends the best of both worlds—control over hardware without the heavy lifting of managing physical infrastructure. Managed service providers (MSPs) are also seeing a resurgence as businesses look for providers that can offer niche expertise, customized solutions, and cost predictability, things that public cloud cost models often struggle to deliver.
Even the traditional hardware market, once thought to be on life support, is seeing renewed interest. Dell and HPE are doubling down on on-premises and edge computing solutions. Enterprises increasingly see value in using their own hardware as part of a larger hybrid strategy or as a safeguard against public cloud outages and pricing unpredictability.
Although AWS has long touted its role as the preeminent leader in cloud innovation, there is a growing perception that the company is resting on its laurels. This creates particularly sharp skepticism among CIOs, CTOs, and other enterprise leaders. Perhaps some are even thinking about canceling their trip to AWS re:Invent this year.
The way forward
For AWS to regain its reputation as an innovator, it must change how it approaches market leadership. Instead of relying on “innovation by press release,” it needs to deliver concrete, enterprise-ready systems faster and with more strategic foresight. It must recognize that its market power is only as strong as the confidence enterprises place in it to lead, not follow.
AWS also needs to address the trust deficit among enterprises by making its innovation road map more explicit and dedicating more resources toward developing solutions that solve real-world problems. Enterprise customers are no longer looking for flashy presentations at re:Invent; they want answers to today’s complex business challenges.
Tough love? Perhaps. AWS is a collection of many smart people, many of whom I count among my longtime friends. I think the leaders at AWS have the means to pivot, but they will need to crave risk again to do it successfully.
{kind=link}
3 of the best LLM integration tools for R 11 Mar 2025, 10:00 am
When we first looked at this space in late 2023, many generative AI R packages focused largely on OpenAI and ChatGPT-like functionality or coding add-ins. Today, the landscape includes packages that natively support more LLM suppliers—including models run locally on your own computer. The range of genAI tasks you can do in R has also broadened.
Here’s an updated look at one of the more intriguing categories in the landscape of generative AI packages for R: adding large language model capabilities to your own scripts and apps. My next article will cover tools for getting help with your R programming and running LLMs locally.
ellmer
ellmer wasn’t one of the earliest entries in this space, but as the main Tidyverse package for using LLMs in an R workflow, it’s among the most important. ellmer has the resources of Posit (formerly RStudio) behind it, and its co-authors—Posit Chief Scientist Hadley Wickham, (creator of ggplot2 and dplyr) and CTO Joe Cheng, original author of the Shiny R web framework—are well known for their work on other popular R packages.
Kyle Walker, author of several R and Python packages including tidycensus, posted on Bluesky: “{ellmer} is the best #LLM interface in any language, in my opinion.” (Walker recently contributed code to ellmer for processing PDF files.)
Getting started with ellmer
ellmer supports a range of features, use cases, and platforms, and it’s also well-documented. You can install the ellmer package from CRAN the usual way or try the development version with pak::pak("tidyverse/ellmer").
To use ellmer, you start by creating a chat object with functions such as chat_openai() or chat_claude(). Then you’ll use that object to interact with the LLM.
Check the chat function help file to see how to store your API key (unless you’re using a local model). For example, chat_openai() expects an environment variable, OPENAI_API_KEY, which you can store in your .Renviron file. A call like chat_anthropic() will look for ANTHROPIC_API_KEY.
ellmer supports around a dozen LLM platforms including OpenAI and Azure OpenAI, Anthropic, Google Gemini, AWS Bedrock, Snowflake Cortex, Perplexity, and Ollama for local models. Here’s an example of creating a basic OpenAI chat object:
library(ellmer)
my_chat
And here’s the syntax for using Claude:
my_chat_claude
System prompts aren’t required, but I like to include them if I’ve got a topic-specific task. Not all chat functions require setting the model, either, but it’s a good idea to specify one so you’re not unpleasantly surprised by either an old, outdated model or a cutting-edge pricey one.
Several R experts said in early 2025 that Anthropic’s Claude Sonnet 3.5 seemed to be best specifically for writing R code, and early reports say Sonnet 3.7 is even better in general at code. However, with the new batch of models released by OpenAI, Google, and others, it’s worth keeping an eye on how that unfolds. This is a good reason for coding in a way that it’s relatively easy to swap models and providers. Separating the chat object from other code should do the trick.
I’ve found OpenAI’s new o3-mini model to be quite good at writing R code. It’s less expensive than Sonnet 3.7, but as a “reasoning” model that always thinks step by step, it may not respond as quickly as conventional models do.
Sonnet is somewhat pricier than GPT-4o, but unless you’re feeding it massive amounts of code, the bill should still be pretty small (my queries typically run two cents each).
If you want to set other parameters for the model, including temperature (meaning the amount of randomness acceptable in the response), use api_arg. That takes a named list like this one:
my_chat
A higher temperature is often viewed as more creative, whereas a lower one is considered more precise. Also note that temperature isn’t an explicit argument in ellmer’s chat functions, so you need to remember to set it in the api_args named list. (Updating this setting is a good idea since temperature can be an important parameter when working with LLMs.)
Check the model provider’s API documentation for a list of available argument names and valid value ranges for temperature and other settings.
Interactivity
ellmer offers three levels of interactivity for using its chat objects: a chatbot interface, either in the R console or browser only; streaming and saving the results as text; or only storing query results without streaming.
live_console(my_chat) opens my_chat in a chat interface in the R console. live_browser(my_chat) creates a basic chatbot interface in a browser. In both cases, responses are streamed.
ellmer’s “interactive method call” uses a syntax like my_chat$chat() to both display streamed responses and save the result as text:
my_results
If you use my_chat again to ask another question, you’ll find the chat retained your previous question-and-answer history, so you can refer to your previous questions and the responses. For example, the following will refer back to the initial question:
my_results2 <- my_chat$chat("Now color turquoise please")

This chat query includes a history of previous questions and responses.
When using ellmer code non-interactively within an R script as part of a larger workflow, the documentation suggests wrapping your code inside an R function, like so:
my_function
In this case, my_answer is a simple text string.
The package also includes documentation for tool/function calling, prompt design, extracting structured data, and more. I’ve used it along with the shinychat package to add chatbot capabilities to a Shiny app. You can see example code that creates a simple Shiny chat interface for Ollama local models on your system, including dropdown model selection and a button to download the chat, in this public GitHub gist.
Note that ellmer started life as elmer, but they are branches of the same resulting package.
tidyllm
Some of tidyllm’s capabilities overlap with ellmer’s, but its makers say the interface and design philosophy are very different. For one thing, tidyllm combines “verbs”—the type of request you want to make, such as chat() or send_batch()—with providers. Requests include text embeddings (generating numerical vectors to quantify the semantic meaning of a text string) as well as chats and batch processing.
tidyllm currently supports Anthropic Claude models, OpenAI, Google Gemini, Mistral, Groq (which is not grok), Perplexity, Azure, and local Ollama models. If using a cloud provider, you’ll need to set up your API key either with Sys.setenv() or in your .Renviron file.
Querying
A simple chat query typically starts by creating an LLMMessage object via the llm_message("your query here") function, and then piping that to a chat() function, such as
library(tidyllm)
my_conversation
chat(openai(.model = "gpt-4o-mini", .temperature = 0, .stream = FALSE))
The llm_message() can also include a .system_prompt message.
The returned value of my_conversation is just a text string with the model’s response, which is easy to print out.
You can build on that by adding another message and chat, which will keep the original query and response in memory, such as:
# Keep history of last message
my_conversation2
llm_message("How would I rotate labels on the x-axis 90 degrees?") |>
chat(openai(.model = "gpt-4o-mini", .temperature = 0, .stream = FALSE))
print(my_conversation2)
It’s possible to extract some metadata from the results with
result_metadata
which returns a tibble (a special data frame) with columns for model, timestamp, prompt_tokens, completion_tokens, total_tokens (which oddly was the same as completion_tokens when I tested in some cases), and api_specific lists with more token details. You can also extract the user message that generated the reply with get_user_message(my_conversation2).
llm_message() also supports sending images to models that support such uploads with the .imagefile argument. And, you can ask questions about PDF files with the .pdf argument (make sure you also have the pdftools R package installed). For example, I downloaded the tidyllm PDF reference manual from CRAN to a file named tidyllm.pdf in a files subdirectory, and then asked a question using tidyllm with R:
my_conversation3
chat(openai(.model = "gpt-4o", .temperature = .1, .stream = FALSE))
result_metadata3 <- get_metadata(my_conversation3) showed that my query used 22,226 input tokens and 556 output tokens. At $2.50 per million input tokens, that interaction was around 5.5 cents for the query part to include the entire 58-page PDF in the question, plus another half a cent or so for the response (at $10 per million).
I tried the same query with Claude Sonnet 3.5 and I estimate it cost around 7.7 cents for my query, including the entire 58-page PDF, plus another penny or so for the output (which is $15 per million).
However, if I built up several other questions on top of that, the tokens could add up. This code is just to show package syntax and capabilities, by the way; it’s not an efficient way to query large documents. (See the section on RAG and Ragnar later in the article for a more typical approach.)
If you don’t need immediate responses, another way to trim spending is to use lower-cost batch requests. Several providers, including Anthropic, OpenAI, and Mistral, offer discounts of around 50% for batch processing. The tidyllm send_batch() function submits such a request, check_batch() checks on the status, and fetch_batch() gets the results. You can see more details on the tidyllm package website.
tidyllm was created by Eduard Brüll, a researcher at the ZEW economic think tank in Germany.
batchLLM
As the name implies, batchLLM is designed to run prompts over multiple targets. More specifically, you can run a prompt over a column in a data frame and get a data frame in return with a new column of responses. This can be a handy way of incorporating LLMs in an R workflow for tasks such as sentiment analysis, classification, and labeling or tagging.
It also logs batches and metadata, lets you compare results from different LLMs side by side, and has built-in delays for API rate limiting.
batchLLM’s Shiny app offers a handy graphical user interface for running LLM queries and commands on a column of data.
batchLLM also includes a built-in Shiny app that gives you a handy web interface for doing all this work. You can launch the web app with batchLLM_shiny() or as an RStudio add-in, if you use RStudio. There’s also a web demo of the app.
batchLLM’s creator, Dylan Pieper, said he created the package due to the need to categorize “thousands of unique offense descriptions in court data.” However, note that this “batch processing” tool does not use the less expensive, time-delayed LLM calls offered by some model providers. Pieper explained on GitHub that “most of the services didn’t offer it or the API packages didn’t support it” at the time he wrote batchLLM. He also noted that he had preferred real-time responses to asynchronous ones.
Two more tools to watch
We’ve looked at three top tools for integrating large language models into R scripts and programs. Now let’s look at a couple more tools that focus on specific tasks when using LLMs within R: retrieving information from large amounts of data, and scripting common prompting tasks.
ragnar (RAG for R)
RAG, or retrieval augmented generation, is one of the most useful applications for LLMs. Instead of relying on an LLM’s internal knowledge or directing it to search the web, the LLM generates its response based only on specific information you’ve given it. InfoWorld’s Smart Answers feature is an example of a RAG application, answering tech questions based solely on articles published by InfoWorld and its sister sites.
A RAG process typically involves splitting documents into chunks, using models to generate embeddings for each chunk, embedding a user’s query, and then finding the most relevant text chunks for that query based on calculating which chunks’ embeddings are closest to the query’s. The relevant text chunks are then sent to an LLM along with the original question, and the model answers based on that provided context. This makes it practical to answer questions using many documents as potential sources without having to stuff all the content of those documents into the query.
There are numerous RAG packages and tools for Python and JavaScript, but not many in R beyond generating embeddings. However, the ragnar package, currently very much under development, aims to offer “a complete solution with sensible defaults, while still giving the knowledgeable user precise control over all the steps.”
Those steps either do or will include document processing, chunking, embedding, storage (defaulting to DuckDB), retrieval (based on both embedding similarity search and text search), a technique called re-ranking to improve search results, and prompt generation.
If you’re an R user and interested in RAG, keep an eye on ragnar.
tidyprompt
Serious LLM users will likely want to code certain tasks more than once. Examples include generating structured output, calling functions, or forcing the LLM to respond in a specific way (such as chain-of-thought).
The idea behind the tidyprompt package is to offer “building blocks” to construct prompts and handle LLM output, and then chain those blocks together using conventional R pipes.
tidyprompt “should be seen as a tool which can be used to enhance the functionality of LLMs beyond what APIs natively offer,” according to the package documentation, with functions such as answer_as_json(), answer_as_text(), and answer_using_tools().
A prompt can be as simple as
library(tidyprompt)
"Is London the capital of France?" |>
answer_as_boolean() |>
send_prompt(llm_provider_groq(parameters = list(model = "llama3-70b-8192") ))
which in this case returns FALSE. (Note that I had first stored my Groq API key in an R environment variable, as would be the case for any cloud LLM provider.) For a more detailed example, check out the Sentiment analysis in R with a LLM and ‘tidyprompt’ vignette on GitHub.
There are also more complex pipelines using functions such as llm_feedback() to check if an LLM response meets certain conditions and user_verify() to make it possible for a human to check an LLM response.
You can create your own tidyprompt prompt wraps with the prompt_wrap() function.
The tidyprompt package supports OpenAI, Google Gemini, Ollama, Groq, Grok, XAI, and OpenRouter (not Anthropic directly, but Claude models are available on OpenRouter). It was created by Luka Koning and Tjark Van de Merwe.
The bottom line
The generative AI ecosystem for R is not as robust as Python’s, and that’s unlikely to change. However, in the past year, there’s been a lot of progress in creating tools for key tasks programmers might want to do with LLMs in R. If R is your language of choice and you’re interested in working with large language models either locally or via APIs, it’s worth giving some of these options a try.
{kind=link}
Fortran, Delphi rise in Tiobe popularity index 10 Mar 2025, 10:47 pm
Older programming languages such as Fortran and Delphi are making a comeback, based on the results of this month’s Tiobe index of language popularity. Tiobe attributes their rise to the need to maintain vital legacy systems still dependent on them.
Fortran and Delphi are competing for a top 10 spot in the index, with Delphi/Object Pascal ranking 10th and Fortran 11th in the Tiobe index for March 2025, published March 10. Ada, ranked 18th, and Cobol, ranked 20th, also are trending upward. Fortran ranked 10th as recently as January.
Tiobe CEO Paul Jansen found it interesting to see these four “very old languages” sneaking into the top 20. “I think that it has to do with the many vital legacy systems that keep the world running,” he said. “Most of them are developed with the aid of these dinosaur languages. Now that the last of the core developers of these systems are about to retire, companies avoid any risk and choose to keep the existing systems and even extend them rather than replacing them by newer systems based on more modern languages.” These languages have evolved and are pretty up-to-date, he added.
The ratings in Tiobe’s index are based on the number of skilled engineers worldwide, courses, and third-party vendors pertinent to a language. These are calculated using Google, Bing, Amazon, Wikipedia, and more than 20 other websites.
The Tiobe index top 10 for March 2025:
- Python, with a rating of 23.85%
- C++, 11.08%
- Java, 10.36%
- C, 9.53%
- C#, 4.87%
- JavaScript, 3.46%
- Go, 2.78%
- SQL, 2.57%
- Visual Basic, 2.52%
- Delphi/Object Pascal, 2.15%
The rival Pypl Popularity of Programming Language index ranks the languages by analyzing how often they are searched on in Google.
The Pypl index top 10 for March 2025:
- Python, with a share of 30.27%
- Java, 14.89%
- JavaScript, 7.78%
- C/C++, 7.12%
- C#, 6.11%
- R, 4.54
- PHP, 3.74%
- Rust, 3.14%
- TypeScript, 2.78%
- Objective-C, 2.74%
{kind=link}
Page processed in 0.202 seconds.
Powered by SimplePie 1.3.1, Build 20121030095402. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.