Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Cost-conscious repatriation strategies | InfoWorld
Technology insight for the enterpriseCost-conscious repatriation strategies 20 Dec 2024, 10:00 am
In recent years, the cloud computing landscape has undergone a seismic shift. After fully embracing the potential of public cloud services, many companies are reevaluating their strategies and shifting workloads back to on-premises infrastructures.
This trend, known as cloud repatriation, is driven by rising costs and increasing complexities in public cloud environments. More and more repatriation projects are underway as enterprises continue to receive exorbitant cloud bills. Many enterprises now realize that the unexpectedly high costs of cloud services are unsustainable in the long term.
GEICO has made headlines for its decision to repatriate numerous workloads back to on-premises solutions. In a recent interview, Rebecca Weekly, the vice president of platform and infrastructure engineering, said the initial goal of moving to the cloud was to reduce costs and complexity, but it ultimately had the opposite effect.
After a decade of cloud investments, GEICO’s bills spiked at 2.5 times the anticipated costs and the company faced increased reliability challenges. This tracks with what I’ve written in my book, An Insider’s Guide to Cloud Computing. These are the typical problems enterprises face when they use a haphazard lift-and-shift migration strategy that fails to align legacy systems with cloud efficiencies.
GEICO is not an isolated case. Across industries, organizations are discovering that data storage in the public cloud can be prohibitively expensive, mainly when their operational needs rely on vast amounts of data that require efficient and affordable management.
For enterprises operating in sectors such as finance or insurance, regulatory compliance further complicates matters. Companies must retain enormous volumes of sensitive data for long periods, often resulting in sky-high cloud storage expenses. Approaches to cloud computing that were once considered revolutionary are now viewed as a potential liability.
Rethinking cloud
First, this is not a pushback on cloud technology as a concept; cloud works and has worked for the past 15 years. This repatriation trend highlights concerns about the unexpectedly high costs of cloud services, especially when enterprises feel they were promised lowered IT expenses during the earlier “cloud-only” revolutions.
Leaders must adopt a more strategic perspective on their cloud architecture. It’s no longer just about lifting and shifting workloads into the cloud; it’s about effectively tailoring applications to leverage cloud-native capabilities—a lesson GEICO learned too late. A holistic approach to data management and technology strategies that aligns with an organization’s unique needs is the path to success and lower bills.
Organizations are now exploring hybrid environments that blend public cloud capabilities with private infrastructure. A dual approach, which is nothing new, allows for greater data control, reduced storage and processing costs, and improved service reliability. Weekly noted that there are ways to manage capital expenditures in an operational expense model through on-premises solutions. On-prem systems tend to be more predictable and cost-effective over time.
Moreover, the rise of open source technologies provides a pathway for companies seeking to modernize their infrastructure. The open source approach avoids burdensome costs associated with traditional public cloud providers. By leveraging frameworks like Kubernetes for container orchestration and OpenStack for private cloud deployments, businesses can regain control over their data and resources while minimizing dependence on public cloud offerings. Of course, this comes with its own set of cautions. Containers cost more than traditional development. Still, when deployed on owned hardware, you’ve already paid for the excess memory, processor, and storage resources they use.
A trend or just a few cases?
The current rash of cloud repatriations is emblematic of a broader reevaluation of how businesses approach their technological infrastructure. The era of indiscriminate cloud adoption is giving way to a more tempered and pragmatic approach. We’ve learned that it pays to incorporate operational costs, compliance requirements, and specific business use cases into infrastructure design.
Many cloud providers don’t know they have a repatriation problem because it has not yet impacted revenue. They’re also distracted by the amount of AI experimentation going on, which has a massive impact on public cloud providers’ services. However, if cloud providers don’t get a clue about the assistance their clients need to reduce cloud costs, we’ll see more and more repatriation in the next several years.
Technology leaders must now, more than ever, comprehensively understand their company’s unique data landscape and leverage cost-effective solutions that empower their business. That seems like common sense, but I’m disturbed by the number of firms that blindly adopt cloud computing without adequately understanding its impact. Many are now hitting a cloud wall for reasons that have nothing to do with cloud technology’s limitations; they’re the results of bad business decisions, plain and simple. Expect more companies to follow GEICO’s lead as we advance into 2025.
{kind=link}
Smart policing revolution: How Kazakhstan is setting a global benchmark 20 Dec 2024, 5:08 am
In the era of digital transformation, public safety stands at a critical crossroads. Law enforcement agencies globally are under increasing scrutiny to enhance transparency, efficiency, and trust within their communities. Against this backdrop, Kazakhstan’s “Digital Policeman” initiative has emerged as a shining example of technological innovation in policing.
The initiative leverages state-of-the-art technologies like smart badges and military-grade mobile devices, designed to empower officers while ensuring accountability. These smart badges go beyond conventional body cameras, offering features such as continuous, tamper-proof video recording, GPS tracking, encrypted data handling, and emergency alert systems. This cutting-edge approach has turned routine policing into a sophisticated operation backed by real-time data and insights.
Why it matters: Key impacts
The numbers speak volumes. Since its inception, the Digital Policeman project has documented over 6,000 bribery attempts, recorded 443,765 administrative violations, and solved 2,613 crimes—all while saving Kazakhstan’s national budget $6 million. With over 10,000 smart badges and 21,000 tablets deployed, the project is reshaping the very fabric of public safety.
These advancements extend beyond technology. By addressing the limitations of traditional tools, such as unreliable video recorders prone to tampering, the project has reduced corruption, streamlined workflows, and enhanced officer safety. Moreover, officers now have access to tools that enable quicker decision-making and more effective resource allocation, fostering greater community trust.
Global leadership in law enforcement innovation
The success of the Digital Policeman initiative positions Kazakhstan as a leader in police modernization, standing shoulder-to-shoulder with global pioneers like the United States, Korea, and Scotland. The initiative’s integration of secure, military-grade technology sets a benchmark, inspiring other nations, including Azerbaijan, Kyrgyzstan, and Uzbekistan, to explore similar advancements.
Looking ahead: The future of public safety
Kazakhstan is not stopping here. The initiative is poised for expansion, with plans to incorporate advanced features like facial recognition and direct integration with law enforcement databases. These enhancements will further amplify operational efficiency, enabling real-time communication of alerts and seamless access to critical information during patrols.
Beyond policing, this technology holds potential applications in other public safety domains such as traffic management, fisheries supervision, and forestry oversight. By extending the reach of smart badges, Kazakhstan continues to redefine the possibilities of public safety in the digital age.
Why read the full spotlight paper?
This article only scratches the surface of the profound impact the Digital Policeman project is making. For a comprehensive look at the strategies, technologies, and lessons learned from this groundbreaking initiative, download the full spotlight paper. Discover how Kazakhstan is charting the future of law enforcement, balancing technological innovation with community trust.
Unlock the future of policing. Download the full report today!
{kind=link}
Go 1.24 brings full support for generic type aliases 19 Dec 2024, 10:00 am
Go 1.24, a planned update to Google‘s popular open-source programming language, has reached the release candidate stage. Expected to arrive in February 2025, the release brings full support for generic type aliases, along with the ability to track executable dependencies using tool directives in Go modules.
Draft release notes for Go 1.24 note that the release brings full support for generic type aliases, in which a type alias may be parameterized like a defined type. Previously, A type alias could refer to a generic type, but the type alias could not have its own parameters. For now, generic type aliases can be disabled by setting GOEXPERIMENT=noaliastypeparams. This parameter setting will be removed in Go 1.25.
With the go command in Go 1.24, Go modules now can track executable dependencies using tool directives in go.mod files. This removes the need for a previous workaround of adding tools as blank imports to a file conventionally named tools.go. The go tool command now can run these tools in addition to tools shipped with the Go distribution. Also with the go command, a new GOAUTH environment variable offers a flexible way to authenticate private module fetches.
Cgo, for creating Go packages that call C code, now supports new annotations for C functions to improve runtime performance. With these improvements, #cgo noescape cFunctionName tells the compiler that memory passed to the C function cFunctionName does not escape. Also, #cgo nocallback cFunctionName tells the compiler that the C function cFunctionName does not call back to any Go functions.
Other new features and improvements in Go 1.24:
- Multiple performance improvements to the runtime in Go 1.24 have decreased CPU overheads by 2% to 3% on average across a suite of representative benchmarks.
- A new
testsanalyzer reports common mistakes in declarations of tests, fuzzers, benchmarks, and examples in test packages, such as incorrect signatures, or examples that document non-existent identifiers. Some of these mistakes might cause tests not to run. - The
cmd/gointernal binary and test caching mechanism now can be implemented by child processes implementing a JSON protocol between thecmd/gotool and the child process named by theGOCACHEPROGenvironment variable. - An experimental
testing/synctestpackage supports testing concurrent code. - The debug/elf package adds several new constants, types, and methods to add support for handling dynamic versions and version flags in ELF (Executable and Linkable Format) files.
- For Linux, Go 1.24 requires Linux kernel version 3.2 or later.
Go 1.24 follows Go 1.23, released in August, featuring reduced build times for profile-guided optimization.
{kind=link}
FAQ: Getting started with Bluesky 19 Dec 2024, 10:00 am
What is Bluesky?
Bluesky is a “microblogging” social media network similar to X (formerly Twitter), where people can publish posts with a maximum of 300 characters, as well as follow others, create lists, like posts, and so on. “Similar to Twitter” makes sense, because Bluesky was originally a project within Twitter to develop a more open and decentralized social network. Bluesky’s AT Protocol is open source.
Bluesky started as an invitation-only network last year and opened to the public in early 2024.
Why Bluesky?
The Bluesky network’s recent mainstream prominence is due largely to users leaving X over decisions by owner Elon Musk. But there’s a lot more to Bluesky than US politics.
Bluesky has a mix of technical and general discussions, with accounts like the Linux Foundation, Hugging Face, and xkcd comic creator Randall Munro, along with more mainstream organizations such as CNN, the Financial Times, and The Onion. I’ve even found some local TV meteorologists.
The platform’s appeal includes user-created “starter packs” that make it easy to find and follow people by topic, robust moderation tools, and the option to view posts either chronologically or via built-in or user-generated feeds.
These features have encouraged creation of communities-within-communities like Blacksky, launched by technologist Rudy Fraser. That project aims to offer content “created by and for Black users” as well as moderation tools designed to preemptively block online harassment that many Black users often experience.
Two of the chief complaints against X are the difficulty many users had in seeing content they actually wanted and the inability to control online harassment. Stopping harassment and hate speech remains imperfect at Bluesky, too, but Bluesky gives users more control over both — without making them do all the blocking and reporting themselves. Instead, users can subscribe to block lists and labeling tools created by others whom they trust.
“Shoutout to @blacksky.app,” one user posted recently. “A racist account just tried to interact with me, the content was blocked by Blacksky. I didn’t even have to see it. I feel safe for the first time in a long time online.”
How do I get started as a user?
One of Bluesky’s advantages compared to Mastodon, another decentralized open-source option, is its easy onboarding. Simply head to https://bsky.app and sign up. (Mastodon users need to choose a server, which can be a deal-breaker for those who don’t want to research server advantages before joining a network.)
You can choose a username at the default bsky.social domain, such as my @smachlis.bsky.social. Or, you can use a web domain you control as your Bluesky user name, such as @linuxfoundation.org. See “How to verify your Bluesky account” for instructions.
How can I find people to follow?
Besides the slow, manual way of searching for accounts you follow elsewhere or scrolling the Discover feed to see accounts of interest, some tools can help.
User-created started packs, mentioned above, will let you find people based on various topics. You can use Bluesky’s search to look for phrases such as Rstats starter pack or Python starter pack. Or, there are third-party searchable starter pack listings such as Bluesky Directory’s. You can subscribe to all users in a starter pack with one click or decide whether to follow each account individually.
If you were previously on X, there’s a Chrome extension called Sky Follower Bridge that lets you search for people you followed there to follow on Bluesky.
Feeds are another way to find content by topic. Third-party tools such as Bluesky Feeds have been a bit fragile recently as usage soars, but they may still be worth a try. Another way to find feeds is to look at the Feeds tab on a user’s profile page to see if they have any of interest. For example, I built a Fave data hashtags feed that looks for #RStats, #QuartoPub, #RLadies, or #PyLadies as well as the non-hashtag DuckDB. It uses the free Skyfeed Builder (and can be slow to load).
As with most social networks, you can also view posts with a specific hashtag. I just bookmark these in my browser, such as https://bsky.app/hashtag/rstats for rstats (case doesn’t matter).
There are a lot more Bluesky tools listed at the GitHub repo Awesome Bluesky.
But don’t discount the Discover feed, which is somewhat customizable. As you scroll that feed, you can click the three dots on a post to see an additional menu that includes options to “Show more like this” or “Show less like this.”
How do I subscribe to moderation and labeling lists?
Once you find a labeler, it’s a simple matter of clicking the subscribe button. Once you do, you can choose to hide, be warned, or disable each label’s posts. Moderation lists let you report a post to the list’s moderation, not relying solely on Bluesky’s main team.
IDG
The third-party BlueSky Labelers site has a directory of some labelers. Some of these are used for moderation and others for matters of interest, such as verifying Microsoft employees or labeling GitHub repositories you contribute to.
Who owns Bluesky?
Bluesky spun off from Twitter in 2021 and is currently a Public Benefit Corporation (similar to Posit, formerly RStudio), which means it can legally take the interests of its user community into account and not only its owners. The Bluesky site says the company is owned by “[CEO] Jay Graber and the Bluesky team,” although it has also announced investments from companies including Blockchain Capital (it says it is not getting involved in crypto).
Bluesky executives have said that since its underlying protocol is open source, if something were to happen to its ownership, another entity could spin up infrastructure and allow people to port their accounts to another server. However, Mastodon advocates argue that the same single server and ownership team that make Bluesky easier to use, also increase the risk of the service being sold as Twitter was.
How does Bluesky make money?
Bluesky doesn’t run ads. The company says it has raised $15 million in Series A financing and has plans for a premium user subscription service. Paying subscribers won’t get any kind of algorithm boost, but they could get additional features such as posting higher-quality videos or customized profiles.
How can I build something around Bluesky?
For those of us who like to code, there’s a free API. “Bluesky is an open ecosystem with an API that is guaranteed to always be open to developers,” CEO Jay Graber posted. Bluesky’s underlying protocol is open source under the MIT or Apache Version 2.0 license. (Twitter started charging for its API in February 2023.)
You can code your own custom feeds to use and share or use third-party tools like SkyFeed, which author @redsolver.dev says will be open-sourced “soon.”
Bluesky has starter templates for building bots, custom feeds, and client apps.
For R users, there are two packages, atrrr and bskyr, not currently listed on the official SDK page. See my companion article on using atrrr to create a searchable collection of Bluesky bookmarks. Check the Bluesky documentation to see options in TypeScript, Python, Dart, and Go.
How big is Bluesky?
While still tiny in total users compared to alternatives like X or Threads, Bluesky is growing. The platform jumped from around 12 million registered users in mid-October to more than 24 million today. Total visits to the bsky.app website, which excludes mobile apps and other third-party tools, soared to 122.7 million in November vs. 75.8 million in October.
Some in the media say they’re getting more engagement on the platform than sites that are larger. “Traffic from Bluesky to @bostonglobe.com is already 3x that of Threads, and we are seeing 4.5x the conversions to paying digital subscribers,” posted Matt Karolian, vice president of platforms and R&D at the Boston Globe.
{kind=link}
Create searchable Bluesky bookmarks with R 19 Dec 2024, 10:00 am
The Bluesky social network is seeping into the mainstream, thanks in part to people unhappy with changes at X (formerly Twitter). “It’s not some untouched paradise, but it’s got a spark of something refreshing,” Jan Beger, global head of AI Advocacy at GE HealthCare, posted on LinkedIn last month. “Like moving to a new neighborhood where the air feels a little clearer, and people actually wave when they see you.”
That includes an increasing number of R users, who often use the hashtag #rstats. “Bluesky is taking off! Please join us there with this handy Posit employees starter pack,” Posit (formerly RStudio) wrote in its December newsletter. Starter packs make it easy to find and follow other Bluesky users based on topics and interests, either one by one or with a single click. Any user can create them. (See my companion FAQ on Bluesky with tips for getting started.)
However, because Bluesky is relatively new (it opened to the general public early this year), some features that are standard on other microblogging platforms aren’t yet available. One of the most sorely missed is “bookmarks” — being able to save a liked post for easy retrieval later. There are a couple of workarounds, either with third-party apps or custom feeds. In addition, thanks to Bluesky’s free API and the atrrr R package, you can use R to save data locally of all your liked posts — and query them however you want. Here’s how.
Save and search your Bluesky likes
This project lets you download your Bluesky likes, wrangle the data, save it, and load it into a searchable table. Optionally, you can save the data to a spreadsheet and manually mark the ones you want to consider as bookmarks, so you can then search only those.
For even more functionality, you can send the results to a generative AI chatbot and ask natural language questions instead of searching for specific words.
Let’s get started!
Step 1. Install the atrrr R package
I suggest installing the development version of the atrrr R package from GitHub. I typically use the remotes package for installing from GitHub, although there are other options such as devtools or pak.
remotes::install_github("JBGruber/atrrr", build_vignettes = TRUE)
I’ll also be using dplyr, purrr, stringr, tidyr, and rio for data wrangling and DT to optionally display the data in a searchable table. Install those from CRAN, then load them all with the following code.
library(atrrr)
library(dplyr)
library(purrr)
library(stringr)
library(tidyr)
library(rio)
library(DT) # optional
You will need a free Bluesky application password (different from your account password) to request data from the Bluesky API. The first time you make a request via atrrr, the app should helpfully open the correct page on the Bluesky website for you to add an app password, if you’re already logged into Bluesky in your default browser. Or, you can go here to create an app password in advance.
Either way, when you first use the atrrr package, you’ll be asked to input an application password if there’s not one already stored. Once you do that, a token should be generated and stored in a cache directory at file.path(tools::R_user_dir("atrrr", "cache"), Sys.getenv("BSKY_TOKEN", unset = "token.rds")). Future requests should access that token automatically.
You can find more details about Bluesky authentication at the atrrr package website.
Step 2. Download and wrangle your Bluesky likes
The get_actor_likes() function lets you download a user’s likes. Here’s how to download your 100 most recent likes:
my_recent_likes
Note: As of this writing, if you ask for more likes than there actually are, you’ll get an error. If that happens, try a smaller number. (You may end up with a larger number anyway.)
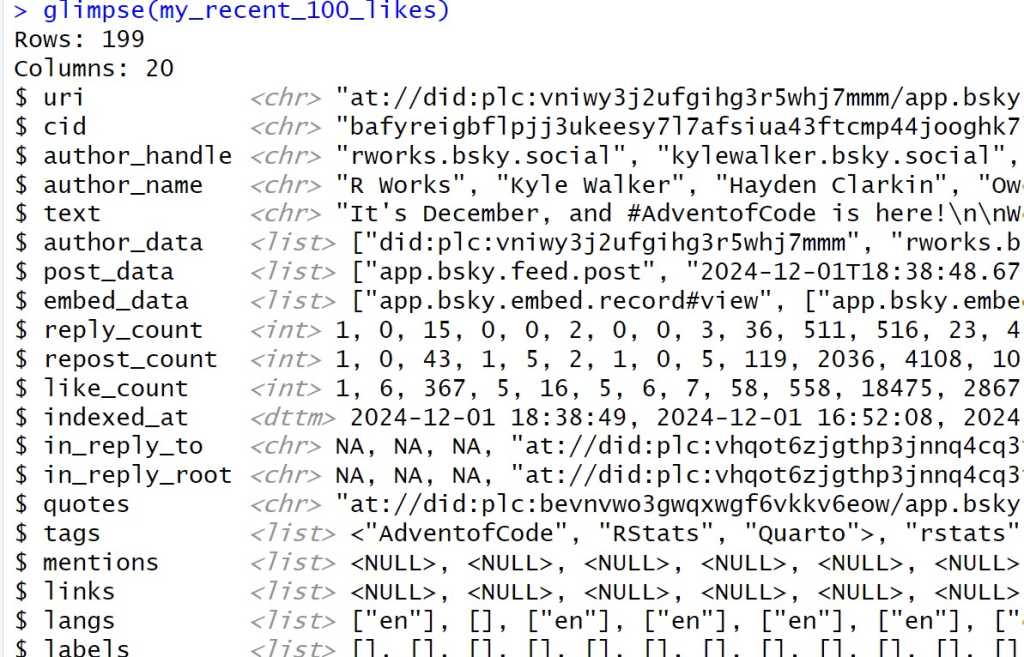
The get_actor_likes() command above returns a data frame — more specifically a tibble, which is a special type of tidyverse data frame — with 20 columns. However, some of those columns are list columns with nested data, which you can see if you run glimpse(my_recent_likes). You’ll probably want to extract some information from those.
IDG
As shown above, each liked post’s text, author_name, author_handle, like_count, and repost_count are arranged in conventional (unnested) columns. However, the timestamp when the post was created is nested inside the posted_data list column, while any URLs mentioned in a post are buried deep within the embed_data column.
Here’s one way to unnest those columns using the tidyr package’s unnest_wider() function:
my_recent_likes_cleaned
unnest_wider(post_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data_external, names_sep = "_", names_repair = "unique")
That creates a data frame (tibble) with 40 columns. I’ll select and rename the columns I want, and add a TimePulled timestamp column, which could come in handy later.
my_recent_likes_cleaned
select(Post = text, By = author_handle, Name = author_name, CreatedAt = post_data_createdAt, Likes = like_count, Reposts = repost_count, URI = uri, ExternalURL = embed_data_external_uri) |>
mutate(TimePulled = Sys.time() )
Another column that would be useful to have is the URL of each liked post. Note that the existing URI column is in a format like at://did:plc:oky5czdrnfjpqslsw2a5iclo/app.bsky.feed.post/3lbd2ee2qvm2r. But the post URL uses the syntax https://bsky.app/profile/{author_handle}/post/{a portion of the URI}.
The R code below creates a URL column from the URI and By columns, adding a new PostID column as well for the part of the URI used for the URL.
my_recent_likes_cleaned
mutate(PostID = stringr::str_replace(URI, "at.*?post\\/(.*?)$", "\\1"),
URL = glue::glue("https://bsky.app/profile/{By}/post/{PostID}") )
I typically save data like this as Parquet files with the rio package.
rio::export(my_recent_likes_cleaned, "my_likes.parquet")
You can save the data in a different format, such as an .rds file or a .csv file, simply by changing the file extension in the file name above.
Step 3. Keep your Bluesky likes file updated
It’s nice to have a collection of likes as a snapshot in time, but it’s more useful if you can keep it updated. There are probably more elegant ways to accomplish this, but a simple approach is to load the old data, pull some new data, find which rows aren’t in the old data frame, and add them to your old data.
previous_my_likes
Next, get your recent likes by running all the code we did above, up until saving the likes. Change the limit to what’s appropriate for your level of liking activity.
my_recent_likes
unnest_wider(post_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data_external, names_sep = "_", names_repair = "unique") |>
select(Post = text, By = author_handle, Name = author_name, CreatedAt = post_data_createdAt, Likes = like_count, Reposts = repost_count, URI = uri, ExternalURL = embed_data_external_uri) |>
mutate(TimePulled = Sys.time() ) |>
mutate(PostID = stringr::str_replace(URI, "at.*?post\\/(.*?)$", "\\1"),
URL = glue::glue("https://bsky.app/profile/{By}/post/{PostID}") )
Find the new likes that aren’t already in the existing data:
new_my_likes
Combine the new and old data:
deduped_my_likes
And, finally, save the updated data by overwriting the old file:
rio::export(deduped_my_likes, 'my_likes.parquet')
Step 4. View and search your data the conventional way
I like to create a version of this data specifically to use in a searchable table. It includes a link at the end of each post’s text to the original post on Bluesky, letting me easily view any images, replies, parents, or threads that aren’t in a post’s plain text. I also remove some columns I don’t need in the table.
my_likes_for_table
mutate(
Post = str_glue("{Post} >>"),
ExternalURL = ifelse(!is.na(ExternalURL), str_glue("{substr(ExternalURL, 1, 25)}..."), "")
) |>
select(Post, Name, CreatedAt, ExternalURL)
Here’s one way to create a searchable HTML table of that data, using the DT package:
DT::datatable(my_likes_for_table, rownames = FALSE, filter = 'top', escape = FALSE, options = list(pageLength = 25, autoWidth = TRUE, filter = "top", lengthMenu = c(25, 50, 75, 100), searchHighlight = TRUE,
search = list(regex = TRUE)
)
)
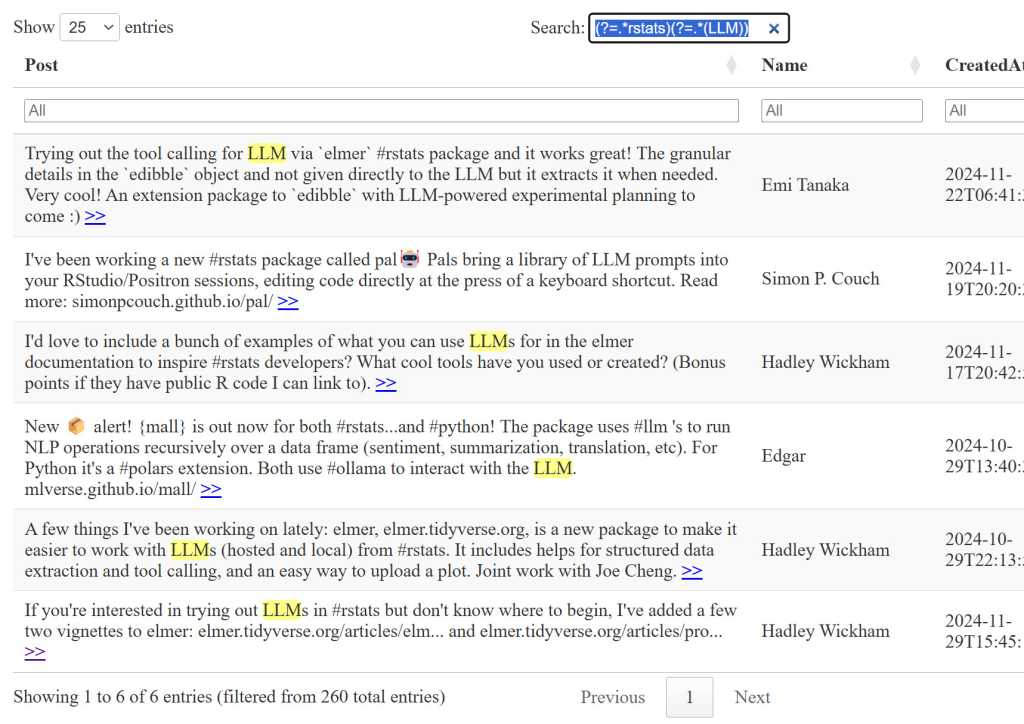
This table has a table-wide search box at the top right and search filters for each column, so I can search for two terms in my table, such as the #rstats hashtag in the main search bar and then any post where the text contains LLM (the table’s search isn’t case sensitive) in the Post column filter bar. Or, because I enabled regular expression searching with the search = list(regex = TRUE) option, I could use a single regexp lookahead pattern (?=.rstats)(?=.(LLM)) in the search box.
IDG
Generative AI chatbots like ChatGPT and Claude can be quite good at writing complex regular expressions. And with matching text highlights turned on in the table, it will be easy for you to see whether the regexp is doing what you want.
Query your Bluesky likes with an LLM
The simplest free way to use generative AI to query these posts is by uploading the data file to a service of your choice. I’ve had good results with Google’s NotebookLM, which is free and shows you the source text for its answers. NotebookLM has a generous file limit of 500,000 words or 200MB per source, and Google says it won’t train its large language models (LLMs) on your data.
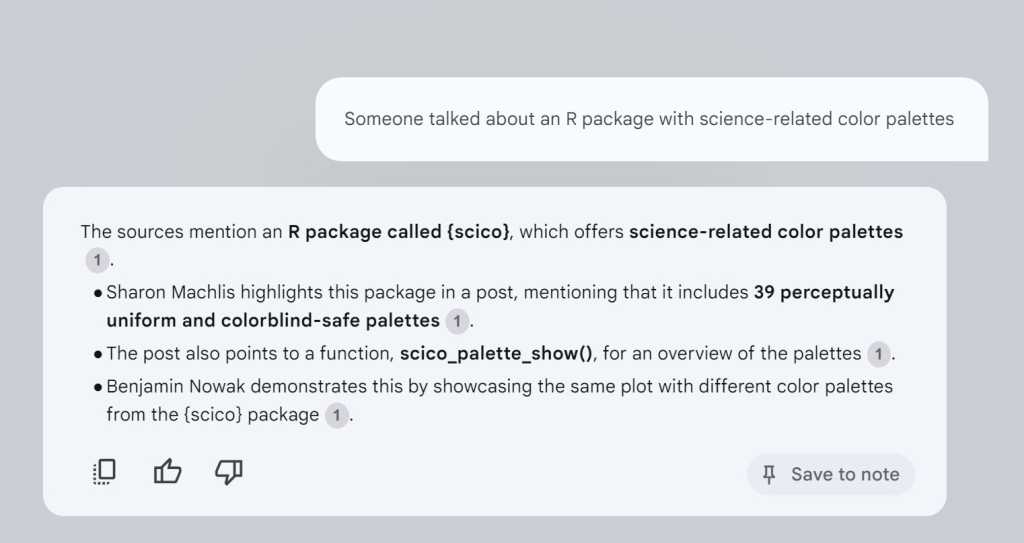
The query “Someone talked about an R package with science-related color palettes” pulled up the exact post I was thinking of — one which I had liked and then re-posted with my own comments. And I didn’t have to give NotebookLLM my own prompts or instructions to tell it that I wanted to 1) use only that document for answers, and 2) see the source text it used to generate its response. All I had to do was ask my question.
IDG
I formatted the data to be a bit more useful and less wasteful by limiting CreatedAt to dates without times, keeping the post URL as a separate column (instead of a clickable link with added HTML), and deleting the external URLs column. I saved that slimmer version as a .txt and not .csv file, since NotebookLM doesn’t handle .csv extentions.
my_likes_for_ai
mutate(CreatedAt = substr(CreatedAt, 1, 10)) |>
select(Post, Name, CreatedAt, URL)
rio::export(my_likes_for_ai, "my_likes_for_ai.txt")
After uploading your likes file to NotebookLM, you can ask questions right away once the file is processed.

IDG
If you really wanted to query the document within R instead of using an external service, one option is the Elmer Assistant, a project on GitHub. It should be fairly straightforward to modify its prompt and source info for your needs. However, I haven’t had great luck running this locally, even though I have a fairly robust Windows PC.
Update your likes by scheduling the script to run automatically
In order to be useful, you’ll need to keep the underlying “posts I’ve liked” data up to date. I run my script manually on my local machine periodically when I’m active on Bluesky, but you can also schedule the script to run automatically every day or once a week. Here are three options:
- Run a script locally. If you’re not too worried about your script always running on an exact schedule, tools such as taskscheduleR for Windows or cronR for Mac or Linux can help you run your R scripts automatically.
- Use GitHub Actions. Johannes Gruber, the author of the atrrr package, describes how he uses free GitHub Actions to run his R Bloggers Bluesky bot. His instructions can be modified for other R scripts.
- Run a script on a cloud server. Or you could use an instance on a public cloud such as Digital Ocean plus a cron job.
Use a spreadsheet or R tool to add Bookmarks and Notes columns
You may want a version of your Bluesky likes data that doesn’t include every post you’ve liked. Sometimes you may click like just to acknowledge you saw a post, or to encourage the author that people are reading, or because you found the post amusing but otherwise don’t expect you’ll want to find it again.
However, a caution: It can get onerous to manually mark bookmarks in a spreadsheet if you like a lot of posts, and you need to be committed to keep it up to date. There’s nothing wrong with searching through your entire database of likes instead of curating a subset with “bookmarks.”
That said, here’s a version of the process I’ve been using. For the initial setup, I suggest using an Excel or .csv file.
Step 1. Import your likes into a spreadsheet and add columns
I’ll start by importing the my_likes.parquet file and adding empty Bookmark and Notes columns, and then saving that to a new file.
my_likes
mutate(Notes = as.character(""), .before = 1) |>
mutate(Bookmark = as.character(""), .after = Bookmark)
rio::export(likes_w_bookmarks, "likes_w_bookmarks.xlsx")
After some experimenting, I opted to have a Bookmark column as characters, where I can add just “T” or “F” in a spreadsheet, and not a logical TRUE or FALSE column. With characters, I don’t have to worry whether R’s Boolean fields will translate properly if I decide to use this data outside of R. The Notes column lets me add text to explain why I might want to find something again.
Next is the manual part of the process: marking which likes you want to keep as bookmarks. Opening this in a spreadsheet is convenient because you can click and drag F or T down multiple cells at a time. If you have a lot of likes already, this may be tedious! You could decide to mark them all “F” for now and start bookmarking manually going forward, which may be less onerous.
Save the file manually back to likes_w_bookmarks.xlsx.
Step 2. Keep your spreadsheet in sync with your likes
After that initial setup, you’ll want to keep the spreadsheet in sync with the data as it gets updated. Here’s one way to implement that.
After updating the new deduped_my_likes likes file, create a bookmark check lookup, and then join that with your deduped likes file.
bookmark_check
select(URL, Bookmark, Notes)
my_likes_w_bookmarks
relocate(Bookmark, Notes)
Now you have a file with the new likes data joined with your existing bookmarks data, with entries at the top having no Bookmark or Notes entries yet. Save that to your spreadsheet file.
rio::export(my_likes_w_bookmarks, "likes_w_bookmarks.xlsx")
An alternative to this somewhat manual and intensive process could be using dplyr::filter() on your deduped likes data frame to remove items you know you won’t want again, such as posts mentioning a favorite sports team or posts on certain dates when you know you focused on a topic you don’t need to revisit.
Next steps
Want to search your own posts as well? You can pull them via the Bluesky API in a similar workflow using atrrr’s get_skeets_authored_by() function. Once you start down this road, you’ll see there’s a lot more you can do. And you’ll likely have company among R users.
{kind=link}
Getting started with Azure Managed Redis 19 Dec 2024, 10:00 am
Microsoft has made a lot of big bets in its preferred cloud-native infrastructure. You only need to look at .NET Aspire and Radius to see how the company thinks you should be designing and building code: a growing cloud-native stack that builds on Kubernetes and associated tools to quickly build distributed applications at scale.
Azure CTO Mark Russinovich has regularly talked about one overarching goal for Azure: to make everything serverless. It’s why many tools we used to install on dedicated servers are now offered as managed services and Azure manages the underlying infrastructure. Services like Azure Container Instances allow you to quickly deploy Kubernetes applications, but what of the other services necessary to build at-scale containerized applications?
One key service is a caching in-memory database. Here Azure has relied on Redis, providing support for the Redis enterprise release as well as offering Azure Cache for Redis based on the lower-performance Redis community edition.
If you’re building a large application, you need more than a single-threaded database, as you’re leaving compute capabilities on the table. Azure Cache for Redis is unlikely to use all of the capabilities of the underlying vCPUs. As it requires two vCPUs for each instance, one primary and one replica for backup or failover, Azure Cache for Redis is not economical to use at scale.
Introducing Azure Managed Redis
At Ignite 2024, Microsoft announced the public preview of a managed service based on Redis Enterprise, taking advantage of it to improve performance so you can deliver bigger applications without requiring significant additional infrastructure. With data center power usage increasingly an issue, improving performance without increasing the number of required vCPUs helps Azure use its underlying servers more efficiently.
Shipping in preview as Azure Managed Redis, this new service is a higher-performance alternative to Azure Cache for Redis. It takes advantage of a new architecture that should significantly improve operations and support new deployment options.
Instead of one instance per VM, you’re now able to stack multiple instances behind a Redis proxy. There’s another big change: Although you still use two nodes, both nodes run a mix of primary and replica processes. A primary instance uses more resources than a replica, so this approach lets you get the best possible performance out of your VMs. At the same time, this mix of primary and replica nodes automatically clusters data to speed up access and enable support for geo-replication across regions.
Azure Managed Redis has two different clustering policies, OSS and Enterprise. The OSS option is the same as used by the community edition, with direct connections to individual shards. This works well, with close-to-linear scaling, but it does require specific support in any client libraries you’re using in your code. The alternative, Enterprise, works through a single proxy node, simplifying connection requirements for clients at the expense of performance.
Why would you use Redis in an application? In many cases it’s a tool for keeping regularly accessed data cached in memory, allowing quick read/write access. It’s being used any place you need a fast key/value store with support for modern features such as vector indexing. Using Redis as an in-memory vector index helps keep latency to a minimum in AI applications based on retrieval-augmented generation (RAG). Cloud-native applications can use Redis as a session store to manage state across container applications, so AI applications can use Redis as a cache for recent output, using it as semantic memory in frameworks like Semantic Kernel.
Setting up Azure Managed Redis
Microsoft is offering four different tiers that support different use cases and balance cost and performance. The lowest-cost option, best suited for development and test, is the memory-optimized tier. Here you have an 8:1 memory to vCPU ratio that works best when you need to store a lot of data for quick access but don’t need to process it significantly. The downside is a lower throughput, something that’s likely to be more of an issue in production.
Most applications will use the balanced option. This has a 4:1 memory to vCPU ratio, which will allow you to work with cached data as well as deliver it to applications. If you need more performance, there’s a compute-optimized tier, with a 2:1 memory to vCPU ratio, making it ideal for high-performance applications that may not need to cache a lot of data.
There’s one final configuration intended for applications that need to cache a lot of data, using NVMe flash to store data that’s not needed as often. These instances automatically tier your data for you, and although there may be a performance hit, it keeps the costs of large instances to a minimum. The architecture of this tier is interesting: It keeps all the keys in RAM and only stores values in flash when they’re found to be “cold.”
This approach is different from the standard data persistence feature, which makes a disk backup of in-memory data that can recover an instance if there’s an outage. Using this feature writes data to disk and only reads it when necessary; normal operations continue to be purely in-memory.
Once you have chosen the type of service you’re implementing, you can add it to an Azure resource group, using the Azure Portal. Start by creating a new resource and choosing the Redis Cache option from Databases. It’s important to note that there’s no explicit Azure Managed Redis control plane; it shares the same basic configuration screen as the existing Azure Cache for Redis. You’re not limited to using the portal, as there are Azure CLI, Bicep, and PowerShell options.
On the New Redis Cache screen, you’ll need to choose a Managed Redis SKU to unlock its configuration tools. This isn’t particularly clear, and you can easily miss this choice and accidentally pick the default Azure Cache for Redis settings. Once you’ve chosen a correct SKU, you can add modules from the Advanced tab, along with configuring the clustering policy and whether you’re using data persistence. You can now click Create and your instance will spin up. This can take some time, but once it’s running, it’s ready for use.
Choosing memory and compute
Within each tier are different memory and vCPU options, allowing you to choose the configuration that’s best for your application. For example, a balanced system starts with 500MB of storage and 2 vCPUs, with up to 1TB of storage and 256 vCPUs. Each option has its own list of storage and compute options, allowing you to dial in a specification that fits your workloads.
Available modules include support for search, time-series content, as well as JSON. It’s important to check that they work with your choice of SKU: If you’re using flash-optimized instances, you can’t use the time-series module or the Bloom probabilistic data structures, which are designed for working with streaming data.
Once configured you won’t be able to change many of its policies. Clustering, geo-replication, and modules are all configured during setup, and any changes require completely rebuilding your Redis setup from scratch. That’s not an issue for development and test, but it’s something to consider when running in production.
If you’re already using Azure Cache for Redis in your applications, you won’t need to make many changes to your code. The same Redis clients work for the new service, so all you need to do is configure the appropriate endpoints and use familiar query APIs. Azure recommends the StackExchange.Redis library for .NET developers. Redis keeps a list of its own client libraries for other languages, from Python to Java and more.
Azure’s latest Redis offering brings enterprise capabilities beyond its existing Azure Cache for Redis. This should help you build larger, more flexible cloud-native applications, as well as use in-memory data for more than simple key/value caching. As Azure Managed Redis moves towards general availability, hopefully we‘ll see Microsoft‘s cloud-native development frameworks like Aspire and Radius add support for automatically configuring its new services alongside their existing Redis support.
{kind=link}
GitHub launches free tier of Copilot AI coding assistant 18 Dec 2024, 11:19 pm
GitHub has launched GitHub Copilot Free, providing access to a free tier of the AI-based pair programmer via Microsoft’s Visual Studio Code editor.
Announced December 18, Copilot Free gives developers access to 2,000 code completions and 50 chat messages monthly. The service requires signing in with a personal GitHub account or creating a new one. Developers may choose between Anthropic’s Claude 3.5 Sonnet or OpenAI’s GPT-4o models. It’s possible to ask coding questions or find bugs, including searches across multiple files. Developers can also access Copilot third-party agents or build their own extensions.
Copilot Free is automatically integrated into VS Code. To access the free tier, VS Code users can press the Copilot icon at the top of the screen and click the “Sign in to use Copilot for Free” button. This opens a web browser where developers can sign in to GitHub and allow VS Code to connect to their account. VS Code will then automatically install GitHub Copilot. GitHub is launching Copilot Free in response to having passed 150 million developers on the GitHub platform.
{kind=link}
OpenAI rolls out upgrade to reasoning model, new dev tools 18 Dec 2024, 10:34 pm
The release Tuesday by OpenAI of OpenA1 o1, its reasoning model, in API, along with three new sets of tools for developers, is a “smart move that keeps [it] in the corporate/enterprise conversation, as so many customers are shifting their focus towards agentic applications over simpler chat-based applications,” an industry analyst said.
Jason Andersen, VP and principal analyst with Moor Insights & Strategies, also described it as “something of a defensive move, since we have seen AWS, Google, and Microsoft releasing API-based multi-model development frameworks such as Bedrock and AI Foundry.”
Some of those frameworks, he said, “do have OpenAI as a potential model target, but they also have new features such as model routing, which means that there is no guarantee that the framework vendor will consistently use OpenAPI.”
Released as part of its 12 days of Shipmas campaign, OpenAI o1 in API is production ready, the company said, and contains vision capabilities that allow it to “reason over images to unlock many more applications in science, manufacturing, or coding, where visual inputs matter.” Other enhancements include function calling to connect o1 to external data and APIs, as well as an API parameter that gives a developer the ability to “control how long model thinks before answering.” It is available to Tier 5 in the API.
Other additions to the toolset include enhancements to the Realtime API, which, OpenAI said, “allows developers to create low-latency, multi-modal conversational experiences. It currently supports both text and audio as inputs and outputs, as well as function calling capabilities.”
Key among them is integration with WebRTC, an open standard that makes it easier to build and scale real-time voice products across platforms. “Our WebRTC integration is designed to enable smooth and responsive interactions in real-world conditions, even with variable network quality,” the company said.
Also launched were Preference Fine Tuning, which it described as a new model customization technique that makes it easier to tailor models based on user and developer preferences, and new SDKs for Go and Java, both available in beta.
Andersen described the latter as “quite interesting, since those are two languages heavily used by developers who are using the public cloud. This and the APIs provide a meaningful alternative to someone just using the models a cloud provider has ‘on the shelf.’”
However, Forrester senior analyst Andrew Cornwall said, “when OpenAI says, ‘new tools for developers,’ they mean tools for AI developers — everyone else will start seeing things only after the AI developers get their hands on the goodies. That will take some time, since o1-2024-12-17 APIs are rolling out only to Tier 5 (their highest-usage users) today.”
He said that, looking at what was announced, “probably of most interest is vision support, a capability not in o1-preview. In addition, the latest o1 model should return more accurate responses and report fewer refusals than the preview.”
Math and coding capabilities, said Cornwall, “have improved from the preview, in some cases significantly — although o1’s reported score won’t dethrone Amazon Q as leader of the SWE-bench Verified leaderboard. OpenAI has also improved function calling and structured output — the abilities to call into a program from an AI query, and to return output in developer-friendly JSON rather than natural language.”
In addition, “[developers have] a new parameter to play with, reasoning effort, which will let them adjust between accuracy and speed,” he noted. “This will integrate nicely with WebRTC voice support — a pause for a few seconds is sometimes acceptable at a keyboard, but not when you’re having a conversation.”
He added, “more developers will get a chance to play with OpenAI’s most powerful model, with SDKs for Java and Go moving from alpha to beta. Businesses are eager to use AI, but many have been waiting for the stability that a beta might afford.”
“In short,” Cornwall said, “this isn’t revolutionary — most of the capabilities have been available in different models already — but with this release, a single model gets better at many modes and for many classes of problem.”
Added Thomas Randall, director of AI market research at Info-Tech Research Group, “with increased openness and flexibility for developers, OpenAI is aiming to maintain its market share as the go-to model provider for builders. Deeper dependencies may form between OpenAI’s model provision and the software companies that are already utilizing OpenAI for their own AI-enhanced offering.”
{kind=link}
Tabnine code assistant now flags unlicensed code 18 Dec 2024, 9:55 pm
Looking to minimize IP liability for generative AI output, Tabnine’s AI coding assistant now checks code for licensing restrictions.
The Code Provenance and Attribution capability added to the tool enables enterprise developers to use large language models (LLMs) while minimizing the possibility of restrictively licensed code being injected into a codebase. With this new feature, Tabnine will more easily support development teams and their legal and compliance teams who wish to leverage a variety of models, the company said.
Now in private preview, the Provenance and Attribution capability was announced on December 17. Tabnine now can check code generated using AI chat or AI agents against code publicly visible on GitHub. It then flags any matches and references the source repository and its license type. This detail makes it easier for engineering teams to review code being generated with the assistance of AI and decide if the license of that code meets specific requirements and standards, Tabnine said.
Models trained on larger pools of data outside of permissively licensed open source code can provide superior performance, but enterprises using them run the risk of running afoul of IP and copyright violations, Tabnine president Peter Guagenti said. The Code Provenance and Attribution capability addresses this tradeoff and increases productivity while not sacrificing compliance, according to Guagenti. And, with copyright law for using AI-generated content still unsettled, Tabnine’s proactive stance aims to reduce the risk of IP infringement when enterprises use models such as Anthropic’s Claude, OpenAI’s GPT-4o, and Cohere’s Command R+ for software development.
The Code Provenance and Attribution capability supports software development activities including code generation, code fixing, generating test cases, and implementing Jira issues. Future plans include allowing users to identify specific repositories, such as those maintained by competitors, for generated code checks. Tabnine also plans to add a censorship capability to allow administrators to remove matching code before it is displayed to the developer.
{kind=link}
From surveillance to safety: How Kazakhstan’s Carpet CCTV is reshaping security 18 Dec 2024, 10:30 am
In a world where technology increasingly shapes how cities manage safety and security, Kazakhstan’s Ministry of Internal Affairs is leading the way with its groundbreaking “Carpet CCTV” project. This ambitious initiative has revolutionized public safety by combining a massive surveillance network with advanced analytics and artificial intelligence, creating a system that shifts the focus from reactive responses to proactive prevention.
Over the past four years, the scope of Kazakhstan’s surveillance infrastructure has expanded dramatically. The number of cameras has grown from just 40,500 to an impressive 1.3 million, with 313,000 cameras now directly accessible to police. These cameras are strategically positioned to monitor key areas, enhancing law enforcement’s ability to detect, prevent, and respond to incidents in real time. The system has already shown its effectiveness: since early 2024, it has detected over 8,200 criminal offenses and recorded 7.1 million traffic violations, resulting in significant improvements in public safety and road management.
At the heart of this transformation is the use of artificial intelligence. By integrating cutting-edge technologies such as facial recognition, license plate detection, and crowd monitoring, the system provides actionable insights that allow authorities to address risks before they escalate. For example, facial recognition capabilities enable real-time identification of persons of interest, while AI-powered traffic monitoring contributes to improved road safety and generates public revenue through fines. These features highlight the system’s ability to go beyond passive recording, transforming it into a dynamic tool for crime prevention and urban management.
The implementation of the Carpet CCTV project, however, was not without challenges. Managing the enormous volume of data generated by over a million high-definition cameras required significant upgrades in communication networks and data storage infrastructure. The integration of public and private camera networks demanded a unified approach to data sharing and management, while privacy concerns necessitated robust regulatory frameworks to ensure citizen trust. Through a combination of strategic planning, public-private partnerships, and transparent communication, the Ministry successfully addressed these obstacles, setting a model for other nations to follow.
One of the project’s most significant achievements lies in its deterrent effect. Administrative offenses, such as public disturbances, have decreased sharply, indicating that the visible presence of surveillance cameras is influencing behavior. This demonstrates the power of technology not just to react to incidents, but to prevent them altogether. Furthermore, the use of video evidence has increased case resolution rates, further solidifying the system’s impact on law enforcement effectiveness.
Looking ahead, Kazakhstan plans to build on the success of Carpet CCTV by expanding its geographic coverage and enhancing its analytical capabilities. New developments will focus on leveraging advanced AI to improve the accuracy and scope of surveillance, while also incorporating adaptive privacy measures to protect civil liberties. This forward-thinking approach ensures the system remains at the forefront of public safety technology, balancing innovation with accountability.
Kazakhstan’s Carpet CCTV project represents more than just an investment in technology—it’s a vision for smarter, safer cities. By blending state-of-the-art solutions with thoughtful governance, the Ministry of Internal Affairs has created a system that not only addresses today’s challenges but also lays the groundwork for a secure and sustainable future.
For those interested in learning more about this transformative initiative, the full spotlight paper offers an in-depth exploration of the strategies and technologies behind its success.
{kind=link}
Build a server-side web app with .NET, C#, and HTMX 18 Dec 2024, 10:00 am
There are many stacks on the server side and one of the most longstanding and capable ones is the .NET platform using C#. .NET is broadly comparable to the Java platform, and over the years, the two have been competitors and mutual influencers. Each draws inspiration from the other. In this article, we’ll develop a simple server-side generated application using C#. We’ll throw in a dash of HTMX for dynamic front-end interactivity without the JavaScript.
Create a .NET C# project
To start, you’ll want the .NET CLI tool installed on your system, which is a fairly painless procedure. Once that’s done, you’ll have a dotnet command, which you can use to start a new application like so:
$ dotnet new mvc -n QuoteApp
This command creates a /QuoteApp directory. If we move into the new directory, we’ll see a simple project laid out for us. We can run it in dev mode like so:
/QuoteApp $ dotnet run
If you visit localhost:5265, you’ll see the starter screen like the one below:
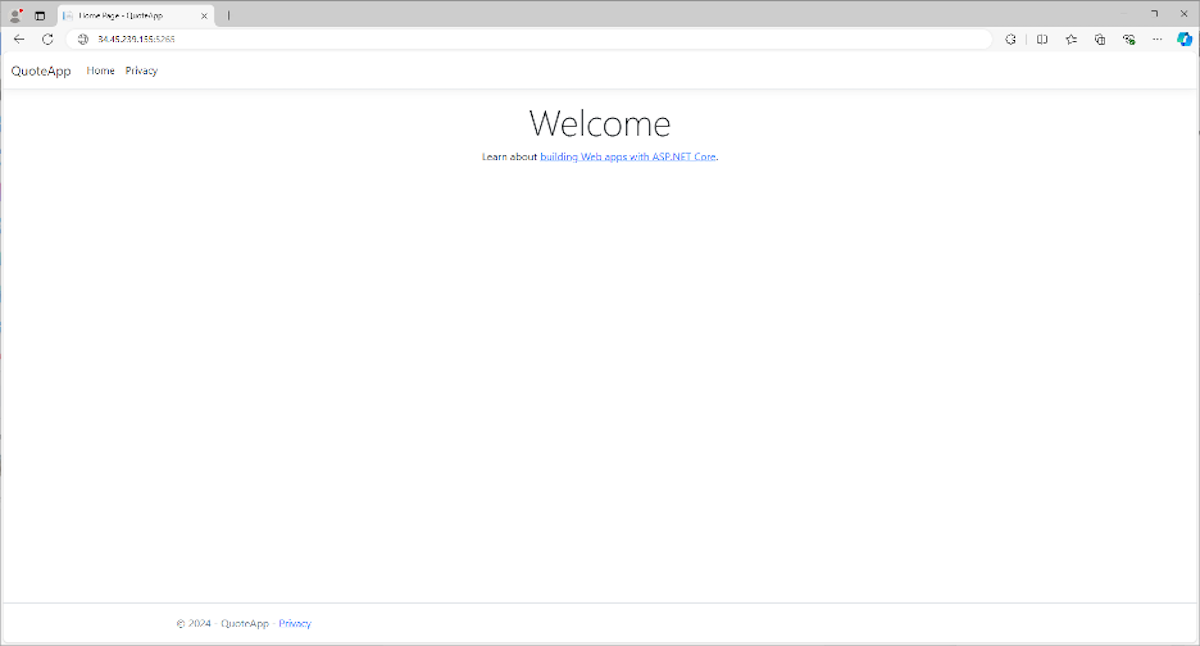
If you need to change the port or accept incoming requests from a domain other than localhost, you can modify the QuoteApp/Properties/launchSettings.json. As an example, in the http section, I modified the application to accept all incoming requests at port 3000:
"applicationUrl": "http://*:3000"
The model class
The layout of a typical .NET C# MVC application is similar to a Java Spring MVC application. Based on the Model View Controller design pattern, the first thing we want to do is add a model class. To start, create a new /Model directory (.NET conventionally capitalizes directory and file names) and then a QuoteItem.cs file:
// Models/Quote.cs
namespace QuoteApp.Models
{
public class Quote
{
public int Id { get; set; }
public string Text { get; set; }
public string Author { get; set; }
}
}
This yields a simple data class to hold the Id, Text, and Author fields for our sample application. Java developers will notice the use of get; and set; shorthand to create the corresponding getter and setter for each field.
.NET’s namespace concept is similar to Java’s package, although packages in Java have lowercase names by convention. In our case, the directory structure and namespace agree, although this is not strictly required in C#.
The repository class
We’ll use a repository class for persisting the quotes users submit to our application. In a real application, the repository class would interact with a datastore. For our example, we’ll just use an in-memory list. Since our application is small, we can put the repository class directly into our root directory for now.
Here’s the repository class:
// QuoteRepository.cs
using QuoteApp.Models;
namespace QuoteApp
{
public class QuoteRepository
{
private static List _quotes = new List()
{
new Quote { Id = 1, Text = "There is no try. Do or do not.", Author = "Yoda" },
new Quote { Id = 2, Text = "Strive not to be a success, but rather to be of value.", Author = "Albert Einstein" }
};
public List GetAll()
{
return _quotes;
}
public void Add(Quote quote)
{
// Simple ID generation (in real app, use database ID generation)
quote.Id = _quotes.Any() ? _quotes.Max(q => q.Id) + 1 : 1;
_quotes.Add(quote);
}
}
}
We’ll use a static block to declare and populate a _quotes List. Using that data, we provide two methods: GetAll() and Add(). GetAll() simply returns the List, while Add inserts the new Quote into it. We use a simple increment logic to create an ID for the new Quote.
The controller class
Now we can move on to the controller, which provides the application’s service layer:
// Controllers/QuoteController.cs
using Microsoft.AspNetCore.Mvc;
using QuoteApp.Models;
namespace QuoteApp.Controllers
{
public class QuoteController : Controller
{
private QuoteRepository _repository = new QuoteRepository();
public IActionResult Index()
{
var quotes = _repository.GetAll();
return View(quotes);
}
[HttpPost]
public IActionResult Add(string text, string author)
{
if (!string.IsNullOrEmpty(text) && !string.IsNullOrEmpty(author))
{
var newQuote = new Quote { Text = text, Author = author };
_repository.Add(newQuote);
//return Partial("_QuoteItem", newQuote);
return PartialView("_QuoteItem", newQuote);
}
return BadRequest();
}
}
}
The controller extends the abstract .NET MVC Controller class. It imports a couple of namespaces, one is from the .NET MVC library, and the other is our Quote model from the previous section. We then create a repository instance as a private member and define two public methods on it: Index() and Add().
Both methods return IActionResult. Index() takes the default GET HTTP method while Add() uses the [HttpPost] attribute to accept a POST. Attributes are similar to Java’s annotations and can decorate classes. In C#’s case, they also decorate namespaces.
The Index() and Add() methods use functions from the MVC framework to form responses: View, PartialView, and BadRequest. Notice that Add() returns a partial view; this is because we are going to use HTMX to submit the new quote request with Ajax, and we’ll take the markup for just the new Quote and insert it on the front end. You’ll see this in the next section.
The Index() method returns the view automatically associated with it, which is defined in the Views/Quote/Index.cshtml file. The view, which we’ll look at next, is provided with the list of quotes from the repository.
The view class
Our humble example only has two views, the index page and the quote. Here’s the index:
// Views/Quote/Index.cshtml
@model List
Quotes
@foreach (var quote in Model)
{
@await Html.PartialAsync("_QuoteItem", quote)
}
The .cshtml file is a view defined in the Razor format, which is a templating technology that lets you use code and data in an HTML file. This is similar to other templating solutions like JSP, Thymeleaf, or Pug. It’s plain HTML with a dash of HTMX except for the server-side bits where we do the following:
- Import the list of quotes provided by the controller, using
@model - Use the list to iterate:
@foreach (var quote in Model) - Render each quote in the list
Each quote is rendered with the line @await Html.PartialAsync("_QuoteItem", quote). PartialAsync means we are rendering a partial view (the quote template you’ll see shortly) using an asynchronous operation. Because it is async, we use the @await directive to wait for the operation to finish.
The _QuoteItem template is defined like so:
//Views/Quote/_QuoteItem.cshtml
@model QuoteApp.Models.Quote
@Model.Text - @Model.Author
This template takes the Quote from the Add() controller method as its model and uses it to render a simple list item.
The form
Back in Index.cshtml, the form uses HTMX attributes to submit the fields in the background with Ajax. We’ll do the following:
- Send a
POSTAjax request to.quote/add: hx-post="/quote/add" - Put the response into the
#quoteList element: hx-target="#quoteList" - Put the response before the end of the target:
hx-swap="beforeend"
The net result is that the markup sent back in the response from the Add() service (the element) will be inserted directly at the end of the quote list
Launch the main program
Program.cs is responsible for launching the program:
// QuoteApp/Program.cs
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddControllersWithViews();
var app = builder.Build();
// Configure the HTTP request pipeline.
if (!app.Environment.IsDevelopment())
{
app.UseExceptionHandler("/Home/Error");
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseRouting();
app.UseAuthorization();
app.MapControllerRoute(
name: "default",
pattern: "{controller=Home}/{action=Index}/{id?}");
app.MapControllerRoute(
name: "quote",
pattern: "quote/{action=Index}/{id?}",
defaults: new { controller = "Quote" });
app.Run();
This main file starts a new MVC application with the command-line arguments: WebApplication.CreateBuilder(args). The app generator adds a strict transport security layer if the developmentMode environment variable is not set. The site also redirects to https and serves static files by default.
The UseRouting call means we’ll partake of the MVC routing plugin, and the UseAuthorization does the same for the MVC authorization plugin.
Finally, we add the default Controller and our Quote controller. Notice the controller = “Quote” automatically maps to Controller/QuoteController.
Conclusion
Our new application is simple, but it gets the job done. It will list the quotes already submitted and allow us to add new ones dynamically when run with $ dotnet run, as shown here:
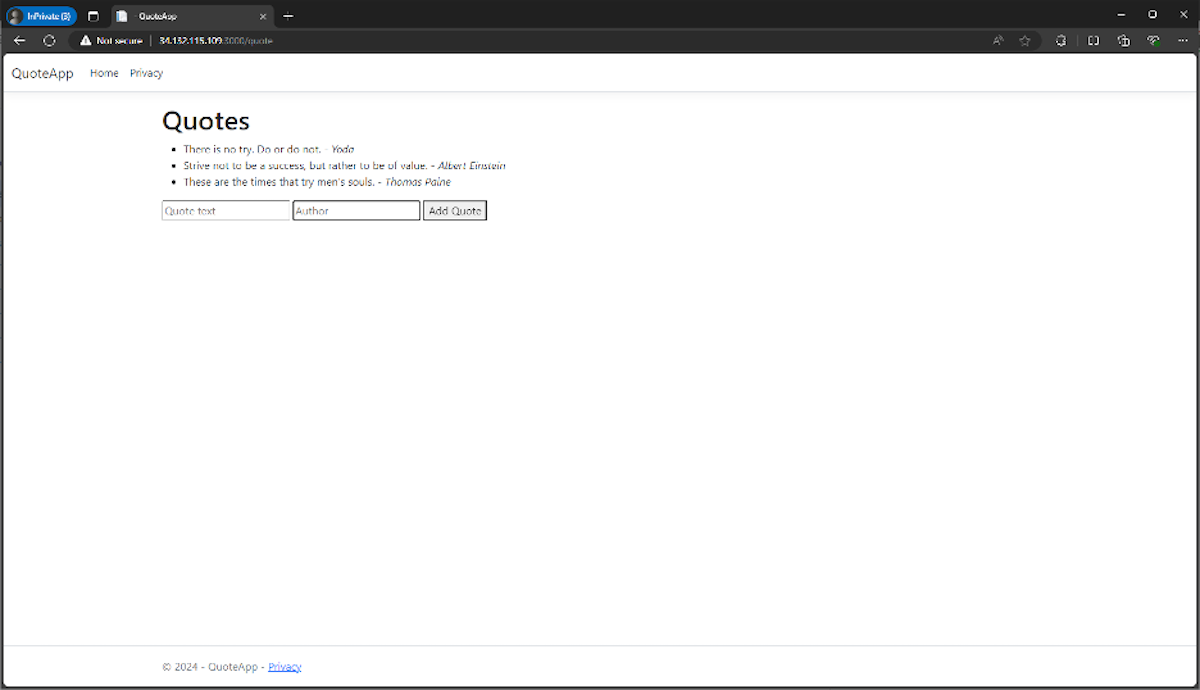
Overall, .Net with C# is a well-thought-out platform for building apps in the MVC style, and HTMX gives us low-overhead Ajax. Check out the csharp-htmx application repository to see all the code for the demo.
{kind=link}
4 key concepts for Rust beginners 18 Dec 2024, 10:00 am
Few languages are as highly esteemed by developers as Rust, which promises robust memory safety without compromising speed. Rust also has a steep learning curve, though, and some of its programming concepts can feel like a barrier to knowing it well.
As an aid to the aspiring Rustaceans, here are four key concepts of the Rustosphere—the kinds of things a more experienced Rust developer might wish they knew from the beginning. Having a grasp on these concepts will give you a head start when you start writing programs with Rust.
Also see: Rust tutorial: Get started with the Rust language.
All Rust variables are immutable by default
Rust’s first assumption about any variable you create is that it is immutable by default.
If you say let x=1;, the variable x is bound to the value 1 for the lifetime of the program. Any variable that might change has to be specifically declared as such with the mut (for “mutable”) keyword; e.g., let mut x=1;.
This “Sir, may I?” strategy is a deliberate design choice for Rust, even though at first it might seem ornery. But here’s the rationale: Immutable entities in a program are easier to reason about and make guarantees about—especially guarantees about memory safety, which is Rust’s big selling point. If the compiler knows some element in a given scope doesn’t change once it’s assigned, most of the memory management issues around that element evaporate.
Another rationale for this design decision is that it forces the programmer to think about what actually does need to change in a program. Taking input from the user, for instance, or reading from a file, are operations that must be handled mutably. But you can leave many other operations as immutable with no loss of functionality.
With advanced Rust data structures, such as reference-counted Cell objects, you can use immutability to your advantage. For example, this immutable singly-linked list has no mutable components; every change to the list essentially involves creating a new list, albeit one that doesn’t waste memory copying because the existing list data can be re-used.
Rust has strict rules of ownership
Rust’s memory management model relies on a strict concept of ownership. Any value in Rust can only be modified by one thing at a time—its owner. Think of how there’s only one baseball at a time in a baseball game, and only one player at a time handling it. That owner can change over the lifetime of a program, in the same way the ball is thrown between players. But Rust refuses to allow a value to have more than one owner at once, just as we’d rather not have baseball players tussling over the ball.
Also see: Rust memory safety explained.
It’s possible for something to be read by more than one thing at once in Rust, but not possible for something to be changed by more than one thing at once. There can be multiple shared references or “borrows” to something at once, for the sake of read-only access, but there can be only one exclusive (read-write) reference to something at once.
The net effect is that Rust programmers must pay close attention to what data can be modified at what time. It’s important to understand that a program that breaks these rules won’t just crash; in Rust, it won’t even compile. That’s because the rules of ownership are not optional. (More on this later.)
Another net effect is that Rust memory management at runtime is not handled by way of a dedicated garbage collection system, as with C# or Go. Things like dynamic reference counting are possible, but they’re more akin to C++’s smart pointers—albeit with better runtime controls for thread safety.
A final note is that ownership does not make it impossible for Rust programs to have data race conditions. Data access across threads, for instance, still needs to be serialized with primitives like locks or queues to avoid unpredictable in-program behavior. But Rust does make it impossible for code to have many common memory-access-error bugs that plague other languages.
Borrow checking enforces Rust’s ownership rules
A big part of Rust’s appeal is that its ownership rules forbid representing states that might cause common memory errors. These problems aren’t caught at runtime but at compile time, so they never enter production.
A downside is that Rust programmers spend a fair amount of time, at least when they’re first learning the language, figuring out how to appease the compiler. Program behaviors that might have passed unnoticed in other languages (and possibly caused memory errors at runtime) cause the Rust compiler to stop cold.
The other big downside is that you can’t opt out of this behavior. You can’t toggle off Rust’s borrow-checking behavior the way you could, say, disable a code linter for another language. It makes for better software in the long run. But the immediate cost is a language that’s both slower to learn and slower to iterate in.
Rust does allow you to fence off parts of your code with the unsafe keyword, and lift some restrictions, like the ability to dereference a raw pointer. But unsafe does not turn off borrow checking entirely, or anything like that. It’s for taking code with certain behaviors you don’t want casually used (again, like dereferencing a raw pointer) and “gating” it for safety.
Also see: Safety off: Programming in Rust with ‘unsafe’.
Rust editions support backward-compatibility
It’s been almost a decade since Rust 1.0 came out, and the language has evolved aggressively since then. Many new features came along, not all of them backward-compatible with older versions of the language. To keep these changes from making it hard to maintain code in the long term, Rust introduced the concept of language editions.
Editions, which are published roughly every three years, provide a guarantee of compatibility. By and large, features added to Rust are supported going forward. Breaking changes—ones that are backward-incompatible—are added to the next edition rather than the current one.
Once you choose an edition, you’re not tied to it forever. You can migrate your code to future editions by way of both automated tooling and manual inspection. But there’s also a good chance the changes you are interested in will be backward-compatible with your older code, and thus available without migrating editions.
{kind=link}
You have a license to code 18 Dec 2024, 10:00 am
One of the coolest things about software development is that you don’t need anyone’s permission to do it. If you need an application for your business or personal use, there isn’t a single thing stopping you from learning to code and writing it yourself. There’s no trade organization or governing body to seek approval from.
Now, if you want to practice law, or issue drug prescriptions, or even cut hair, you have to get permission from some government entity. But if you want to write the next viral application used by millions, you can just fire up your computer and start building. Nobody is going to stop you.
And more importantly, no one should stop you.
You don’t need a CS degree
Nor do you need to go to college to write code. For many professions, college and professional degrees are required. Sure, you could get a computer science degree, but I hold the somewhat contrary view that a CS degree isn’t nearly as valuable — or useful — as one might hope. It is an expensive way to learn something that you could teach yourself in a much shorter period of time. One can easily become a coding expert by watching YouTube videos, reading blogs, and looking at well-written code on GitHub.
In addition, a computer science degree normally doesn’t teach you many things you need to know to write code professionally. A CS student will learn about writing compilers and all kinds of grand theories about artificial intelligence, but probably not about the intricacies of Git and GitHub, or about how to write a good bug report. Standard algorithms and data structures are good to know, but the average developer doesn’t often write them. Few businesses will want you to spend time writing a doubly linked list when there is one ready to go in some standard library.
A much better solution these days would be a coding bootcamp. Cheaper, faster, and far more practical, bootcamps are the market response to what businesses need. They teach the actual skills that many (most?) software development shops are looking for today: JavaScript, TypeScript, React, HTML, CSS, Git, requirements gathering, and other “meta-programming” skills like bug reports and agile development.
This utter lack of control from higher authority comes from a simple fact: code is free and untameable. Not free like free beer, but free like the wind. You can’t stop someone from writing code. Any seven-year-old can build a game using Scratch or Python or Minecraft. Shoot, there are probably seven-year-olds writing better Python code than you or me. Your grandfather can break out Visual Studio Code and build a tool to track his stamp collection. I suppose that someone somewhere could try to regulate coding, but it seems like trying to bottle up chutzpah — it can’t be done.
This is true because no one can define the right way to build something in software, at least not in the same way we can define the right way to build a house or write a legally binding contract. I can’t imagine trying to impose a government-mandated set of rules for proper coding. It would be a disaster.
You don’t need a procedures manual
There is no “proper way” to code something, just like there is no proper way to paint a painting. Hand 100 teams the exact same design specification and you will get 100 wildly different implementations. Imagine telling Michelangelo, “No, I’m sorry, but that Sistine Chapel thing you did doesn’t conform to proper painting procedures and has to be redone under the supervision of our government inspector.” Yeah, right
I can’t imagine what trying to regulate software would do to innovation. Things move so fast in the software development world that no regulatory body could possibly keep up, and such an entity would almost certainly stifle any attempt to rapidly advance the industry. It seems obvious that the rapid rate of innovation comes as a result of the freedom software developers have to experiment with new ideas.
It’s never been a better time to be a smart, capable person. Eight hundred years ago, if you were ambitious, you had to get permission from a guild to do a long apprenticeship with a craftsman before you were allowed to strike out on your own.
Now? You can be up and running and learning and producing in a matter of hours. There’s nothing holding you back. While we all stand on the shoulders of giants, many of those giants started out creating things without any formal education. They just built the stuff that today enables us to be a coder if we want.
So go ahead — code like the wind.
{kind=link}
JetBrains launches search portal for Kotlin Multiplatform libraries 17 Dec 2024, 11:50 pm
JetBrains has introduced klibs.io, a web service intended to make it easier to find libraries for Kotlin Multiplatform, a project that allows developers to build cross-platform mobile, desktop, and web apps from the same code base.
Now in an alpha state and billed as an experimental search platform for KMP (Kotlin Multiplatform) libraries, klibs.io was introduced December 17. The service enables developers to locate a Kotlin Multiplatform library for a specific purpose that supports selected platforms including the JVM, the Android JVM, WebAssembly, JavaScript, and Kotlin/Native. The website indexes data from Maven Central and GitHub, using AI-generated metadata to enhance search results.
A goal of klibs.io is making it easier to evaluate libraries by offering KMP-related information. Libraries range from the Coil image-loading library for Android to Arrow typed functional programming interfaces to the Kodein dependency retrieval container and even PeopleInSpace, a Kotlin Multiplatform sample project that lists people currently in space. A search engine attached to klibs.io cites more than 1,400 libraries available. Developers will spend less time searching while library authors benefit from increased visibility for their work, JetBrains said. Instructions for adding a library to kilbs.io are available in an FAQ.
Developers can participate in Slack to improve klibs.io. They also can sign up for Kotlin Slack via an application form. The klibs.io website was created by Kotlin developer advocate Ignat Beresnev and the Kotlin web team. Plans call for adding Java/JVM-only libraries at some point. Also eyed for kilbs.io is indexing of Gradle plugins as well as GitLab and Bitbucket support.
{kind=link}
Gemini Code Assist tools target developer productivity from within IDEs 17 Dec 2024, 5:00 pm
Google has launched new Gemini Code Assist tools that are designed to help developers improve their productivity from within an integrated development environment (IDE), such as Visual Studio Code or JetBrains.
“These tools are all about developer productivity by enabling them to stay in their coding interface (IDE) of choice while accessing related information from other applications or tools,” said Kathy Lange, research director at IDC.
Expanding further, Moor Strategy and Insights principal analyst, Jason Andersen, said that the launch of these tools is in sync with the industry trend of evolution of IDEs in general.
“Google and others are starting to stretch the boundaries of what an IDE is and how much a developer can achieve within the tool,” Andersen explained, adding that rivals products, such as Amazon Q Developer, GitHub Copilot, and IBM Watsonx Code Assistant, either already have similar tools.
Lange pointed out that the addition of these tools may be a strategy to increase the stickiness of Code Assist.
“Every vendor wants developers to choose their platform for application development and create the AI ecosystem that keeps them there, making their platform sticky and driving more revenue. It also ends up attracting end-user customers to their platform,” Lange explained.
What exactly are these tools?
The Code Assist tools launched Tuesday are designed to help developers retrieve information from — or act on any part of their — engineering system, which is helpful for services outside their IDE, the company said.
“For instance, the tools could be used by developers to summarize recent comments from a Jira issue, find the last person who merged changes to a file in git, or show the most recent live site issue from Sentry,” Google explained in a blog post.
Partnerships or tools in the initial release include support for GitLab, GitHub, Google Docs, Sentry.io, Atlassian (Rovo), and Snyk.
These tools work via an API and are able to translate any natural language command into a parametrized API call as defined by the OpenAPI standard or YAML file the user provides.
Other use cases could include real-time access to data and insights from integrated partner tools so that developers can make informed decisions faster, in turn accelerating the development lifecycle.
Further, Google said that it is collaborating with partners, such as Dynatrace, New Relic, SonarQube, and Black Duck to improve observability and security in the software development lifecycle.
However, this is not the first that Google is relying on partners to expand Gemini Code Assist’s capabilities.
When Google renamed Duet AI for Developers to Gemini Code Assist back in April, it had added a host of partners, such as Synk, Elastic, Datadog, Datastax, HashiCorp, Neo4j, Pinecone, Redis, Singlestore, and StackOverflow, to provide the Gemini model with more data and knowledge from each of these companies to help generate more accurate code. Earlier this month, the cloud services provider updated the large language model by replacing Gemini 1.5 Pro and underpinning Code Assist with Gemini 2.0 Flash — a model that it claims provides better quality responses and lower latency.
{kind=link}
Top 5 use cases for small language models 17 Dec 2024, 10:00 am
Since ChatGPT arrived in late 2022, large language models (LLMs) have continued to raise the bar for what generative AI systems can accomplish. For example, GPT-3.5, which powered ChatGPT, had an accuracy of 85.5% on common sense reasoning data sets, while GPT-4 in 2023 achieved around 95% accuracy on the same data sets. While GPT-3.5 and GPT-4 primarily focused on text processing, GPT-4o — released in May of 2024 — is multi-modal, allowing it to handle text, images, audio and video.
Despite the impressive advancements by the GPT family of models and other open-source large language models, Gartner, in its hype cycle for artificial intelligence in 2024, notes that “generative AI has passed the peak of inflated expectations, although hype about it continues.” Some reasons for disillusionment include the high costs associated with the GPT family of models, privacy and security concerns regarding data, and issues with model transparency. Small language models with fewer parameters than these LLMs are one potential solution to these challenges.
Smaller language models are easier and less costly to train. Additionally, smaller models can be hosted on-premises, providing better control over the shared data with these language models. One challenge with smaller models is that they tend to be less accurate than their larger counterparts. To harness the strengths of smaller models while mitigating their weaknesses, enterprises are looking at domain-specific small models, which must be accurate only in the specialization and use cases they support. This domain specialization can be enabled by taking a pre-trained small language model and fine-tuning it with domain-specific data or using prompt engineering for additional performance gains.
Let’s look at the top five use cases where organizations consider leveraging small language models, and the leading small language models for each use case.
PII masking
One of the key concerns for organizations is the exposure of personally identifiable information (PII) from their data when used for training or asking questions to an LLM. An example of PII information is customer’s social security number (SSN) or credit card number. Hence, an extremely important use case is around building a solution that can mask PII data. In addition to masking, another key requirement is to maintain the lineage of the data. For example, the same SSN should be masked by the same identifier so that a downstream application can use the relationship in building effective applications. Phi-3 and Gliner perform very well in PII masking, but the best-performing model for this use case at the time of this writing is the Llama-3.1-8B model.
Toxicity detection
This use case identifies the presence of undesirable hateful comments in text. An example of toxic text is the use of swear words. As more companies adopt language models to automate customer service interactions, it is extremely important to ensure that no toxic content finds its way into the models’ responses. The RoBERTa model is well-suited for this task.
Coding assistance
Coding assistance was one of the first use cases for generative AI, and coding assistants have been widely adopted by developers across enterprises. Microsoft claims that 70% of GitHub Copilot users are more productive. Task-specific variants of Llama (Code Llama) and Gemma (CodeGemma) are excellent alternatives to large language models like GPT-4 for this use case.
Medical data summarization
Medical data summarization and understanding is a specialized use case in the healthcare industry, relying on models trained on the use of medical terms specific to the domain. Examples where the solution makes a high impact is in the summarization of conversations between patients and doctors and between doctors and medical sales representatives. Given the uniqueness of these types of conversations, small language models are well suited to the domain and can make a significant impact. The T5 model is a strong contender among the smaller language models for this task.
Vendor invoice processing
Lastly, vendor invoice processing is crucial for enterprise procurement departments dealing with invoices at scale. The ability to automatically scan these invoices for information extraction is a non-trivial task due to thousands of variations in invoice structures. Phi-3-vision is an excellent choice of model for the invoice processing pipeline.
While large language models are powerful and accurate, they are expensive, and data privacy and security remain significant concerns for enterprises. Small language models make it easier for enterprises to balance performance, cost, and security concerns and help reduce the time needed to get solutions into production. The five use cases we’ve discussed represent just some of the ways enterprises have successfully implemented small language models to address specific needs while mitigating the challenges associated with larger models.
Aravind Chandramouli is head of the AI center of excellence at Tredence.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
{kind=link}
Smarter devops: How to avoid deployment horrors 17 Dec 2024, 10:00 am
Many devops organizations implement advanced CI/CD, infrastructure as code, and other automations to increase deployment frequency. In the State of DevOps Report 2023, 18% of respondents were classified as elite performers for being able to deploy on-demand with change lead times of less than a day.
However, these elite performers also report a 5% change failure rate, which may be acceptable for applications that aren’t mission-critical or deployments triggered during low-usage periods. But when change failures occur within airline, banking, and other applications that require 5-nines availability (meaning they are 99.999% available), pushing defects and problematic configuration changes to production can lead to deployment horrors.
CrowdStrike recently made headlines with a failed deployment impacting 8.5 million Microsoft Windows computers, causing nearly 10,000 flight cancellations worldwide. Needless to say, the failure created a significant financial impact. CrowdStrike’s root cause analysis classified the issue as a bug, reporting, “The sensor expected 20 input fields, while the update provided 21 input fields. In this instance, the mismatch resulted in an out-of-bounds memory read, causing a system crash.”
It might be time for devops organizations to rethink their deployment strategies. When are frequent releases too risky, and how should teams evaluate the risks of a change to avoid large-scale deployment issues?
Evaluate requirements and implementation risks
Not all releases, features, and agile user stories come with equal deployment risks. Many organizations automate the creation of deployment risk scores and then use them to evaluate what level of testing and operational review is required before a release. Traditionally, risk scores leveraged subjective inputs and asked experts to evaluate each risk’s probability and impact, but organizations deploying frequently can move to a machine learning-driven approach.
“Avoiding deployment horrors starts in the planning phase,” says David Brooks, SVP of evangelism at Copado. “AI can help evaluate user stories to identify ambiguities, hidden dependencies and impacts, and overlapping work by other developers.”
Release management strategies characterized deployments as part of their internal communications and risk management frameworks. A traditional approach characterizes major upgrades, minor improvements, and system upgrades. Devops leaders then specify deployment policies, risk mediation requirements, and automation rules based on release types.
A more data-driven approach will characterize releases and compute risk scores by many other variables, such as the number of users impacted, test coverage of the impacted code, and measures of dependency complexities. Organizations can then implement feedback loops to calibrate risk scores based on releases’ actual business impacts by capturing outages, performance issues, security incidents, and end-user feedback.
Embed security into the developer experience
Finding security issues post-deployment is a major risk, and many devops teams shift-left security practices by instituting devops security non-negotiables. These are a mix of policies, controls, automations, and tools, but most importantly, ensuring security is a top-of-mind responsibility for developers.
“Integrating security and quality controls as early as possible in the software development lifecycle is absolutely necessary for a functioning modern devops practice,” says Christopher Hendrich, associate CTO of SADA. “Creating a developer platform with automation, AI-powered services, and clear feedback on why something is deemed insecure and how to fix it helps the developer to focus on developing while simultaneously strengthening the security mindset.”
Devops teams should consider the following practices to minimize the risk of deployment disasters:
- Institute a software developer’s security standard based on guidelines from the OWASP Security Fundamentals, the NIST Secure Software Development Framework (SSDF), ISO 27034, and other security frameworks and control standards.
- Establish risk management in agile development by reducing technical debt and completing complex stories early in the sprint and release cycles.
- Address security risks in software development, including poor governance of open source software and inadequate data security on sensitive data.
- Implement security testing in CI/CD, including static application security testing (SAST), dependency tracking, and penetration testing.
Implement continuous deployment prerequisites
Development teams champion the objective of automating a path to production, but not all devops teams are truly ready for continuous deployment. What starts as an easy objective of implementing CI/CD in production environments can lead to deployment horrors if the right safeguards aren’t in place, especially as application and microservices architecture complexities grow.
“Software development is a complex process that gets increasingly challenging as the software’s functionality changes or ages over time,” says Melissa McKay, head of developer relations at JFrog. Implementing a multilayered, end-to-end approach has become essential to ensure security and quality are prioritized from initial package curation and coding to runtime monitoring.”
Devops teams looking to implement continuous delivery on mission-critical, large-scale applications should institute the following best practices:
- Continuous testing with high test coverage, comprehensive testing data, and end-user persona-driven testing, including using synthetic data and genAI testing capabilities to minimize defects in production code.
- Feature flagging so that development teams can control experimental capabilities configured and tested with a targeted set of end users.
- Canary release strategies to support the deployment of multiple versions of an application or service, control which versions end-users access, and capture issues deployed to this smaller end-user base.
“Implementing software checks at every stage enhances code quality and resiliency while utilizing strategies such as canary testing helps guarantee stable deployments,” adds McKay of JFrog.
Some organizations only have a few large-scale mission-critical applications that require continuous delivery and all its prerequisites. Large enterprises with a significant portfolio of mission-critical applications, data science teams managing AI models in the hundreds, or SaaS companies with several product lines should consider platform engineering practices to drive standards and efficiencies.
Kevin Cochrane, CMO of Vultr, says, “Platform engineering for cloud-native and AI-native applications enhances devops and lowers enterprises’ risk by automating key processes supporting mature and responsible AI, including infrastructure provisioning, model observability, and data governance.”
Continuously improve observability, monitoring, and AIOps
What separates bad deployments from deployment horror stories can be discovered by answering three key questions:
- What is the business impact, including the number of end users affected, the lost productivity in operations, the financial costs, reputation damage, compliance factors, and legal implications?
- How long does it take for the organization to identify the issue, communicate the problem to end users, recover from the incident, identify root causes, and implement remediations?
- How often is the devops team responding to bad deployments, and are the engineers burned out from all the firefighting?
Investments in observability, application monitoring, and AIOps are key operational capabilities that can reduce the business impact and improve the mean time to recovery (MTTR) from major incidents.
“All of today’s devops deployment ‘horrors’—from end-user errors to potential miscommunications—ultimately boil down to a lack of proper communication or visibility,” says Madhu Kochar, VP of product development of IBM Automation. “You can’t fix what you can’t see, and that’s exactly why observability, especially within the context of intelligent automation, is critical for addressing known flaws and providing insight into what’s happening inside your system or application. Observability allows the devops feedback loop to flow without interruption for efficient, better-performing deployment efforts that catch issues before they affect end users.”
Observability, automation, and monitoring are key defensive strategies to alert network operation centers (NOCs) and site reliability engineers (SREs) about major incidents. Organizations applying microservices architectures, deploying to multiple clouds, and connecting to many third-party systems need AIOps solutions to identify incident root causes and trigger automated responses such as deployment rollbacks.
“As the digital landscape rapidly evolves, traditional monitoring tools are no longer sufficient to meet the demands of modern devops,” says Jamesraj Paul Jasper, principal product manager at ManageEngine. “Teams must adopt a system of intelligence, including AI-driven observability and predictive solutions, to stay ahead of potential issues.”
Develop a major incident playbook
When a bad deployment causes a major incident, IT organizations must have an operational playbook to guide their response. Is there an optimally sized and skilled response team that knows what communication tools they’ll use and what application monitors to review? Does the team have a leader to coordinate actions, and are stakeholders, executives, and customers alerted about the issue and well-informed about its status?
During a major incident, the worst-case scenario is to watch everyone from engineers to executives run around like chickens with their heads cut off and without clear directions and communication. It creates delays, missteps, and greater stress. Most organizations develop an IT service management (ITSM) major incident playbook and process to prepare for all types of business-impacting production issues.
Devops teams are compelled to increase the frequency of deployments and deliver new capabilities to application end users. Every deployment carries risks, and bad deployments will require investigating root cause analyses and implementing remediations. However, the smarter devops organizations balance speed with preparedness to avoid deployment horrors.
{kind=link}
Does AWS have a complexity problem? 17 Dec 2024, 10:00 am
At AWS re:Invent 2024, Amazon Web Services addressed a critical concern for enterprises using modern cloud technology: managing the growing complexity of cloud environments at scale. Enterprises are confronted by the challenges of evolving systems, managing large-scale architectures, and optimizing operations. Cloud complexity is now a key obstacle to innovation and efficiency.
As defined by AWS, the complexity problem lies in the operational chaos often created by interconnected systems, unpredictable workloads, and the sheer scale of cloud deployments. To tackle this challenge, AWS CTO Werner Vogels introduced the concept of “simplexity” (cute name), a six-step framework aimed at breaking down and managing cloud complexity. Vogels hopes simplexity will ensure systems stay scalable and adaptable.
Here is Vogels’ six-step approach to simplexity:
- Make flexibility a requirement: Design systems from the outset to adapt and evolve as technologies, workloads, and requirements change over time.
- Break complexity into pieces: Dividing large, complex systems into smaller, more manageable, and loosely coupled components will make them easier to understand, maintain, and scale.
- Align organization to architecture: Organizational structures should mirror system architectures. This will encourage ownership and responsibility and empower teams to solve problems independently.
- Use a cell-based architecture design: Cells are isolated, self-contained units that manage workloads. They are small enough to test but large enough to handle the necessary scale. Cells help contain failures and isolate problems.
- Design predictable systems: This helps reduce the impact of uncertainty and ensure consistency in operations and performance.
- Automate everything that doesn’t require high degrees of judgment: The goal is to minimize human intervention in routine or error-prone tasks while focusing human efforts on decision-making and innovation.
Simplexity is about hiding complexity behind intelligent design and automation while delivering simplicity and reliability to the user. Where have you heard that idea before? From me, for one.
For the past five years, I’ve focused on the rising issue of cloud complexity. As a result, I received some grief from the large cloud providers and consulting organizations. Typically, they complained about the term complexity because it portrays cloud computing in a negative light. I don’t believe that ignoring a problem makes it go away, but many of my peers in the cloud computing space seem to take that approach.
Although most of my focus is on managing cloud complexity in multicloud deployments, Vogels focuses on the complexity within a single cloud domain: an AWS cloud. The solution patterns are the same: automation, abstraction, decomposition, architecture, artificial intelligence, finding common layers, etc. Indeed, if you compare my course to what Vogels says about “simplexity,” you’ll find many similarities.
Is ‘simplexity’ the right approach?
Vogels’ approach is an architecture-forward method that does not insist on throwing more technologies at the problem. I like that. We should be normalizing the technologies in use and, in some cases, looking for third-party solutions such as common directory services, database virtualization, etc.
The obvious elephant in the room is that most enterprise cloud deployments are heterogeneous, meaning they use multiple cloud providers. Vogels’ vision does not include multiple provider deployments, which is unsurprising. Are you solving the problems that most enterprises face if you do not consider multicloud deployments? A single cloud deployment is not the norm, complex or not.
The principles of the AWS approach are helpful, but they do not tailor solutions to the specific demands of multicloud. Multicloud environments require organizations to integrate and manage diverse platforms, APIs, tools, and security models from different providers, adding layers of operational complexity. Multicloud deployments come with unique challenges such as ensuring data portability between clouds, maintaining unified compliance frameworks, and optimizing workloads distributed across providers.
Although AWS offers features that may help extend some control over multicloud setups, its primary focus remains on optimizing cloud-native services and ecosystems rather than providing a unified solution for managing workloads across multiple cloud providers. I’m not picking on AWS—none of the cloud providers address operational complexity around multicloud deployments. Obviously, they would rather you use only their clouds.
AWS and other cloud providers have made some strides in addressing multicloud issues, but they are mostly silent about providing actual solutions. Enterprises seeking comprehensive multicloud strategies must look to broader tools, processes, and governance models capable of handling the intricacies of managing multiple cloud platforms. There is a significant gap in the AWS framework’s ability to address the realities of modern enterprise cloud strategies.
AWS could be more helpful
AWS designed its framework (at least, as explained thus far) to manage complexity within the AWS ecosystem. It falls short for most enterprises because modern enterprises increasingly operate across multiple cloud providers, private cloud, and on-premises systems. These multicloud setups arise from the need for redundancy, cost optimization, regulatory compliance, or access to specialized services beyond what any single provider offers.
The principles of AWS frameworks—decomposing services, aligning teams to architecture, and automating processes—are valuable but inherently ignore the operational realities of integrating multiple cloud ecosystems.
Enterprises in multicloud environments face unique challenges, such as managing interoperability, unifying security frameworks, ensuring data portability, and maintaining governance across fragmented systems. Additionally, multicloud operations require vendor-neutral management, centralized governance, and a unified compliance framework.
Approaches such as simplexity neglect the distributed, heterogeneous nature of multicloud setups by focusing solely on cloud-native optimization. Most enterprises today require broader strategies and tools that go beyond the scope of a single cloud provider. I look forward to another iteration of simplexity and more clarity from AWS in how their customers should deal with multicloud deployments. That solution would be much more helpful.
{kind=link}
JavaScript is still number one – JetBrains report 17 Dec 2024, 3:42 am
JavaScript is the most-used programming language, according to JetBrains’ State of Developer Ecosystem Report 2024. But the languages with the most promising growth prospects are TypeScript, Rust, and Python, the report says.
This year’s report found that JavaScript, with 61% of developers worldwide using it to create web pages, remains the most popular programming language in the world. Python was the second most used programming language, the report found, with 57% of developers, followed by HTML/CSS with 51%, SQL with 48%, Java with 46%, and TypeScript with 37%. Among these languages, however, usage increased only for Python and TypeScript (by 3% in both cases) from the previous year. Usage of C#, Go, and Rust also increased, the report found, all by 1% from the prior year.
Released December 11, the eighth edition of JetBrains’ annual State of the Developer Ecosystem Report is based on responses from 23,262 developers worldwide, surveyed between May and June 2024.
To better assess the growth prospects of programming languages, JetBrains’ 2024 report introduces the JetBrains Language Promise Index, which is based on the growth in usage of the language over the past five years, the stability of this growth, the share of developers intending to adopt the language, and the share of the language’s current users who want to adopt another language.
Based on this formula, the “undisputed leaders” of the JetBrains Language Promise Index are TypeScript, Rust, and Python, JetBrains reported. TypeScript usage has surged from 12% in 2017 to 35% in 2024, while Python usage has grown from 32% in 2017 to 57% in 2024 and Rust usage has grown from 2% in 2018 to 11% in 2024. Java usage, meanwhile, has slipped from 47% in 2017 to 46% in 2024, although it had surged to 54% in 2020.
Despite its gains, TypeScript will not replace JavaScript, according to the report. JavaScript remains one of the most popular and fundamental technologies in the software development industry. Still, TypeScript offers benefits over JavaScript including early error detection during development, improved code quality, compile-time error catching, more reliable refactoring, and native support for ECMAScript 2015 (ES^) modules.
Other findings in the State of Developer Ecosystem Report 2024:
- Go and Rust are the languages most respondents plan to adopt.
- Aspiring to replace C++ with strict safety and memory ownership mechanisms, Rust has seen its user base rise steadily over the past five years.
- ChatGPT is the most-tried AI coding tool, with 69% of developers having tried it, followed by GitHub Copilot at 40%.
- The US has the highest median salary for developers at $144,000.
- Most developers (38%) said understanding user requirements was the most challenging part of the job, followed by communication with other job roles (34%) and understanding other people’s code (32%).
- Open source databases – MySQL, PostgreSQL, MongoDB, SQLite, and Redis – dominate the storage options used by developers in the JetBrains ecosystem.
- Amazon Web Services is by far the most commonly used cloud platform, with 46% of respondents using it, followed by Microsoft Azure at 17%.
{kind=link}
Aerospike Vector Search adds self-healing live indexes 16 Dec 2024, 10:51 pm
Real-time database provider Aerospike has updated its Aerospike Vector Search database extension for powering generative AI applications. The update offers new indexing and storage capabilities for real-time accuracy, scalability, and ease of use for developers, Aerospike said.
The improvements are intended to simplify deployment, reduce operational overhead, and enable enterprise-ready solutions for generative AI and machine learning decisions, the company added. Aerospike Vector Search is a service that lives outside of Aerospike and enables searches across very large data sets stored in Aerospike.
Improvements to Aerospike Vector Search were announced December 11. The technology can be tried out at aerospike.com.
The latest release of Aerospike Vector Search features a self-healing hierarchical navigable small world (HNSW) index, an approach that enables scale-out data ingestion by allowing data to be ingested while asynchronously building the index across devices. By scaling ingestion and index growth independently from query processing, the system ensures uninterrupted performance, accurate results, and optimal query speed for real-time decision-making, Aerospike said.
The new release also introduces a new Python client and sample apps for common vector use cases to speed deployment. The Aerospike data model allows developers to add vectors to existing records, eliminating the need for separate search systems, while Aerospike Vector Search makes it easy to integrate semantic search into existing AI applications through integration with popular frameworks and popular cloud partners, Aerospike said. Aerospike’s LangChain extension helps speed the development of RAG (retrieval-augmented generation) applications.
Aerospike’s multi-model database engine includes document, key-value, graph, and vector search within one system. Aerospike graph and vector databases work independently and jointly to support AI use cases such as RAG, semantic search recommendations, fraud prevention, and ad targeting, Aerospike said. The Aerospike database is available on major public clouds.
{kind=link}
Page processed in 0.204 seconds.
Powered by SimplePie 1.3.1, Build 20121030095402. Run the SimplePie Compatibility Test. SimplePie is © 2004–2024, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.