Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Mistral turns focus toward regional LLMs with Saba release | InfoWorld
Technology insight for the enterpriseMistral turns focus toward regional LLMs with Saba release 18 Feb 2025, 11:07 am
French AI startup Mistral is turning its focus toward providing large language models (LLMs) that understand regional languages and their parlance as a result of rising demand among its enterprise customers.
“Making AI ubiquitous requires addressing every culture and language. As AI proliferates globally, many of our customers worldwide have expressed a strong desire for models that are not just fluent but native to regional parlance,” the company wrote in a blog post.
Explaining further, it said that while larger LLMs are more general purpose and often proficient in several languages, they often fail to understand the usage of words in a certain language or lack understanding of the cultural background, which leads to failure of servicing use cases in local languages.
Some examples of these use cases could be conversational support, domain-specific expertise, and cultural content creation.
Mistral believes that LLMs that are custom-trained in regional languages can help service these use cases as the custom training would help an LLM “grasp the unique intricacies and insights for delivering precision and authenticity.”
Mistral’s first custom-trained regional language LLM
Mistral has released its first custom-trained regional language-focused model named Saba, which is a 24-billion parameter model. According to Mistral, the LLM has been trained on “meticulously curated datasets” from across the Middle East and South Asia.
This means that Saba can support use cases in Arabic and many Indian-origin languages, particularly South Indian-origin languages, such as Tamil the company said, adding that Saba’s support for multiple languages could increase its adoption.
Mistral claims that Saba is similar to its Mistral Small 3 model in size and this means that it is relatively cheaper to use than most LLMs.
Saba is lightweight and can be deployed on single-GPU systems, making it “more adaptable” for a variety of use cases, the company said, adding that the LLM can serve as a strong base to train highly specific regional adaptations.
The LLM’s deployment options include an API and local deployment on-premises. Mistral said the local deployment option could help more regulated industries, such as finance, banking, and healthcare, adopt the model.
In benchmark tests, such as Arabic MMLU, Arabic TyDiQAGoldP, Arabic Alghafa, and Arabic Hellaswag, Saba outperforms Mistral Small 3, Qwen 2.5 32B, Llama 3.1 70B, and G42’s Jais 70B.
Saba also outperforms LLama 3.3 70B Instruct, Cohere Command-r-08-2024 32B, Jais 70B Chat, and GPT-4o-mini in benchmarking tests, such as Arabic MMLU Instruct, Arabic MT-Bench Dev, and Arabic-Centric FLORES-101.
Why is Mistral turning its focus toward regional language LLMs?
Mistral’s focus on releasing regional language LLMs could help the company expand its overall revenue, analysts say.
“There’s a growing market for regional LLMs like Saba, especially for enterprises needing culturally and linguistically tailored solutions. The market could be significant, driven by demand for localized AI in sectors like finance, healthcare, and government, potentially reaching billions as businesses seek to enhance customer engagement and operational efficiency,” said Charlie Dai, principal analyst at Forrester.
“LLMs finetuned towards regional markets address specific linguistic, cultural, and regulatory needs, making AI solutions more relevant and effective for local enterprises. This differentiation can drive adoption and unlock revenue growth in underserved markets,” Dai explained.
In addition to regional language LLMs, Mistral said it has started training models for strategic customers who can provide deep and proprietary enterprise context.
“These (custom) models stay exclusive and private to the respective customers,” the company wrote in the blog post.
However, analysts warned that Mistral is not the only model provider trying to use the regional language model playbook for expansion.
BAAI from China open-sourced their Arabic Language Model (ALM) back in 2022. This was followed by DAMO of Alibaba Cloud open-sourcing its PolyLM in 2023 covering eleven languages including Arabic, Spanish, German, and others.
“We have been observing that language-specific LLMs have been growing in the Middle East. We saw some regional LLM launches by start-ups such as G42, which launched one of the first Arabic LLMs,” said Suseel Menon, practice director at Everest Group.
Alongside pointing out that regional public sector organizations in the Middle East have been attempting to create Arabic LLMs, such as the Saudi Data and AI Authority (SDAIA) that launched its LLM named ALLaM on IBM Cloud last year, Menon said that Saba’s presence is likely to drive more competition among model providers in the region.
Mistral also faces competition in South Asia, specifically in India where several startups have used Llama 2 to create regional language models, such as OpenHathi-Hi-v0.1 for Hindi, Tamil Llama, Telegu Llama, odia_llama2_7B_v1, and VinaLLaMA for Vietnamese.
But Dai believes that the announcement of the models is just the first step. “Model providers who offer high-quality, localized solutions will only gain loyalty and market share in underserved areas,” Dai explained, adding that regional business operations around the models are another key to success.
{kind=link}
3 reasons to consider a data security posture management platform 18 Feb 2025, 10:00 am
A week rarely goes by without a major data security breach. Recent news includes a breach impacting an energy company’s 8 million customers, another compromising the information on 450,000 current and former students, and one more exposing 240,000 credit union members. Fines for data security breaches can be steep; for example, the Irish Data Protection Commission recently fined Meta, Facebook’s parent company, $263.5 million for a 2018 breach impacting 29 million Facebook users.
Recent research indicates the challenges in data security, with 60% of organizations reporting that at least a fifth of their data stores contain personally identifiable information (PII) or other sensitive data. Protecting this data is complex for larger organizations, with 39% of sensitive data stored in data centers, 27% on public clouds, 18% in SaaS, and 14% in edge infrastructure, while 58% of organizations report over 20% annual growth in their data.
There are many best practices and solutions to help organizations address data security risks, and the 2024 Gartner hype cycle for data security identifies over 30 to consider. One of the newer entrants is data security posture management or DSPM, a term Gartner introduced in 2022 as a proactive approach to monitor and manage data security continuously.
What is data security posture management?
DSPM aims to bring several data security practices into one management framework. Tools often include data discovery capabilities that integrate with data across clouds and classification capabilities that categorize data based on sensitivity and compliance requirements. As data is classified, DSPM platforms aid in crafting access controls, performing risk assessments, monitoring sensitive data usage, and capturing data movements. For risk and security leaders, platforms provide visibility, controls, and policy enforcement to different regulatory requirements, such as GDPR, HIPAA, California Consumer Privacy Act (CCP), or PCI data security standard (PCI-DSS).
“Data environments are only getting more complex, and regulations aren’t getting any easier to comply with,” says Amer Deeba, GVP of Proofpoint DSPM Group. “Real-time knowledge of what data you have, where it is, and how it’s being accessed is no longer optional—it’s required to report data breaches from the outset accurately. DSPM is the map that pinpoints the location of all the data that regulations care about, then overlays it with applicable rules so you can see exactly where things are out of line—whether it’s how the data is stored, accessed, or handled.”
DSPM solutions are already a big market, estimated at $94 billion in 2023 and projected to grow to $174 billion by 2031. These solutions aim to be horizontal data security platforms that discover, assess, and manage sensitive data wherever it’s stored, moved, or accessed.
Top DSPM solutions include Concentric AI, Cyera, Microsoft Purview, Securiti, Sentra, Spirion, Symmetry Systems, Theom, Varonis, and Wiz. DSPM solutions are a hot space for mergers and acquisitions—events such as Crowdstrike buying Flow Security, Formstack buying Open Raven, IBM buying Polar Security, Proofpoint buying Normalyze, Palo Alto Networks buying Dig Security, Rubrik buying Laminar, and Tenable acquiring Eureka Security.
What’s driving IT, security, and data leaders’ rising interest in DSPM platforms? Here are three big factors.
DSPM extends data compliance to dark data
“DSPM is an independent security layer, agnostic to infrastructure, that protects sensitive data and ensures consistent controls no matter where data travels,” says Yoav Regev, co-founder and CEO of Sentra. “It assesses exposure risks, identifies who has access to company data, classifies how data is used, ensures compliance with regulatory requirements like GDPR, PCI-DSS, and HIPAA, and continuously monitors data for emerging threats.”
Virtually all businesses must consider data compliance as part of their proactive data governance initiatives, which focus on business benefits and risks when establishing data-driven organizations. Data discovery used to be tedious, requiring organizations to use multiple tools to scan different data sources. Newer innovations such as machine learning prediction models, integration to multiple clouds and SaaS, and automation baked into DSPM platforms greatly reduce the complexity and improve the ability to find complex patterns and other data anomalies.
“DSPM uses machine learning and other technologies to discover, classify, and monitor an organization’s most sensitive data, then details where it lives, who has access, and how it’s used,” says Akiba Saeedi, VP of product management at IBM Security. “These insights enable organizations to shield exposed data, revoke unauthorized access, secure vulnerabilities, and remain compliant. The upshot is mitigating disastrous data breaches, costly non-compliance fines, and data leakage by LLMs.”
One of the issues facing organizations was dark data, which is data stored by organizations but not analyzed for intelligence, used in decision-making, or scanned for security and compliance risks. DSPM platforms can find this data, identify data security risks, and enable remediations.
“With DSPM, teams can set up smarter data loss prevention rules, keep insider threats in check, or clean up shadow data that shouldn’t exist in the first place. It’s about turning blind spots into a clear view of your data landscape,” adds Amer Deeba of Proofpoint DSPM Group.
DSPM safeguards data in complex and hybrid infrastructures
Point solutions that address one aspect of data security or optimize for one type of infrastructure are no longer adequate to meet the complexity of systems that store, process, and access data across multiple clouds and platforms. Furthermore, regulations require organizations to consider SaaS, which often stores sensitive information types beyond just customer data. Locking down data in selected platforms can be inefficient and complicates proving to regulators that all sensitive data meets policies regardless of where it’s stored and utilized.
“DSPM is a comprehensive approach to safeguarding sensitive data across hybrid multi-cloud, SaaS, and on-premises environments,” says Nikhil Girdhar, senior director for data security at Securiti. DSPM involves discovering all your data assets, including shadow data, classifying sensitive information, remediating risks like misconfigurations, and enforcing access controls to prevent unauthorized access. DSPM helps organizations ensure compliance with data protection laws and maintain a strong security posture by continuously monitoring and assessing data security risks.”
A platform approach to data security also ensures that data is scanned and classified consistently, even when there are multiple platforms and different types of sensitive data.
“DSPM discovers where data is residing, particularly across organizations’ many cloud apps and systems, and analyzes whether it contains sensitive customer or employee information like health records, credit card numbers, ID numbers, or if files are secret internal documents,” says Jim Fulton, VP product marketing of Forcepoint. “This helps security leaders to proactively manage their data security policies within diverse cloud and on-premises environments, streamline compliance efforts, and ultimately foster innovation in a data-driven world.”
DSPM protects data exposed to AI models
Data needs protection whether it is being stored in databases, data lakes, and file systems; in transit through data pipelines and APIs; or being incorporated and used in AI models.
“The rise of AI is fragmenting data and expanding organizational attack surfaces faster than ever, so companies must now monitor not just systems, web assets, and APIs, but also AI models and the systems those models power,” says Rob Gurzeev, CEO and co-founder of CyCognito. “By leveraging advanced monitoring and contextual analysis, organizations can uncover where vulnerabilities intersect, such as compromised credentials tied to assets with known critical exploits. This reduces false positives and dramatically improves meantime to remediation, enabling faster and more precise incident response.”
Data security platforms once focused on structured data in SQL databases and file systems, while document management solutions provided security on documents and unstructured data. Organizations looking for a holistic approach to data security rely on DSPMs to handle both structured and unstructured data sources, while some platforms, such as Concentric, extend to video and other multimedia formats.
“Having control over your data—knowing where it is, what’s in it, who has access to it, and how it’s protected—has always been important. And now, in this new age of AI, control and visibility can no longer be ignored,” says Amit Shaked, GM & VP of DSPM strategy, growth and monetization at Rubrik. “AI can make data available instantly to anyone with the right access, which is why right-sizing permissions is critical—not only for employees who shouldn’t be able to access sensitive files but also in case of a compromised identity.”
As more organizations seek faster and more scalable business value from AI, they can’t let data security become a lagging risk-management practice. DSPM platforms provide a centralized and consistent approach to discovering, classifying, and managing sensitive information.
{kind=link}
Key strategies for MLops success in 2025 18 Feb 2025, 10:00 am
Integrating and managing artificial intelligence and machine learning effectively within business operations has become a top priority for businesses looking to stay competitive in an ever evolving landscape. However, for many organizations, harnessing the power of AI/ML in a meaningful way is still an unfulfilled dream. Hence, I thought it would be helpful to survey some of the latest MLops trends and offer some actionable takeaways for conquering common ML engineering challenges.
As you might expect, generative AI models differ significantly from traditional machine learning models in their development, deployment, and operations requirements. I’ll walk through these differences, which range from training and the delivery pipeline to monitoring, scaling, and measuring model success, and leave you with a few key questions organizations should address to guide their AI/ML strategy.
Ultimately, by focusing on solutions, not just models, and by aligning MLops with IT and devops systems, organizations can unlock the full potential of their AI initiatives and drive measurable business impacts.
The foundations of MLops
Like many things in life, in order to successfully integrate and manage AI and ML into business operations, organizations first need to have a clear understanding of the foundations. The first fundamental of MLops today is understanding the differences between generative AI models and traditional ML models.
Generative AI models differ significantly from traditional ML models in terms of data requirements, pipeline complexity, and cost. GenAI models can handle unstructured data like text and images, often requiring really complicated pipelines to process prompts, manage conversation history, and integrate private data sources. In contrast, traditional models focus on specific data and are generally optimized for specific challenges, making them simpler and more cost-effective.
Cost is another major differentiator. The calculations of generative AI models are more complex resulting in higher latency, demand for more computer power, and higher operational expenses. Traditional models, on the other hand, often utilize pre-trained architectures or lightweight training processes, making them more affordable for many organizations. When determining whether to utilize a generative AI model versus a standard model, organizations must evaluate these criteria and how they apply to their individual use cases.
Model optimization and monitoring techniques
Optimizing models for specific use cases is crucial. For traditional ML, fine-tuning pre-trained models or training from scratch are common strategies. GenAI introduces additional options, such as retrieval-augmented generation (RAG), which allows the use of private data to provide context and ultimately improve model outputs. Choosing between general-purpose and task-specific models also plays a critical role. Do you really need a general-purpose model or can you use a smaller model that is trained for your specific use case? General-purpose models are versatile but often less efficient than smaller, specialized models built for specific tasks.
Model monitoring also requires distinctly different approaches for generative AI and traditional models. Traditional models rely on well-defined metrics like accuracy, precision, and an F1 score, which are straightforward to evaluate. In contrast, generative AI models often involve metrics that are a bit more subjective, such as user engagement or relevance. Good metrics for genAI models are still lacking and it really comes down to the individual use case. Assessing a model is very complicated and can sometimes require additional support from business metrics to understand if the model is acting according to plan. In any scenario, businesses must design architectures that can be measured to make sure they deliver the desired output.
Advancements in ML engineering
Traditional machine learning has long relied on open source solutions, from open source architectures like LSTM (long short-term memory) and YOLO (you only look once), to open source libraries like XGBoost and Scikit-learn. These solutions have become the standards for most challenges thanks to being accessible and versatile. For genAI, however, commercial solutions like OpenAI’s GPT models and Google’s Gemini currently dominate due to high costs and intricate training complexities. Building these models from scratch means massive data requirements, intricate training, and significant costs.
Despite the popularity of commercial generative AI models, open-source alternatives are gaining traction. Models like Llama and Stable Diffusion are closing the performance gap, offering cost-effective solutions for organizations willing to fine-tune or train them using their specific data. However, open-source models can present licensing restrictions and integration challenges to ensuring ongoing compliance and efficiency.
Efficient scaling of ML systems
As more and more companies decide to invest in AI, there are best practices for data management and classification and architectural approaches that should be considered for scaling ML systems and ensuring high performance.
Leveraging internal data with RAG
Important questions revolve around data: What is my internal data? How can I use it? Can I train based on this data with the correct structure? One powerful strategy for scaling ML systems with genAI is retrieval-augmented generation. RAG is the ability to use internal data to change the context of a general purpose model. By embedding and querying internal data, organizations can provide context-specific answers and improve the relevance of genAI outputs. For instance, uploading product documentation to a vector database allows a model to deliver precise, context-aware responses to user queries.
Key architectural considerations
Creating scalable and efficient MLops architectures requires careful attention to components like embeddings, prompts, and vector stores. Fine-tuning models for specific languages, geographies, or use cases ensures tailored performance. An MLops architecture that supports fine-tuning is more complicated and organizations should prioritize A/B testing across various building blocks to optimize outcomes and refine their solutions.
Metrics for model success
Aligning model outcomes with business objectives is essential. Metrics like customer satisfaction and click-through rates can measure real-world impact, helping organizations understand whether their models are delivering meaningful results. Human feedback is essential for evaluating generative models and remains the best practice. Human-in-the-loop systems help fine-tune metrics, check performance, and ensure models meet business goals.
In some cases, advanced generative AI tools can assist or replace human reviewers, making the process faster and more efficient. By closing the feedback loop and connecting predictions to user actions, there is opportunity for continuous improvement and more reliable performance.
Focus on solutions, not just models
The success of MLops hinges on building holistic solutions rather than isolated models. Solution architectures should combine a variety of ML approaches, including rule-based systems, embeddings, traditional models, and generative AI, to create robust and adaptable frameworks.
Organizations should ask themselves a few key questions to guide their AI/ML strategies:
- Do we need a general-purpose solution or a specialized model?
- How will we measure success and which metrics align with our goals?
- What are the trade-offs between commercial and open-source solutions, and how do licensing and integration affect our choices?
Here is the key: You are not just building models anymore, you are building solutions. You are building architectures that include many moving parts and each one of the building blocks has the power to change the experience and the metrics that you get from a solution. As MLops continues to evolve, organizations must adapt by focusing on scalable, metrics-driven architectures. By leveraging the right combination of tools and strategies, businesses can unlock the full potential of AI and machine learning to drive innovation and deliver measurable business results.
Yuval Fernbach is the co-founder and CTO of Qwak and currently serves as VP and CTO of MLops following Qwak’s acquisition by JFrog. In his role, he pioneers a fully managed, user-friendly machine learning platform, enabling creators to reshape data, construct, train, and deploy models, and oversee the complete machine learning life cycle.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
{kind=link}
Serverless was never a cure-all 18 Feb 2025, 10:00 am
An obituary for serverless computing might read something like this:
In loving memory of serverless computing, born from the fervent hopes of developers and cloud architects alike. Its life began with the promise of effortless scalability and reduced operational burdens, captivating many with the allure of “deploy and forget.” For a time, serverless thrived and was praised for its ability to manage fluctuating traffic with grace and dispatch.
However, as the years went by, the excitement faded. Serverless encountered the harsh realities of complexity and unforeseen costs. Loved ones learned that serverless alleviated some burdens but introduced others—debugging was the stuff of nightmares, and limitations suffocated creativity. Many despaired at its inability to fit every application’s needs, leading to anguished searches for reliable alternatives.
Ultimately, serverless computing succumbed to the harsh truth that it was not a universal solution but a specialized tool for niche scenarios. As we gather to reflect on its successes and failures, we must remember the lesson it taught us: Sometimes the most exciting new products can cloud our judgment. Serverless computing leaves behind a mixed legacy to remind us that no single approach reigns supreme in technology; the right tool always depends upon the problem it must solve.
Rest in peace, dear serverless. Your lessons will endure.
Let’s reflect for a moment on those who have tried serverless and emerged a bit wiser from the experience. Developers and organizations now understand the necessity of a hybrid approach, blending serverless and traditional architectures to address their diverse application needs. Yes, serverless benefits specific scenarios, such as bursty traffic and asynchronous components, but it is not a universal remedy.
What killed serverless?
Serverless architectures were originally promoted as a way for developers to rapidly deploy applications without the hassle of server management. The allure was compelling: no more server patching, automatic scalability, and the ability to focus solely on business logic while lowering costs. This promise resonated with many organizations eager to accelerate their digital transformation efforts.
Yet many organizations adopted serverless solutions without fully understanding the implications or trade-offs. It became evident that while server management may have been alleviated, developers faced numerous complexities. From database management to security vulnerabilities, the challenges of application development persisted, pushing enterprises to reconsider their cloud-based development strategies.
So, what are the realities of serverless adoption? Here are a few:
Serverless apps come with strict operational constraints. Cold start issues, time limits on function execution, and the necessity of using approved programming languages are some of the problems. Moreover, developers must learn how to handle asynchronous programming models, which complicate debugging and increase the learning curve associated with serverless.
Expenses skyrocketed for many enterprises using serverless. The pay-as-you-go model appears attractive for intermittent workloads, but it can quickly spiral out of control if an application operates under unpredictable traffic patterns or contains many small components. The requirement for scalability, while beneficial, also necessitates careful budget management—this is a challenge if teams are unprepared to closely monitor usage.
Debugging in a serverless environment poses significant hurdles. Locating the root cause of issues across multiple asynchronous components becomes more challenging than in traditional, monolithic architectures. Developers often spent the time they saved from server management struggling to troubleshoot these complex interactions, undermining the operational efficiencies serverless was meant to provide.
Smart strategies for cloud development
Serverless may still have a place in enterprise cloud strategy, but it should be integrated into the broader toolkit of application development methodologies.
Serverless computing may remain helpful in specific scenarios. Applications with sporadic traffic and isolated functions that can be independently tested may still be good candidates for serverless. However, traditional methods may offer better reliability and cost-effectiveness for applications with consistent loads or more predictable patterns.
Enterprises looking for predictability should opt for traditional architectures. This allows more intimate management of the environment and costs. Monolithic and containerized solutions may provide a more straightforward path to better control expenses and simplify troubleshooting.
A hybrid cloud strategy can enhance responsiveness and innovation. Organizations can mix serverless, containerized, and traditional architectures, tailoring their approach to the specific requirements of various applications. This can safeguard against reliance on any single paradigm.
Developer training is essential in a mixed methodology. Teams need to be skilled in both traditional and serverless paradigms to successfully navigate the complexities of modern application development.
Nice try, cloud providers
Today, serverless has proven to be a risky and often costly investment that does not suit the needs of most businesses. While it can effectively address specific scenarios, such as asynchronous applications with unpredictable traffic, most enterprises find that traditional architectures offer greater predictability and control. The myth that serverless eliminates all burdens has been dispelled as teams are left to manage complexities similar to conventional setups.
In the current cloud climate, it’s best to focus on a hybrid approach. Leverage serverless computing where it makes sense, but rely on more traditional methods to harness the strengths of both strategies. It’s time to admit that serverless didn’t live up to its hype and make choices that align with specific business needs. Sorry, cloud providers, but it’s time to leave this one behind.
{kind=link}
Large language models: The foundations of generative AI 17 Feb 2025, 11:46 am
Large language models (LLMs) such as GPT, Bard, and Llama have caught the public’s imagination and garnered a wide variety of reactions. They are also expected to grow dramatically in the coming years. According to Dimension Market Research, The Global LLM market is expected to reach $140.8 billion by 2033 at a CAGR of 40.7%.
This article looks behind the hype to help you understand the origins of large language models, how they’re built and trained, and the range of tasks they are specialized for. We’ll also look at the most popular LLMs in use today.
What is a large language model?
Language models go back to the early 20th century, but large language models (LLMs) emerged with a vengeance after neural networks were introduced. The Transformer deep neural network architecture, introduced in 2017, was particularly instrumental in the evolution from language models to LLMs.
Large language models are useful for a variety of tasks, including text generation from a descriptive prompt, code generation and code completion, text summarization, translating between languages, and text-to-speech and speech-to-text applications.
LLMs also have drawbacks, at least in their current developmental stage. Generated text is usually mediocre, and sometimes downright bad. LLMs are known to invent facts, called hallucinations, which might seem reasonable if you don’t know better. Language translations are rarely 100% accurate unless they’ve been vetted by a native speaker, which is usually only done for common phrases. Generated code often has bugs, and sometimes has no hope of running. While LLMs are usually fine-tuned to avoid making controversial statements or recommending illegal acts, it is possible to breach these guardrails using malicious prompts.
Training large language models requires at least one large corpus of text. Training examples include the 1B Word Benchmark, Wikipedia, the Toronto Books Corpus, the Common Crawl dataset, and public open source GitHub repositories. Two potential problems with large text datasets are copyright infringement and garbage. Copyright infringement is currently the subject of multiple lawsuits. Garbage, at least, can be cleaned up; an example of a cleaned dataset is the Colossal Clean Crawled Corpus (C4), an 800GB dataset based on the Common Crawl dataset.
The role of parameters in LLMs
Large language models are different from traditional language models in that they use a deep learning neural network, a large training corpus, and they require millions or more parameters or weights for the neural network.
Along with at least one large training corpus, LLMs require large numbers of parameters, also known as weights. The number of parameters grew over the years, until it didn’t. ELMo (2018) has 93.6 million parameters; BERT (2018) was released in 100-million and 340-million parameter sizes; GPT (2018) uses 117 million parameters; and T5 (2020) has 220 million parameters. GPT-2 (2019) has 1.6 billion parameters; GPT-3 (2020) uses 175 billion parameters; and PaLM (2022) has 540 billion parameters. GPT-4 (2023) has 1.76 trillion parameters.
In simpler terms: Imagine an LLM as a vast network of interconnected switches. Each switch has a setting (the parameter) that determines how it responds to input. During training, these switches are adjusted to optimize the network’s overall performance in understanding and generating language.
More parameters make a model more accurate, but models with higher parameters also require more memory and run more slowly. In 2023, we’ve started to see some relatively smaller models released at multiple sizes: for example, Llama 2 comes in sizes of 7 billion, 13 billion, and 70 billion, while Claude 2 has 93-billion and 137-billion parameter sizes.
However, it’s not just about the number of parameters. Other factors also play a crucial role:
- The quality of the training data: Even a model with many parameters will perform poorly if it’s trained on biased or low-quality data.
- The architecture of the model: The way the parameters are organized and connected also affects the model’s capabilities.
- The training process itself: Effective training techniques are essential for optimizing the parameters.
While parameters are essential to LLMs, they are the learned knowledge that allows the models to understand and generate human-like text. The number of parameters is important, but it’s just one that contribute to an LLM’s overall performance.
A history of AI models for text generation
Language models go back to Andrey Markov, who applied mathematics to poetry in 1913. Markov showed that in Pushkin’s Eugene Onegin, the probability of a character appearing depended on the previous character, and that, in general, consonants and vowels tended to alternate. Today, Markov chains are used to describe a sequence of events in which the probability of each event depends on the state of the previous one.
Markov’s work was extended by Claude Shannon in 1948 for communications theory, and again by Fred Jelinek and Robert Mercer of IBM in 1985 to produce a language model based on cross-validation (which they called deleted estimates), and applied to real-time large-vocabulary speech recognition. Essentially, a statistical language model assigns probabilities to sequences of words.
To quickly see a language model in action, just type a few words into Google Search, or a text message app on your phone, with auto-completion turned on.
In 2000, Yoshua Bengio and co-authors published a paper detailing a neural probabilistic language model in which neural networks replace the probabilities in a statistical language model, bypassing the curse of dimensionality and improving word predictions over a smoothed trigram model (then the state of the art) by 20% to 35%. The idea of feed-forward auto-regressive neural network models of language is still used today, although the models now have billions of parameters and are trained on extensive corpora; hence the term “large language model.”
Language models have continued to get bigger over time, with the goal of improving performance. But such growth has downsides. The 2021 paper, On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, questions whether we are going too far with the larger-is-better trend. The authors suggest weighing the environmental and financial costs first and investing resources into curating and documenting datasets rather than ingesting everything on the web.
Language models and LLMs explained
Current language models have a variety of tasks and goals and take various forms. For example, in addition to the task of predicting the next word in a document, language models can generate original text, classify text, answer questions, analyze sentiment, recognize named entities, recognize speech, recognize text in images, and recognize handwriting. Customizing language models for specific tasks, typically using small to medium-sized supplemental training sets, is called fine-tuning.
Some of the intermediate tasks that go into language models are the following:
- Segmentation (of the training corpus into sentences): LLMs are trained on vast amounts of text, which needs to be broken down into individual sentences for the model to learn the structure and relationships between words within sentences. Segmentation is the process of identifying sentence boundaries (e.g., using punctuation).
- Word tokenization: Tokenization breaks down the text into individual units (tokens), which can be words, sub-word units (like parts of words), or punctuation marks. This is a crucial first step before feeding text to an LLM.
- Stemming: Reduces words to their root form (e.g., “running” to “run”). While historically important in NLP, stemming is less crucial for modern LLMs because they often handle morphological variations implicitly through their training. LLMs are often trained on raw text or use sophisticated tokenization that handles these variations.
- Lemmatizing (conversion to the root word): Similar to stemming, but more sophisticated. Lemmatization uses dictionaries and grammatical rules to find the base or dictionary form of a word (e.g., “running” to “run”). Like stemming, it’s less critical for LLMs as they are good at dealing with different forms of the same word.
- (Part of speech) tagging: Identifying the grammatical role of each word in a sentence (e.g., noun, verb, adjective). While LLMs can often infer POS tags implicitly, having explicit POS tags as input can sometimes be useful for specific tasks or fine-tuning.
- Stopword Identification and (possibly) Removal: Stopwords are common words (e.g., “the,” “a,” “is”) that are often removed in traditional NLP tasks to reduce noise. For LLMs, removing stopwords is often not beneficial, as these words contribute to the meaning and structure of sentences. LLMs generally benefit from having the full context.
- Named-entity recognition (NER): Identifying and classifying named entities in text (e.g., people, organizations, locations). LLMs are very good at NER and can be used to extract this information from text. This can be a task LLMs are fine-tuned for, or even performed through prompt engineering.
- Text classification: Assigning categories or labels to text documents. LLMs can be used for text classification tasks. You can fine-tune an LLM to classify text, or use prompt engineering to guide the model towards the desired categories.
- Chunking (breaking sentences into meaningful phrases): Grouping words into phrases (e.g., noun phrases, verb phrases). While LLMs may not explicitly use chunking as a preprocessing step, they implicitly understand phrase structure and can be prompted to extract phrases.
- Coreference resolution (finding all expressions that refer to the same entity in a text): Identifying all mentions of the same entity in a text, even if they are referred to using different words or pronouns (e.g., “John,” “he,” “the CEO”). LLMs are capable of performing coreference resolution, and this is a task that can be used to improve the LLM’s understanding of relationships between entities in a text.
Several of these are also useful as tasks or applications in and of themselves, such as text classification.
Large language models are different from traditional language models in that they use a deep learning neural network and a large training corpus, and they require millions or more parameters or weights for the neural network. Training an LLM is a matter of optimizing the weights so that the model has the lowest possible error rate for its designated task. An example task would be predicting the next word at any point in the corpus, typically in a self-supervised fashion.
A look at the most popular LLMs
The recent explosion of large language models was triggered by the 2017 paper, Attention is All You Need, which introduced the Transformer as, “a new simple network architecture … based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.”
Here are some of the top large language models in use today.
ELMo
ELMo is a 2018 deep contextualized word representation LLM from AllenNLP that models both complex characteristics of word use and how that use varies across linguistic contexts. The original model has 93.6 million parameters and was trained on the 1B Word Benchmark.
BERT
BERT is a 2018 language model from Google AI based on the company’s Transformer neural network architecture. BERT was designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. The two model sizes initially used were 100 million and 340 million total parameters. The LLM uses masked language modeling (MLM), in which ~15% of tokens are “corrupted” for training. It was trained on English Wikipedia plus the Toronto Books Corpus.
Gemini
Google’s Gemini, based on its Bard technology, offers multimodal capabilities and focus on efficiency (with versions like Nano for on-device processing), Gemini is likely to be a leader in 2025. We can anticipate further enhancements in its ability to understand and generate diverse content, including code and images.
T5
The 2020 Text-To-Text Transfer Transformer (T5) model from Google synthesizes a new model based on the best transfer learning techniques from GPT, ULMFiT, ELMo, BERT, and their successors. It uses the open source Colossal Clean Crawled Corpus (C4) as a pre-training dataset. The standard C4 for English is an 800GB dataset based on the original Common Crawl dataset. T5 reframes all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. The base T5 model has about 220 million total parameters.
GPT family
OpenAI, an AI research and deployment company, has a mission “to ensure that artificial general intelligence (AGI) benefits all of humanity.” Of course, it hasn’t achieved AGI yet—and some AI researchers, such as machine learning pioneer Yann LeCun of Meta-FAIR, think that OpenAI’s current approach to AGI is a dead end.
OpenAI is responsible for the GPT family of language models. Here’s a quick look at the entire GPT family and its evolution since 2018. (Note that the entire GPT family is based on Google’s Transformer neural network architecture, which is legitimate because Google open-sourced Transformer.)
GPT (Generative Pretrained Transformer) is a 2018 model from OpenAI that uses about 117 million parameters. GPT is a unidirectional transformer pre-trained on the Toronto Book Corpus, and was trained with a causal language modeling (CLM) objective, meaning that it was trained to predict the next token in a sequence.
GPT-2 is a 2019 direct scale-up of GPT with 1.5 billion parameters, trained on a dataset of 8 million web pages encompassing ~40GB of text data. OpenAI originally restricted access to GPT-2 because it was “too good” and would lead to “fake news.” The company eventually relented, although the potential social problems became even worse with the release of GPT-3.
GPT-3 is a 2020 autoregressive language model with 175 billion parameters, trained on a combination of a filtered version of Common Crawl, WebText2, Books1, Books2, and English Wikipedia. The neural net used in GPT-3 is similar to that of GPT-2, with a couple of additional blocks.
The biggest downside of GPT-3 is that it tends to “hallucinate,” meaning that it makes up facts with no discernable basis. GPT-3.5 and GPT-4 have the same problem, albeit to a lesser extent.
GPT-3.5 is a set of 2022 updates to GPT-3 and CODEX. The gpt-3.5-turbo model is optimized for chat but also works well for traditional completion tasks.
GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that OpenAI claims exhibits human-level performance on some professional and academic benchmarks. GPT-4 outperformed GPT-3.5 in various simulated exams, including the Uniform Bar Exam, the LSAT, the GRE, and several AP subject exams.
Note that GPT-3.5 and GPT-4 performance has changed over time. A July 2023 Stanford paper identified several tasks, including prime number identification, where the behavior varied greatly between March 2023 and June 2023.
The latest iterations (likely beyond GPT-4 by 2025) are expected to have even greater capabilities in text generation, reasoning, and multimodal understanding (handling images, audio, etc.). Expect improvements in handling longer contexts and reducing hallucinations
ChatGPT and BingGPT are chatbots that were originally based on gpt-3.5-turbo and in March 2023 upgraded to use GPT-4. Currently, to access the version of ChatGPT based on GPT-4, you need to subscribe to ChatGPT Plus. The standard ChatGPT, based on GPT-3.5, was trained on data that cut off in September 2021.
The latest iterations (likely beyond GPT-4 in 2025) are expected to have greater capabilities in text generation, reasoning, and multimodal understanding (handling images, audio, etc.). Expect improvements in handling longer contexts and reducing hallucinations
BingGPT, aka “The New Bing,” which you can access in the Microsoft Edge browser, was also trained on data that cut off in 2021. When asked, the bot claims that it is constantly learning and updating its knowledge with new information from the web.

BingGPT explains its language model and training data, as seen in the text window at the right of the screen.
In early March 2023, Professor Pascale Fung of the Centre for Artificial Intelligence Research at the Hong Kong University of Science & Technology gave a talk on ChatGPT evaluation. It’s well worth the hour to watch it.
LaMDA
LaMDA (Language Model for Dialogue Applications), Google’s 2021 “breakthrough” conversation technology, is a Transformer-based language model trained on dialogue and fine-tuned to significantly improve the sensibleness and specificity of its responses. One of LaMDA’s strengths is that it can handle the topic drift that is common in human conversations. While you can’t directly access LaMDA, its impact on the development of conversational AI is undeniable as it pushed the boundaries of what’s possible with language models and paved the way for more sophisticated and human-like AI interactions.
PaLM
PaLM (Pathways Language Model) is a dense decoder-only Transformer model from Google Research with 540 billion parameters, trained with the Pathways system. PaLM was trained using a combination of English and multilingual datasets that include high-quality web documents, books, Wikipedia, conversations, and GitHub code. Google also created a “lossless” vocabulary that preserves all whitespace (especially important for code), splits out-of-vocabulary Unicode characters into bytes, and splits numbers into individual tokens, one for each digit.
Google has made PaLM 2 accessible through the PaLM API and MakerSuite. This means developers can now use PaLM 2 to build their own generative AI applications.
PaLM-Coder is a version of PaLM 540B fine-tuned on a Python-only code dataset.
PaLM-E
PaLM-E is a 2023 embodied (for robotics) multimodal language model from Google. The researchers began with PaLM and “embodied” it (the E in PaLM-E), by complementing it with sensor data from the robotic agent. PaLM-E is also a generally-capable vision-and-language model; in addition to PaLM, it incorporates the ViT-22B vision model.
Bard has been updated multiple times since its release. In April 2023 it gained the ability to generate code in 20 programming languages. In July 2023 it gained support for input in 40 human languages, incorporated Google Lens, and added text-to-speech capabilities in over 40 human languages.
LLaMA
LLaMA (Large Language Model Meta AI) is a 65-billion parameter “raw” large language model released by Meta AI (formerly known as Meta-FAIR) in February 2023. According to Meta:
Training smaller foundation models like LLaMA is desirable in the large language model space because it requires far less computing power and resources to test new approaches, validate others’ work, and explore new use cases. Foundation models train on a large set of unlabeled data, which makes them ideal for fine-tuning for a variety of tasks.
LLaMA was released at several sizes, along with a model card that details how it was built. Originally, you had to request the checkpoints and tokenizer, but they are in the wild now: a downloadable torrent was posted on 4chan by someone who properly obtained the models by filing a request, according to Yann LeCun of Meta AI.
Llama
Llama 2 is the next generation of Meta AI’s large language model, trained between January and July 2023 on 40% more data (2 trillion tokens from publicly available sources) than LLaMA 1 and having double the context length (4096). Llama 2 comes in a range of parameter sizes—7 billion, 13 billion, and 70 billion—as well as pretrained and fine-tuned variations. Meta AI calls Llama 2 open source, but there are some who disagree, given that it includes restrictions on acceptable use. A commercial license is available in addition to a community license.
Llama 2 is an auto-regressive language model that uses an optimized Transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety. Llama 2 is currently English-only. The model card includes benchmark results and carbon footprint stats. The research paper, Llama 2: Open Foundation and Fine-Tuned Chat Models, offers additional detail.
Claude
Claude 3.5 is the current leading version.
Anthropic’s Claude 2, released in July 2023, accepts up to 100,000 tokens (about 70,000 words) in a single prompt, and can generate stories up to a few thousand tokens. Claude can edit, rewrite, summarize, classify, extract structured data, do Q&A based on the content, and more. It has the most training in English, but also performs well in a range of other common languages, and still has some ability to communicate in less common ones. Claude also has extensive knowledge of programming languages.
Claude was constitutionally trained to be Helpful, Honest, and Harmless (HHH), and extensively red-teamed to be more harmless and harder to prompt to produce offensive or dangerous output. It doesn’t train on your data or consult the internet for answers, although you can provide Claude with text from the internet and ask it to perform tasks with that content. Claude is available to users in the US and UK as a free beta, and has been adopted by commercial partners such as Jasper (a generative AI platform), Sourcegraph Cody (a code AI platform), and Amazon Bedrock.
Conclusion
As we’ve seen, large language models are under active development at several companies, with new versions shipping more or less monthly from OpenAI, Google AI, Meta AI, and Anthropic. While none of these LLMs achieve true artificial general intelligence (AGI), new models mostly tend to improve over older ones. Still, most LLMs are prone to hallucinations and other ways of going off the rails, and may in some instances produce inaccurate, biased, or other objectionable responses to user prompts. In other words, you should use them only if you can verify that their output is correct.
{kind=link}
3 key features of Postman’s AI Agent Builder 17 Feb 2025, 10:00 am
The software landscape is shifting from passive business processes to dynamic, AI-driven workflows. AI agents—systems that interact with APIs, make decisions, and execute complex tasks—are at the forefront of this transformation. While large language models (LLMs) laid the groundwork, agentic AI is redefining how businesses automate operations. However, building these agents is a challenge, requiring developers to integrate multiple tools, testing frameworks, and APIs.
Recognizing this shift, Postman has introduced AI Agent Builder, a suite of tools designed to simplify the creation, testing, and deployment of AI agents. This new offering aims to democratize agent development, allowing teams to focus on designing intelligent workflows rather than wrestling with technical overhead.
This article explores three key AI-driven capabilities within Postman that enhance API development and testing. These features help developers
- Evaluate and compare LLMs based on performance and cost.
- Orchestrate intelligent automations as agentic workflows.
- Discover and integrate relevant APIs as agent tools, without coding complexity.
We’ll examine each capability in more detail and discuss how they facilitate AI-driven development for teams looking to harness AI in for intelligent business processes.
AI protocol: Extending Postman’s API testing to AI models
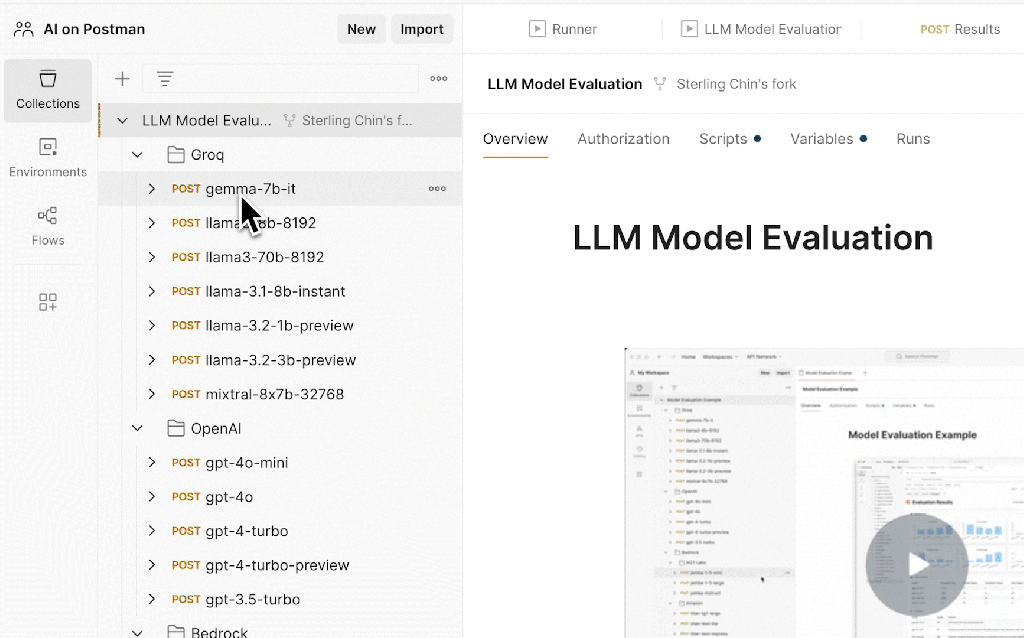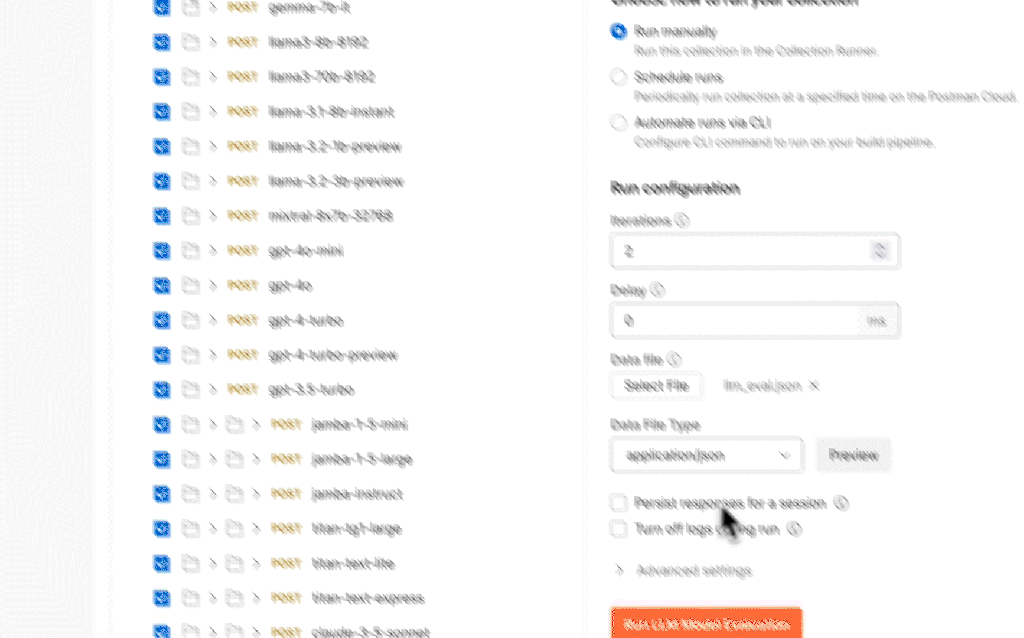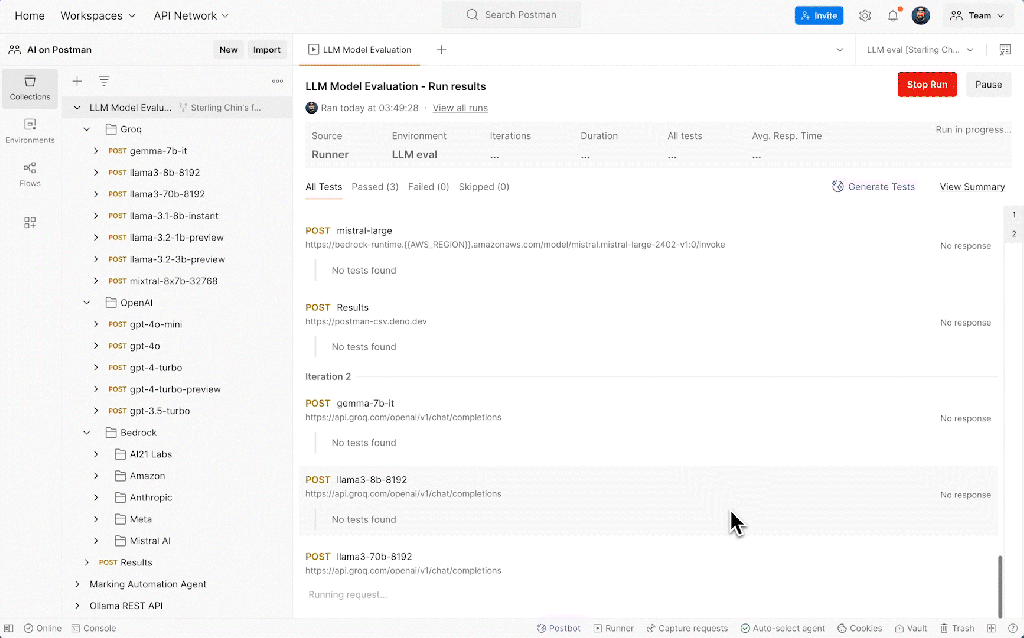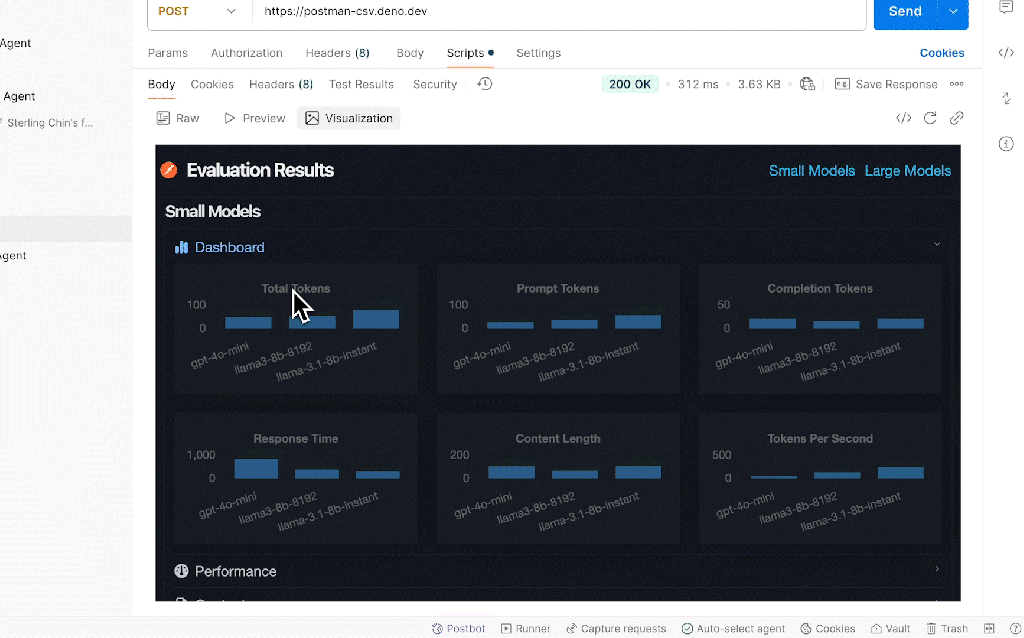
Postman’s new AI Protocol extends its existing API testing platform to handle AI model interactions. By treating large language models like powerful APIs, development teams can systematically test both system and user prompts, configure model properties for desired creativity or predictability, and benchmark performance based on response time, accuracy, and cost. Collections of prompts act as versioned assets, allowing teams to track prompt changes over time, refine parameters, and maintain consistent test suites as new models or updated versions are released.
Postman
The recent debut of DeepSeek R1 illustrates how quickly organizations scramble to test newly available foundation models for potential performance gains or cost savings. Rather than setting up parallel machine learning pipelines or adopting additional tools, teams can leverage Postman’s existing interface, environment variables, and versioning features to integrate model testing immediately. This approach helps prevent fragmentation across multiple LLM providers by enabling side-by-side comparisons and centralized metrics. Shortly after DeepSeek R1’s release, Postman customers were already evaluating their current prompt collections against both R1 and OpenAI’s o1 model to determine which option delivered the best results for their specific use cases.
Postman
Agent Builder: Creating agentic workflows with a visual low-code tool
Postman’s Agent Builder uses the platform’s Flows visual programming interface to create multi-step workflows that integrate both API requests and AI interactions—no extensive coding required. With full integration of the new Postman AI protocol, developers can embed LLMs into their automation sequences to enable dynamic, adaptive, and intelligence-driven processes. For example, AI requests can enrich workflows with real-time data, make context-aware decisions, and discover relevant tools to address business needs. Flows also includes low-code building blocks for conditional logic, scripting capabilities for custom scenarios, and built-in data visualization and reporting, enabling teams to quickly tailor workflows to specific business requirements, reduce development overhead, and deliver actionable insights faster.
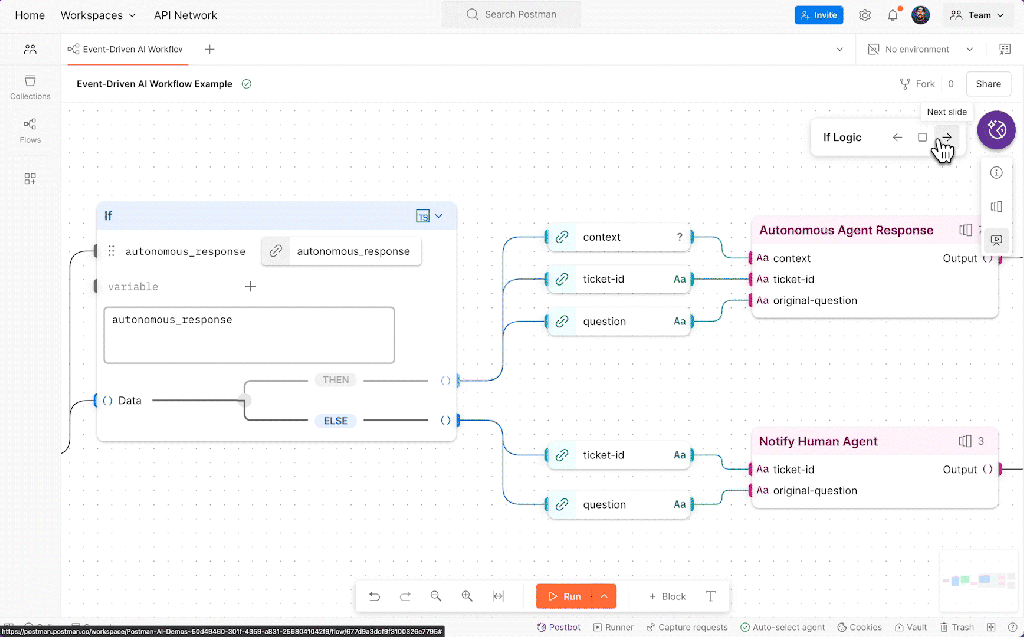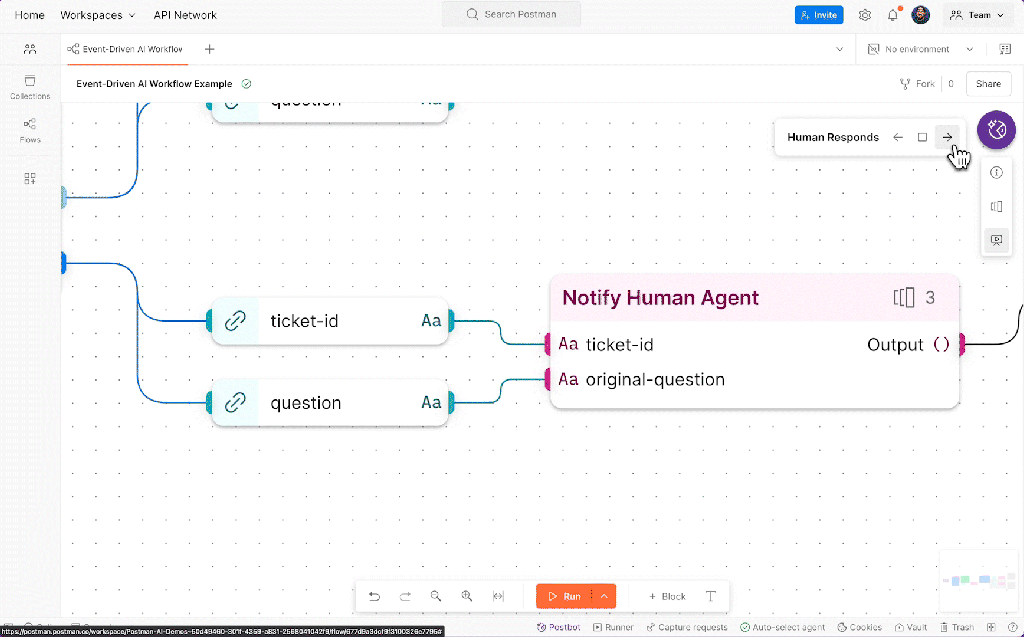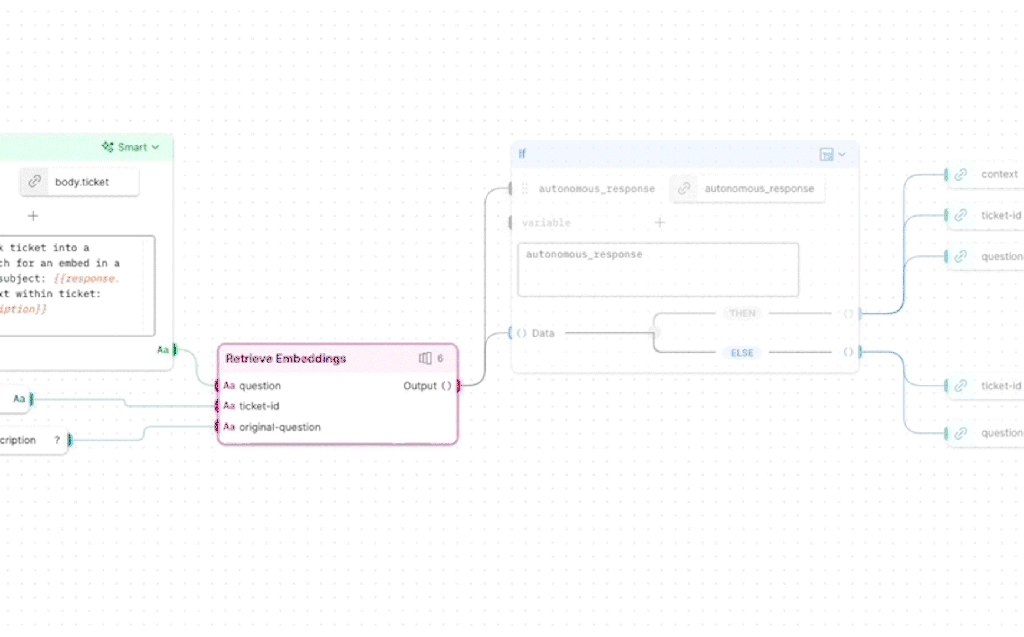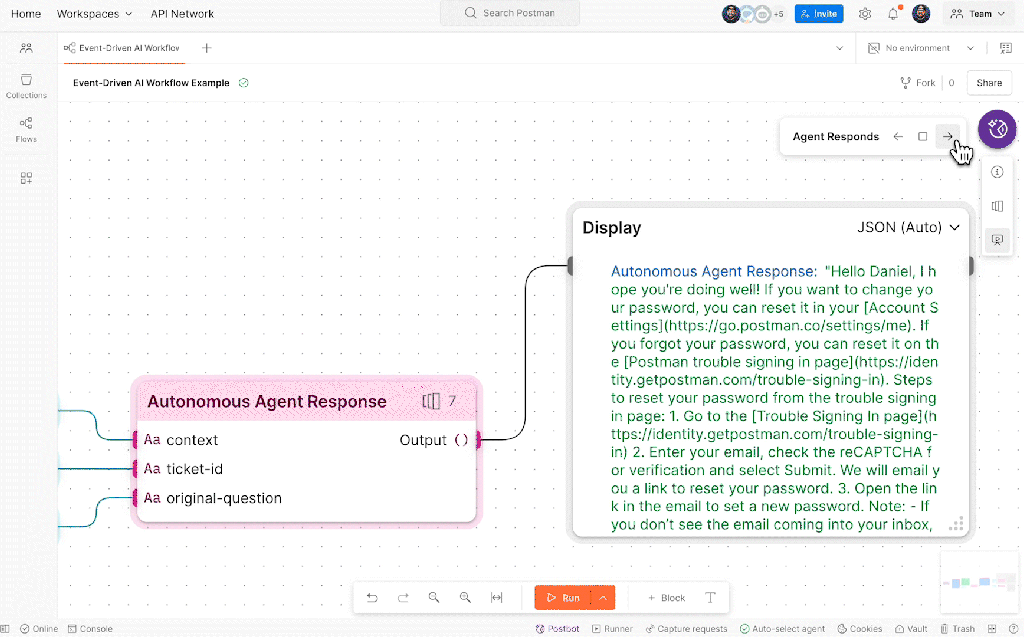
Postman
This Agent Builder approach supports rapid experimentation, local testing, and debugging, effectively fitting into a developer’s “inner loop.” Collaboration features allow teams to label and section workflows, making it easier to share and explain complex automations with colleagues or stakeholders. For multi-service workflows, developers can confirm each step under realistic conditions using scenarios to ensure consistency and reliability well before final deployment. Scenarios can be versioned and shared, streamlining the process of testing and evaluating agents built with Flows.
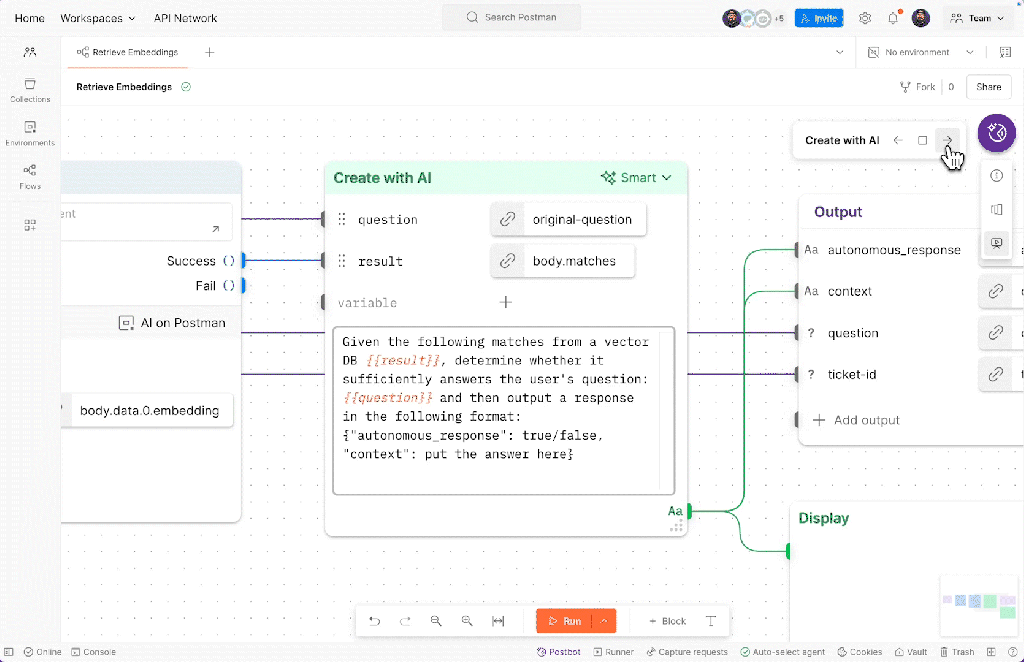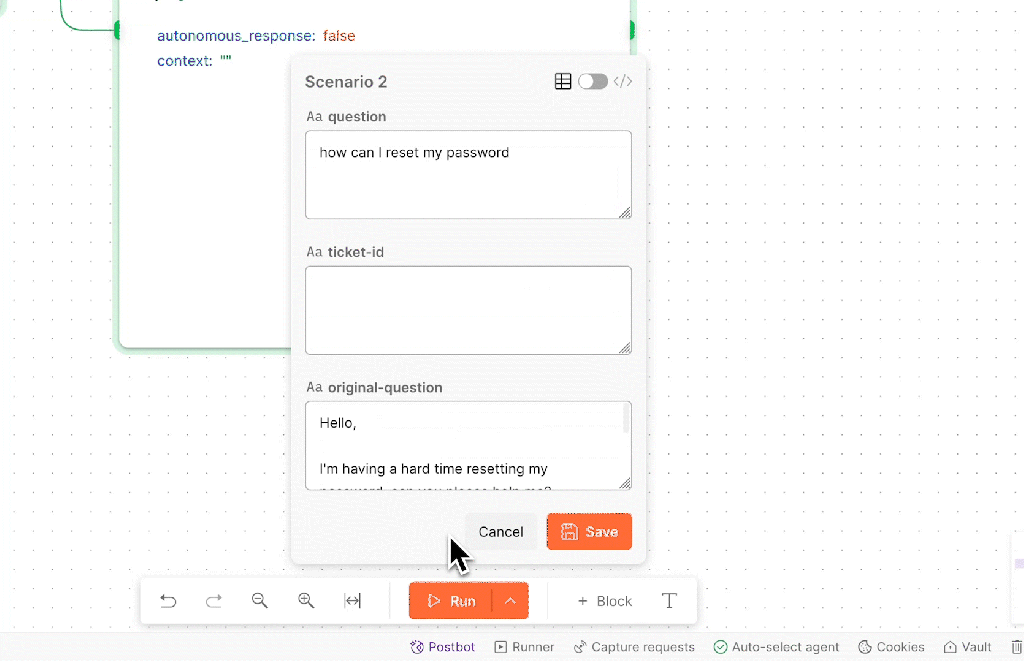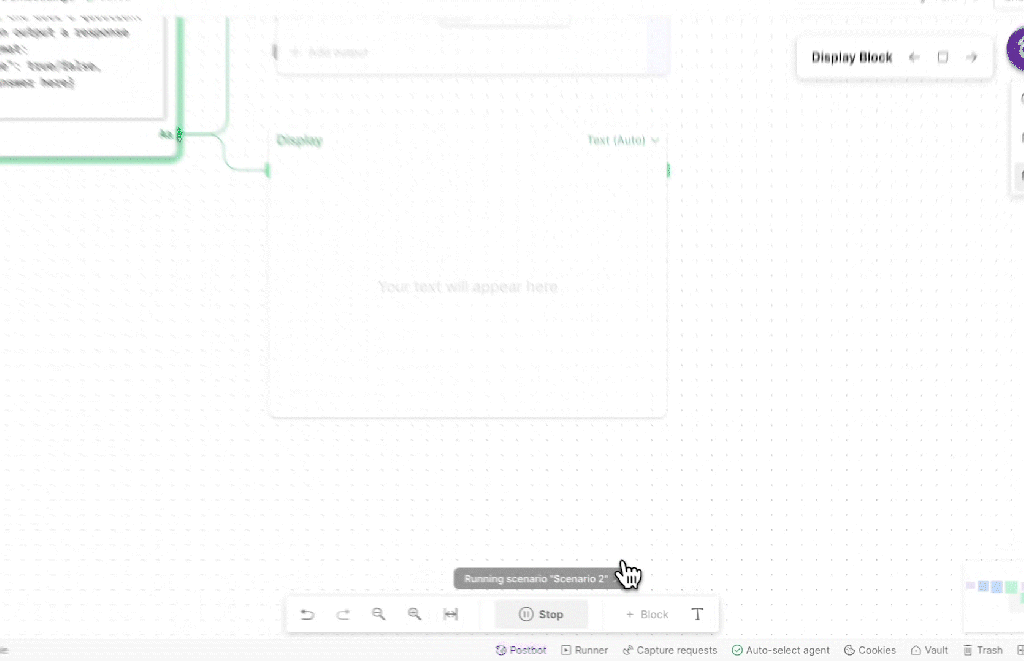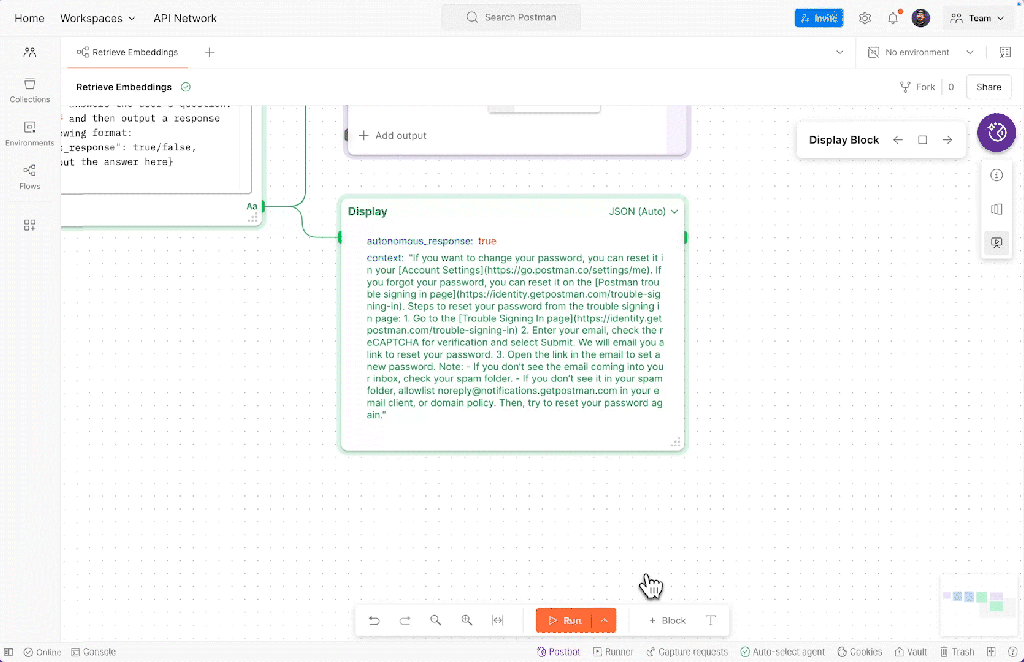
Postman
API Discovery and Tool Generation: Easy access to verified APIs
Postman’s API Discovery and Tool Generation capabilities add the ability to find and integrate the right APIs to use with AI agents. By leveraging Postman’s network of more than 100,000 public APIs, developers can automatically generate “agent tools,” removing the need to manually write wrappers or boilerplate code for those APIs. This scaffolding step includes specifying which agent framework (e.g., Node.js, Python, Java) and which target LLM service or library the agent will use, even if official SDKs don’t exist yet. As a result, teams can focus on core workflow logic rather than wrestling with setup details.
Postman
Moreover, verified partner APIs in the catalog help ensure agents are configured accurately for critical business tasks. Instead of researching and integrating each API from scratch, developers can rely on the Postman network to surface endpoints, request payloads, and authentication specifications suited to specific AI-driven use cases. By consolidating discovery, documentation, and testing in one place, teams can filter through a vast API collection, preview endpoints, run sample requests directly in their browser or the Postman client, and then generate ready-to-run code. This results in faster onboarding, more reliable integrations, and a broader range of capabilities for AI-powered applications. Without these built-in safeguards and automation, developers would need to manually verify each API’s reliability, usage patterns, and code compatibility—an error-prone and time-consuming process.
A unified approach to AI-driven automation
By combining AI model testing, low-code agent building, and tool discovery in one platform, Postman helps developers standardize how AI workflows and traditional APIs intersect. Teams can build on familiar API practices—such as versioning, environment variables, and collaboration—while extending them to AI-powered services. This unified approach fosters consistent testing, quality standards, and data management across both conventional APIs and AI-driven workflows.
For organizations looking to operationalize AI, these capabilities provide a smooth pathway from prompt engineering and multi-LLM evaluation to production-grade intelligent automation, without juggling multiple platforms, integrations, or tools.
For deeper technical details and documentation, visit the official Postman AI Agent Builder documentation. Whether you’re a newcomer experimenting with LLMs or a seasoned pro looking for enterprise-grade testing and integration, Postman’s latest features aim to simplify and unify your AI development workflow.
Rodric Rabbah is the head of product for Flows at Postman. An accomplished entrepreneur and technologist, Rabbah founded Nimbella, a serverless cloud company that was successfully acquired by DigitalOcean, where he led the launch of DigitalOcean Functions. He is the main creator and developer behind Apache OpenWhisk, the open-source platform for serverless computing. He created OpenWhisk while at IBM Research, where he also led the development and operations of IBM Cloud Functions.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send inquiries to doug_dineley@foundryco.com.
{kind=link}
How to keep AI hallucinations out of your code 17 Feb 2025, 10:00 am
It turns out androids do dream, and their dreams are often strange. In the early days of generative AI, we got human hands with eight fingers and recipes for making pizza sauce from glue. Now, developers working with AI-assisted coding tools are also finding AI hallucinations in their code.
“AI hallucinations in coding tools occur due to the probabilistic nature of AI models, which generate outputs based on statistical likelihoods rather than deterministic logic,” explains Mithilesh Ramaswamy, a senior engineer at Microsoft. And just like that glue pizza recipe, sometimes these hallucinations escape containment.
AI coding assistants are increasingly omnipresent, and usage is growing, with 62% of respondents saying they were using AI coding tools in the May 2024 Stack Overflow developer survey. So how can you prevent AI hallucinations from ruining your code? We asked developers and tech leaders experienced with using AI coding assistants for their tips.
How AI hallucinations infect code
Microsoft’s Ramaswamy, who works every day with AI tools, keeps a list of the sorts of AI hallucinations he encounters: “Generated code that doesn’t compile; code that is overly convoluted or inefficient; and functions or algorithms that contradict themselves or produce ambiguous behavior.” Additionally, he says, “AI hallucinations sometimes just make up nonexistent functions” and “generated code may reference documentation, but the described behavior doesn’t match what the code does.”
Komninos Chatzipapas, founder of HeraHaven.ai, gives an example of a specific problem of this type. “On our JavaScript back-end, we had a function to deduct credit from a user based on their ID,” he says. “The function expected an object containing an ID value as its parameter, but the coding assistant just put the ID as the parameter.” He notes that in loosely typed languages like JavaScript, problems like these are more likely to slip past language parsers. The error Chatzipapas encountered “crashed our staging environment, but was fortunately caught before pushed to production.”
How does code like this slip into production? Monojit Banerjee, a lead in the AI platform organization at Salesforce, describes the code output by many AI assistants as “plausible but incorrect or non-functional.” Brett Smith, distinguished software developer at SAS, notes that less experienced developers are especially likely to be misled by the AI tool’s confidence, “leading to flawed code.”
The consequences of flawed AI code can be significant. Security holes and compliance issues are top of mind for many software companies, but some issues are less immediately obvious. Faulty AI-generated code adds to overall technical debt, and it can detract from the efficiency code assistants are intended to boost. “Hallucinated code often leads to inefficient designs or hacks that require rework, increasing long-term maintenance costs,” says Microsoft’s Ramaswamy.
Fortunately, the developers we spoke with had plenty of advice about how to ensure AI-generated code is correct and secure. There were two categories of tips: how to minimize the chance of code hallucinations, and how to catch hallucinations after the fact.
Reducing AI hallucinations in your code
The ideal would of course be to never encounter AI hallucinations at all. While that’s unlikely (not with the current state of the art), the following precautions can help reduce issues in AI-generated code.
Write clear and detailed prompts
The adage “garbage in, garbage out” is as old as computer science—and it applies to LLMs, as well, especially when you’re generating code by prompting rather than using an autocomplete assistant. Many of the experts we spoke to urged developers to get their prompt engineering game on point. “It’s best to ask bounded questions and critically examine the results,” says Andrew Sellers, head of technology strategy at Confluent. “Usage data from these tools suggest that outputs tend to be more accurate for questions with a smaller scope, and most developers will be better at catching errors by frequently examining small blocks of code.”
Ask for references
LLMs like ChatGPT are notorious for making up citations in school papers and legal briefs. But code-specific tools have made great strides in that area. “Many models are supporting citation features,” says Salesforce’s Banerjee. “A developer should ask for citations or API reference wherever possible to minimize hallucinations.”
Make sure your AI tool has trained on the latest software
Most genAI chatbots can’t tell you who won your home team’s baseball game last night, and they have limitations keeping up with software tools and updates as well. “One of the ways you can predict whether a tool will hallucinate or provide biased outputs is by checking its knowledge cut-offs,” says Stoyan Mitov, CEO of Dreamix and co-founder of the Citizens app. “If you plan on using the latest libraries or frameworks that the tool doesn’t know about, the chances that the output will be flawed are high.”
Train your model to do things your way
Travis Rehl, CTO at Innovative Solutions, says what generative AI tools need to work well is “context, context, context.” You need to provide good examples of what you want and how you want it done, he says. “You should tell the LLM to maintain a certain pattern, or remind it to use a consistent method so it doesn’t create something new or different.” If you fail to do so, you can run into a subtle type of hallucination that injects anti-patterns into your code. “Maybe you always make an API call a particular way, but the LLM chooses a different method,” he says. “While technically correct, it did not follow your pattern and thus deviated from what the norm needs to be.”
A concept that takes this idea to its logical conclusion is retrieval augmented generation, or RAG, in which the model uses one or more designated “sources of truth” that contain code either specific to the user or at least vetted by them. “Grounding compares the AI’s output to reliable data sources, reducing the likelihood of generating false information,” says Mitov. RAG is “one of the most effective grounding methods,” he says. “It improves LLM outputs by utilizing data from external sources, internal codebases, or API references in real time.”
Many available coding assistants already integrate RAG features—the one in Cursor is called @codebase, for instance. If you want to create your own internal codebase for an LLM to draw from, you would need to store it in a vector database; Banerjee points to Chroma as one of the most popular options.
Catching AI hallucinations in your code
Even with all of these protective measures, AI coding assistants will sometimes make mistakes. The good news is that hallucinations are often easier to catch in code than in applications where the LLM is writing plain text. The difference is that code is executable and can be tested. “Coding is not subjective,” as Innovative Solutions’ Rehl points out. “Code simply won’t work when it’s wrong.” Experts offered a few ways to spot mistakes in generated code.
Use AI to evaluate AI-generated code
Believe it or not, AI assistants can evaluate AI-generated code for hallucinations—often to good effect. For instance, Daniel Lynch, CEO of Empathy First Media, suggests “writing supporting documentation on the code so that you can have the AI evaluate the provided code in a new instance and determine if it satisfies the requirements of the intended use case.”
HeraHaven’s Chatzipapas suggests that AI tools can do far more in judging output from other tools. “Scaling test-time compute deals with the issue where, for the same input, an LLM can generate a variety of responses, all with different levels of quality,” he explains. “There are many ways to make it work but the simplest one is to query the LLM multiple times and then use a smaller ‘verifier’ AI model to pick which answer is better to present to the end user. There are also more sophisticated ways where you can cluster the different answers you get and pick one from the largest cluster (since that one has received more implied ‘votes’).”
Maintain human involvement and expertise
Even with machine assistance, most people we spoke to saw human beings as the last line of defense against AI hallucination. Most saw human involvement remaining crucial to the coding process for the foreseeable future. ” Always use AI as a guide, not a source of truth,” says Microsoft’s Ramaswamy. “Treat AI-generated code as a suggestion, not a replacement for human expertise.”
That expertise shouldn’t just be around programming generally; you should stay intimately acquainted with the code that powers your applications. “It can sometimes be hard to spot a hallucination if you’re unfamiliar with a codebase,” says Rehl. Having hands-on experience in the codebase is critical to spotting deviations in specific methods or the overall code pattern, for example.
Test and review your code
Fortunately, the tools and techniques most well-run shops use to catch human errors, from IDE tools to unit tests, can also catch AI hallucinations. “Teams should continue doing pull requests and code reviews just as if the code were written by humans,” says Confluent’s Sellers. “It’s tempting for developers to use these tools to automate more in achieving continuous delivery. While laudable, it’s incredibly important for developers to prioritize QA controls when increasing automation.”
“I cannot stress enough the need to use good linting tools and SAST scanners throughout the development cycle,” says SAS’s Smith. “IDE plugins, integration into the CI, and pull requests are the bare minimum to ensure hallucinations do not make it to production.”
“A mature devops pipeline is essential, where each line of code will be unit tested during the development lifecycle,” adds Salesforce’s Banerjee. “The pipeline will only promote the code to staging and production after tests and builds are passed. Moreover, continuous deployment is essential to roll back code as soon as possible to avoid a long tail of any outage.”
Highlight AI-generated code
Devansh Agarwal, a machine learning engineer at Amazon Web Services, recommends a technique that he calls “a little experiment of mine”: Use the code review UI to call out parts of the codebase that are AI-generated. “I often see hundreds of lines of unit test code being approved without any comments from the reviewer,” he says, “and these unit tests are one of the use cases where I and others often use AI. Once you mark that these are AI-generated, then people take more time in reviewing them.”
This doesn’t just help catch hallucinations, he says. “It’s a great learning opportunity for everyone in the team. Sometimes it does an amazing job and we as humans want to replicate it!”
Keep the developer in the driver’s seat
Generative AI is ultimately a tool, nothing more and nothing less. Like all other tools, it has quirks. While using AI changes some aspects of programming and makes individual programmers more productive, its tendency to hallucinate means that human developers must remain in the driver’s seat for the foreseeable future. “I’m finding that coding will slowly become a QA- and product definition-heavy job,” says Rehl. As a developer, “your goal will be to understand patterns, understand testing methods, and be able to articulate the business goal you want the code to achieve.”
{kind=link}
What if generative AI can’t get it right? 17 Feb 2025, 10:00 am
Large language models (LLMs) keep getting faster and more capable. That doesn’t mean they’re correct. This is arguably the biggest shortcoming of generative AI: It can be incredibly fast while simultaneously being incredibly wrong. This may not be an issue in areas like marketing or software development, where tests and reviews can find and fix errors. However, as analyst Benedict Evans points out, “There is also a broad class of task that we would like to be able to automate, that’s boring and time-consuming and can’t be done by traditional software, where the quality of the result is not a percentage, but a binary.” In other words, he says, “For some tasks, the answer is not better or worse: It’s right or not right.”
Until generative AI can give us facts and not probabilities, it’s simply not going to be good enough for a wide swath of use cases, no matter how much the next DeepSeek speeds up its calculations.
Fact-checking AI
In January DeepSeek seemingly changed everything in AI. Mind-blowing speed at dramatically lower costs. As Lucas Mearian writes, DeepSeek sent “shock waves” through the AI community, but its impact likely won’t last. Soon there will be something faster and cheaper. But will there be something that provides what we most need? That is, more accuracy and truth? We can’t solve that problem by making AI more open. It’s deeper than that.
“Every week there’s a better AI model that gives better answers,” Evans notes. “But a lot of questions don’t have better answers, only right answers, and these models can’t do that.” This isn’t to say performance and cost improvements aren’t needed. DeepSeek, for example, makes genAI models more affordable for enterprises that want to build them into applications. And, as investor Martin Casado and former Microsoft executive Steven Sinofsky suggest, the application layer, not infrastructure, is the most interesting and important area for genAI development.
The problem, however, is that many applications depend on right-or-wrong answers, not “probabilistic … outputs based on patterns they have observed in the training data,” as I’ve covered before. As Evans expresses it, “There are some tasks where a better model produces better, more accurate results, but other tasks where there’s no such thing as a better result and no such thing as more accurate, only right or wrong.”
In the absence of the ability to speak truth rather than probabilities, the models may be worse than useless for many tasks. The problem is that these models can be exceptionally confident and wrong at the same time. It’s worth quoting an Evans example at length. In trying to find the number of elevator operators in the United States in 1980 (a number clearly identified in a U.S. Census report), he gets a range of answers:
First, I try [the question] cold, and I get an answer that’s specific, unsourced, and wrong. Then I try helping it with the primary source, and I get a different wrong answer with a list of sources, that are indeed the U.S. Census, and the first link goes to the correct PDF… but the number is still wrong. Hmm. Let’s try giving it the actual PDF? Nope. Explaining exactly where in the PDF to look? Nope. Asking it to browse the web? Nope, nope, nope…. I don’t need an answer that’s perhaps more likely to be right, especially if I can’t tell. I need an answer that is right.
Just wrong enough
But what about questions that don’t require a single right answer? For the particular purpose Evans was trying to use genAI, the system will always be just enough wrong to never give the right answer. Maybe, just maybe, better models will fix this over time and become consistently correct in their output. Maybe.
The more interesting question Evans poses is whether there are “places where [generative AI’s] error rate is a feature, not a bug.” It’s hard to think of how being wrong could be an asset, but as an industry (and as humans) we tend to be really bad at predicting the future. Today we’re trying to retrofit genAI’s non-deterministic approach to deterministic systems, and we’re getting hallucinating machines in response.
This doesn’t seem to be yet another case of Silicon Valley’s overindulgence in wishful thinking about technology (blockchain, for example). There’s something real in generative AI. But to get there, we may need to figure out new ways to program, accepting probability rather than certainty as a desirable outcome.
{kind=link}
AI coding assistants limited but helpful, developers say 15 Feb 2025, 2:27 am
AI coding assistants still need to mature, but they are already helpful according to several attendees of a recent Silicon Valley event for software developers.
Software developers who attended the DeveloperWeek conference in Santa Clara, CA, on February 12 were mostly optimistic about AI coding assistants, after having tried them out. “They certainly provide an opportunity to accelerate software development,” said Jens Wessling, CTO and chief architect at software security company Veracode. Wessling has used GitHub Copilot, Tabnine, and JetBrains AI Assistant. “It’ll be interesting to see how in the long term they address issues like security and correctness, but it’s a step in an interesting direction.”
“They’re great as tools,” said Juan Salas, CTO at Alto, which provides software development services, focusing on Latin America. Having used GitHub Copilot and Cursor, Salas said these tools help save time if users know how to use them. GitHub Copilot, agreed college student Aasritha M., is a “pretty cool extension.” She said she likes how Copilot recognizes the pattern of what the developer is doing and is about to do next. The tool almost never gets this wrong, she said. However, ChatGPT does a better job of finding mistakes in code, she said. Aasritha also has used Mistral and found it to be a pretty good tool, similar to ChatGPT.
Another college student, Sahil Shah, who recently did an internship at Lattice Semiconductor and works with Python, found GitHub Copilot “pretty useful when it comes to scripting.” Ratna Maharjan, lead product software engineer at information and services company Wolters Cluwer, also has found GitHub Copilot and ChatGPT “pretty helpful” in providing code snippets to use in his code. “So far, whatever I have seen is very, very good,” he said.
But attendees also expressed some dissatisfaction with AI tools. There are some things these tools are good at and some things they are bad at, Wessling said. “AI coding tools often do a good job with boilerplate code and producing volumes of code with repeating patterns that are well understood patterns,” he said. “They tend to not do well with libraries and library versions—remaining consistent on which library you’re importing and which method you’re using out of a given library.”
“They occasionally just hallucinate and provide sort of random answers,” Wessling added.
Shah said that the answers GitHub Copilot gives him are “sometimes vague.” Still, he is looking forward to using AI coding tools more, to make his work more effective.
Developer and retired physicist Peter Luh said he tested GitHub Copilot on four math problems during the conference, on February 13. “I’m sorry to report to you that Copilot failed miserably on all four problems,” he said. But Luh believes Copilot might be OK for general chats that include “hallucination” responses.
AI coding tools can give an illusion of getting to a solution quickly, Salas said. He believes AI plus human direction is better than just AI or the human in isolation. He said AI coding assistants definitely will get better, but today users need more technical nuance and need to know what to ask them. “Otherwise, you’re going to be spinning in circles,” due to the challenges their code often presents, he said.
{kind=link}
Avoiding the cloud migration graveyard 14 Feb 2025, 10:00 am
Fictional global retailer StyleHaven embarked on its cloud migration journey, eager to modernize its systems and improve its customers’ experience. StyleHaven opted to “lift and shift,” assuming its existing infrastructure would transfer to the cloud with few issues.
The result? Chaos. Data silos emerged and performance plummeted. Frustrated customers abandoned online shopping carts. StyleHaven faced significant revenue loss and reputational damage. Realizing their misstep, StyleHaven hit pause. They hired cloud specialists to reevaluate their architecture, prioritize data integrity, and implement strong devops practices. Then they rebuilt their cloud strategy with security and scalability in mind.
The result? A successful cloud transformation that streamlined operations, boosted sales, and delighted customers. StyleHaven learned a valuable lesson: Rushing into the cloud without a solid strategy is a recipe for disaster.
The health of your infrastructure
As a cloud computing veteran, I’ve seen the good, the bad, and the downright ugly when it comes to cloud migration. It’s no secret that many cloud migration projects stumble, leaving companies scrambling to pick up the pieces. The good news is that most of these failures stem from common issues that can be avoided entirely.
The problems often begin with a lift-and-shift approach. Companies eager to jump on the cloud bandwagon try replicating their infrastructure in a new environment with few adjustments. This rarely works. Unless you properly refactor the systems with a deep understanding of data complexities, you’re trying to fit a square peg into a round hole. I’ve seen firsthand how this approach leads to misaligned systems with crippling performance issues and ultimately, project failure.
So, what’s the solution? First and foremost, stop and assess. Before migrating a single byte of data, thoroughly audit your existing architecture. Understand your system’s intricate web of applications, data flows, and dependencies. This critical step lets you map a clear path to the cloud, ensuring your target environment seamlessly accommodates your data and applications.
Mishandling data during migration is a recipe for disaster. Ignoring data dependencies can lead to system outages, data loss, and significant financial repercussions. I always emphasize the importance of rebuilding data models and meticulously mapping every dependency to avoid these costly mistakes. Data is an absolute mess in most enterprises, and it’s expensive and risky to fix. This is where most of our technical debt comes from, and indeed, this is the source of most cloud migration failures.
Once you have a clear picture of your architecture and data, it’s time to rebuild your migration strategy with a strong emphasis on devops principles. Continuous integration and continuous delivery (CI/CD) strategies will streamline your development process, making it agile and adaptable to change. Remember, security can’t be an afterthought.
Don’t think that devops will save you; it won’t. It’s just one of many disciplines you must consider when fixing these issues. Also, be aware that many fix an architecture once and then resume their ad-hoc development habits. Companies that lack standard practices for development, testing, and deployment end up with chaotic and unstable cloud systems.
Finally, never underestimate the human factor. Many cloud migration failures stem from poor communication and a lack of skilled personnel. Empower your teams with the knowledge and expertise they need to navigate the complexities of the cloud. Encourage open and honest communication, addressing issues head-on instead of sweeping them under the rug. I’ve triaged the outcomes of too many bad decisions driven by workplace politics that led to millions of dollars in lost revenue. If someone is determined to execute a personal agenda, sometimes the only remedy is to let them go.
Rx for a healthy migration
The good news is that these pitfalls are avoidable. You can confidently navigate the complexities of cloud migration by embracing a strategic, data-driven approach and fostering a culture of collaboration, security, and open communication. Steps to avoid the pitfalls of cloud migration include:
- Don’t rush the process. Define clear business objectives for the migration. Carefully assess your existing infrastructure, data dependencies, and application requirements. Create a comprehensive road map with realistic timelines and resource allocation.
- Treat data as a critical asset. Thoroughly understand your data landscape, including dependencies and flows. Choose the right cloud data services for your needs. Prioritize data integrity and security throughout the migration process.
- Implement devops practices from the start. Foster collaboration between development and operations teams. Use automation to streamline workflows, reduce errors, and ensure continuous integration and delivery.
- Integrate security into every stage of the migration. Implement a zero-trust model, encrypt sensitive data, and continuously monitor for vulnerabilities. Ensure compliance with relevant security standards and regulations.
- Assemble a team with the necessary expertise. You’ll need people with skills in cloud technologies, data migration, security, and devops. Provide ongoing training and development opportunities to keep their skills sharp.
- Maintain open and transparent communication. Regularly update stakeholders on progress, challenges, and successes. Encourage feedback and promptly address concerns. This means kicking bad political actors off the stage if you have the power to do so.
The path to successful cloud migration is paved with awareness, planning, and execution. By understanding common pitfalls and embracing best practices, you can avoid the mistakes that land so many projects in the cloud migration graveyard. Remember, a failed cloud migration doesn’t have to be fatal. The right approach can be a valuable learning experience that propels you toward digital transformation.
{kind=link}
Buckle up for faster Python programs 14 Feb 2025, 10:00 am
In this edition of our biweekly Python newsletter: The next version of Python brings an all-new variety of speed boost. Python packages may soon pack better labeling for their ingredients. Cython 3.1 tees up new features for converting Python to C. And Python’s abstract base classes have an expressive power worth discovering.
Top picks for Python readers on InfoWorld
A new interpreter in Python 3.14 delivers a free speed boost
The next version of Python may come with major speedups at no cost to you apart from the version upgrade. Here’s how they did it.
Software bill-of-materials docs eyed for Python packages
A better “ingredients label” proposal for Python packages aims to make dependencies easier to trace—especially when those ingredients come from outside the Python ecosystem.
Exploring new features in Cython 3.1
The next, still-under-wraps version of Cython offers powerful new features to convert Python to C and make existing C code easier to use. See how they work.
The power of Python’s abstract base classes
Level up your use of programming abstractions in Python. Abstract base classes let you create objects that can be expanded on, for greater power and expression in your code.
More good reads and Python updates elsewhere
Efficiently Extending Python: PyO3 and Rust in Action
Rust is fast becoming a preferred way to expand Python’s functionality. One example, documented here: Pfuzzer, a fuzzy-search library for Python with a Rust back end.
Decorator JITs – Python as a DSL
How Python’s decorator pattern makes Python useful as a domain specific language—a way to use Python syntax to generate other kinds of code.
PyPI Now Supports Project Archival
Don’t make users guess if your project is an ex-project! The Python Packaging Index now lets you tag a project to indicate it’s no longer receiving updates.
Off-topic: Remember the guy who threw away a hard drive containing $750 million in Bitcoin? Now he wants to buy the dump where he thinks it’s buried
So you’re telling me there’s a chance?
{kind=link}
JetBrains’ Ktor adds CLI for simpler project creation 13 Feb 2025, 11:46 pm
JetBrains’ Ktor 3.1.0, an update to the Kotlin-based framework for asynchronous server-side and client-side applications, is now available, featuring a command-line tool for simpler creation of projects. The update also brings new features to server-sent events (SSE), which allow a server to continuously push events to a client over HTTP.
The 3.1.0 version, described by JetBrains as a minor release, was unveiled February 13. Instructions on getting started with Ktor can be found at ktor.io.
The new Ktor CLI tool offers an easy-to-use interface to generate project templates with the user’s preferred features, reducing boilerplate and setup times, JetBrains said. Running the ktor new command opens an interactive mode that allows the user to choose plugins and configure a project using the same options available in the Ktor Project Generator at start.ktor.io.
Also in Kotlin 3.1.0, server-side events (SSE) support has been upgraded with built-in serialization for both client and server, enabling them to handle SSE streams with automatic serialization and deserialization. SSE support now includes the ability to specify a heartbeat event to keep a session active, and the ability to enable a reconnection feature by setting the maxReconnectionAttempts property to a value greater than zero. If the client’s connection to the server is lost, it will wait for a specified reconnectionTime, then make maxReconnectionAttempts to reestablish the connection.
Elsewhere in Ktor 3.1.0:
- The CIO engine has been expanded to support wasm-js and js targets for both the server and client side. This makes CIO the first server-side JavaScript engine for Ktor.
- HttpClient has improved support for multipart requests, to make it easier to upload files and handle complex request bodies across different engines.
- To improve the API and docs process, a “Report a Problem” link for every API symbol has been made available both in the IDE’s help section and on api.ktor.io.
- The Compression plugin can be disabled for a specific request.
- Ktor now backs Unix domain sockets on native targets, enabling inter-process communication without relying on TCP.
- Beginning with Ktor 3.1.0, the Curl client engine is statically linked, eliminating the need to install third-party dependencies. This makes it easier to use Curl-based networking. Also, Arm architecture support has been added, including for macOS.
JetBrains also has introduced Ktor Library Improvement Proposals (KLIP), an initiative for the community to propose, discuss, and collaborate on new features and improvements for Ktor. The repository for KLIP is open for contributions. Everyone can participate in discussions or submit new proposals. Approved KLIPs are merged into the repository and will be implemented in the framework by the team.
Ktor 3.1.0 follows the October 2024 release of Ktor 3.0, which introduced support for SSE, brought WebAssembly support to the Ktor client, and switched to the kotlinx.io library.
{kind=link}
Diving into the Windows Copilot Runtime 13 Feb 2025, 10:00 am
Announced at the May 2024 launch of Arm-powered Copilot+ PCs, the Windows Copilot Runtime is at the heart of Microsoft’s push to bring AI inferencing out from Azure and on to the edge and our laptops. Since then it’s been released in drip-feed form with new features arriving every couple of months, many still tied to Insider builds of the Windows 11, Version 24H2 release.
Most of those new AI features have been user-facing, missing many of the key developer features necessary for third parties to build their own AI-powered applications. Much of the infrastructure needed to build Windows AI applications depends on the Windows App SDK, and the new APIs only finally arrived in the latest experimental channel release.
Channeling the Windows App SDK
The Windows App SDK is released in three channels: stable, preview, and experimental. The current stable channel is Version 1.6.4 and allows you to publish your code in the Microsoft Store. The next major release will be 1.7, which has had three different experimental releases to date. The latest of these, 1.7.0-experimental3, is the first to include support for Windows Copilot Runtime APIs, with a stable release due sometime in the first half of 2025.
This new release adds support for a neural processing unit (NPU)-optimized version of Microsoft’s small language model (SLM), Phi Silica. SLMs like Phi Silica provide many of the capabilities of much larger LLMs while running at lower power. Like OpenAI’s GPT, Phi Silica will respond to prompts, generate text, and provide summaries. It can also reformat text, for example creating tables. Other AI tools work with the Windows Copilot Runtime’s computer vision models, offering optical character recognition (OCR), image resizing, description, and segmentation. Interestingly, Microsoft is reserving access to these capabilities to code using the Windows App SDK.
Microsoft has already shown how it uses these models in Copilot+ PC tools such as the OCR-powered Recall semantic index, Click-to-Do, and an updated version of Windows Paint. By adding APIs in the Windows Copilot Runtime through the Windows App SDK, it’s making the same models available to your code so you can find your own uses.
Getting started with the Windows Copilot Runtime
Getting started with experimental Windows App SDK releases isn’t quick or easy and requires a Copilot+ PC running Windows 11, Version 24H2 in either the Windows Insider Beta or Dev channels. (You cannot use Canary builds yet.) Start with an up-to-date Visual Studio install, configured to build .NET desktop applications using the Windows 10 SDK. It’s important to make sure you’ve uninstalled Windows App SDK C# Templates before installing the SDK. This can be found in the Visual Studio Marketplace. Remember to enable support for preview releases before running the installer. Once the new release of the Windows App SDK moves to the stable channel, installation will be a lot easier, with fewer hoops to jump through.
Once the SDK is installed, you can build your first Windows Copilot Runtime applications. Like installation, this is still harder than it should be. You need to target specific builds of Windows 11 and specific versions of the .NET SDK, and if you don’t get these correct, code will not compile. I also couldn’t get Phi Silica to work from a console application, though it ran well enough as part of a WinUI application. However, these bugs are more than likely because this is the first public preview of the runtime APIs; the GitHub issues pages for this release show that these issues have affected other developers.
Using the Phi Silica small language model
Calling Phi Silica through the SDK is relatively simple. First ensure you’re using the Microsoft.Windows.AI.Generative namespace, calling the isAvailable method to ensure that your code is running on a system that includes the model. You can now create an asynchronous object to manage connections to Phi Silica, sending a string to it as a prompt and then retrieving the result when the asynchronous method used to call the connection returns.
The Windows Copilot Runtime APIs include support for content moderation, reducing the risk of it generating unwanted outputs. The level of moderation is customizable, allowing you to tune it appropriately. Some options return partial responses so you can keep users engaged while the model produces a complete response. Or you can force the model to format outputs, summarize content, and even rewrite it.
After all this time and several false starts, it’s nice to finally see some of my own code working on an Arm laptop’s NPU, with Task Manager showing the ONNX model loading and running. Qualcomm’s Hexagon NPU was originally designed for video and image processing and it shows. Image-based operations run very quickly and text generation takes its time. However, it was still faster than running a CPU-based model. Working through a local API was certainly easier than having to make a REST call to a cloud-hosted model. As a bonus, we no longer need to be tethered to a network connection.
When can I ship Windows Copilot Runtime applications?
Microsoft still has some work to do to get this version of the Windows App SDK ready for release, but at first glance, it’s finally delivered on the original Windows Copilot Runtime promise: a way to build AI applications in Windows without massive models or passing data to cloud-hosted services.
It will be a while yet before we see Windows Copilot Runtime applications in the Microsoft Store. Developers should have plenty of time to experiment and build applications that work both on Arm devices and on the latest x64 hardware from Intel and AMD. Bringing AI applications to the edge will reduce the load on data centers, as basic retrieval-augmented generation (RAG)-managed text generation and image processing don’t need to run in the cloud. With the Copilot Runtime we should see consumer AI applications running on our PCs, keeping our data on our hardware and letting large-scale enterprise AI applications take advantage of Azure’s dedicated AI hardware for training and at-scale inferencing.
Seeing what AI can do on a PC
Alongside the new Windows App SDK preview, Microsoft has rolled out a tool to show off the AI capabilities on a PC. Its AI Dev Gallery is intended to showcase Windows’ AI tools and its support for ONNX, and it highlights a set of common AI applications, from text operations to audio and video processing. Some of the samples show off integrating AI tools into common Windows controls, for example, adding semantic capabilities to a combo box.
There’s support for a selection of different models, with Microsoft’s own Phi 3 and Phi 3.5 at the top of the list for text and vision. Models can be downloaded as needed, with support for CPU and GPU ONNX runtimes. NPU support is missing, which is odd, as without it Microsoft can’t show the capabilities of its Copilot+ PCs.
Hopefully, this temporary oversight will be corrected in a future release. For now, the Gallery is worth exploring. I’d recommend sticking with one model where possible. Even though edge models are relatively small, they can still consume several gigabytes of memory and disk. A built-in model management feature lets you add and remove models from your local cache as necessary.
From AI project samples to production
Click the Code button in each sample to see the C# and XAML used or the Export button to create a Visual Studio project to build your own versions. This should allow you to port them to the latest Win App SDK and to Phi Silica. There is a way to include models in project directories as well, to help quickly test and debug code.
Microsoft’s bet on AI-powered PCs is taking time to pay off. Tools like Recall and Semantic Search have started to show the possibilities, but what’s needed is for Windows developers to start using AI accelerators and NPUs to deliver a new generation of desktop applications where AI can be embedded in controls as well as in natural language user interfaces.
With this first release of Windows’ on-device AI APIs, it’s time to start learning how to use them and what they’re good for. The 1.7 release of the Windows App SDK is “experimental,” so let’s experiment!
{kind=link}
How to use mutexes and semaphores in C# 13 Feb 2025, 10:00 am
Thread synchronization is used to prevent multiple threads from accessing a shared resource concurrently. The Mutex and Semaphore classes in .NET represent two of the most important related concepts. Let’s understand what both of these do and when we should use them.
Before we begin our discussion, let’s take a quick look at the basic concepts. A thread is the smallest unit of execution within a process. Multi-threading allows us to perform several tasks simultaneously. By synchronizing threads, we increase our application’s overall throughput and avoid problems like contention, deadlocks, and data loss.
Inter-process communication vs. inter-thread communication
When working with thread synchronization, you will often come across the terms “inter-process communication” and ”inter-thread communication.” Let’s understand the difference before we proceed with our discussion of mutexes and semaphores.
Inter-process communication refers to the communication between threads of separate processes on a given system, while inter-thread communication refers to the communication between threads of the same process. Keep in mind that the threads within a single process communicate significantly faster than threads in separate processes, because they are contained within the same memory space.
Mutexes and semaphores in .NET
A mutex is used to synchronize access to a protected resource or a “critical section” of code. (A critical section is code that must not be run by multiple threads at once.) Like a lock, a Mutex provides exclusive access to the resource, i.e., it allows one and only one thread to access the resource at a given point of time. Unlike a lock, a Mutex can be used to synchronize threads in different processes.
In .NET, we use the System.Threading.Mutex class to work with mutexes. When one thread acquires a lock on a Mutex object, all other threads are prevented from accessing the critical section until the lock on the Mutex object is released.
A semaphore is used to limit the number of threads that have access to a shared resource at the same time. In other words, a Semaphore allows you to implement non-exclusive locking and hence limit concurrency. You might think of a Semaphore as a non-exclusive form of a Mutex. In .NET, we use the System.Threading.Semaphore class to work with semaphores.
Create a mutex in C#
Let’s create a mutex object in .NET. Note that we use the WaitOne method on an instance of the Mutex class to lock a resource and the ReleaseMutex method to unlock it.
Mutex mutexObject = new Mutex(false, "Demo");
try
{
if (!mutexObject.WaitOne(TimeSpan.FromSeconds(10), false))
{
Console.WriteLine("Quitting for now as another instance is in execution...");
return;
}
}
finally
{
mutexObject.ReleaseMutex();
}
Let us now implement a real-life code example that uses a mutex to synchronize access to a shared resource. The following code listing demonstrates how you can use a Mutex object in C# to synchronize access to a critical section that writes data to a text file.
public static class FileLogger
{
private const string fileName = @"D:\Projects\MyLog.txt";
public static void WriteLog(string text)
{
using var mutex = new Mutex(initiallyOwned: false, "Global\\log");
try
{
mutex.WaitOne(1000);
File.AppendAllText(fileName, text);
}
catch (AbandonedMutexException)
{
mutex.ReleaseMutex();
mutex.WaitOne(1000);
File.AppendAllText(fileName, text);
}
finally
{
mutex.ReleaseMutex();
}
}
}
In the FileLogger class shown above, an attempt is made to acquire a mutex by blocking the current thread for 1000 milliseconds. If the mutex is acquired, the text passed to the AppendAllText method as a parameter is written to a text file. The finally block then releases the mutex by making a call to the ReleaseMutex method.
Note that the ReleaseMutex method is always called by the same thread that has acquired the mutex.
Create a semaphore in C#
To create a Semaphore in C#, we create an instance of the Semaphore class. When creating a Semaphore instance, you need to pass two arguments to its argument constructor. The first argument indicates the number of initial resource entries, and the second argument specifies the maximum number of concurrent resource entries. Note that if you want to reserve all slots for the new threads that will be created, you should specify identical values for both of these parameters.
The following code snippet illustrates how you can create a semaphore in C#.
public static Semaphore threadPool = new Semaphore(3, 5);
The statement above creates a semaphore object named threadPool that allows a maximum of five concurrent requests. Note that the initial count is set to three, as indicated in the first parameter to the constructor. This implies that two slots are reserved for the current thread and three slots are available for other threads.
Now let’s write some code that will give our semaphore some threads to manage.
Create multiple threads in C#
The following code snippet shows how you can create and start 10 threads using the Thread class available in the System.Threading namespace. Note that the ThreadStart delegate refers to a method named PerformSomeWork. We’ll create the PerformSomeWork method next.
for (int i = 0; i
Create a thread pool in C#
Below is the code for the PerformSomeWork method. This method uses our semaphore, threadPool, to synchronize the 10 threads we created above.
private static void PerformSomeWork()
{
threadPool.WaitOne();
Console.WriteLine("Thread {0} is inside the critical section...", Thread.CurrentThread.Name);
Thread.Sleep(10000);
threadPool.Release();
}
Refer to the PerformSomeWork method given above. The WaitOne method is called on the Semaphore instance to block the current thread until a signal is received. The Release method is called on the same instance to release the semaphore.
Complete semaphore example in C#
And here is the complete code listing of our semaphore example for your reference.
class SemaphoreDemo
{
public static Semaphore threadPool = new Semaphore(3, 5);
public static void Main(string[] args)
{
for (int i = 0; i
Final thoughts
The Mutex and Semaphore classes allow us to write efficient multi-threaded applications in C#. Understanding how they work is critical to building systems that can access shared resources safely and efficiently. Whereas a mutex provides exclusive access to a resource by one and only one thread at a time, a semaphore provides non-exclusive access to a resource by a limited number of threads. A semaphore maintains a count of the threads to restrict access to the critical section.
Another important difference between mutexes and semaphores is that mutexes enforce thread ownership but semaphores do not. With a mutex, only the thread that acquires a lock can release it. With a semaphore, any thread could release a lock acquired by another thread. This means that a programming mistake could result in errors or exceptions in the application. Programmers must take extra care with semaphores.
{kind=link}
Go 1.24 arrives with generic type aliases, boosted WebAssembly support 13 Feb 2025, 1:07 am
Go 1.24, an update to Google‘s popular open source programming language, is now generally available as a production release, with full backing for generic type aliases, performance improvements, and improved WebAssembly support. The release was unveiled February 11, and can be downloaded from Go.dev. Previously, a release candidate was published in mid-December.
Release notes for Go 1.24 note that the release brings full support for generic type aliases, in which a type alias may be parameterized like a defined type. For now, generic type aliases can be disabled by setting GOEXPERIMENT=noaliastypeparams. This parameter setting will be removed in Go 1.25.
For WebAssembly, Go 1.24 offers a go:wasmexport directive for Go programs to export functions to the WebAssembly host. The release also supports building a Go program as a WASI reactor/library.
With the go command in Go 1.24, Go modules now can track executable dependencies using tool directives in go.mod files. This removes the need for a previous workaround of adding tools as blank imports to a file conventionally named tools.go. The go tool command now can run these tools in addition to tools shipped with the Go distribution. Also with the go command, a new GOAUTH environment variable offers a flexible way to authenticate private module fetches.
Cgo, for creating Go packages that call C code, now supports new annotations for C functions to improve runtime performance. With these improvements, #cgo noescape cFunctionName tells the compiler that memory passed to the C function cFunctionName does not escape. Also, #cgo nocallback cFunctionName tells the compiler that the C function cFunctionName does not call back to any Go functions.
Other new features and improvements in Go 1.24:
- Multiple performance improvements to the runtime in Go 1.24 have decreased CPU overheads by 2% to 3% on average across a suite of representative benchmarks. These include a new builtin
mapimplementation based on Swiss Tables, more efficient memory allocation of small objects, and a new runtime-internal mutex implementation. - A new
testsanalyzer reports common mistakes in declarations of tests, fuzzers, benchmarks, and examples in test packages, such as incorrect signatures, or examples that document non-existent identifiers. Some of these mistakes might cause tests not to run. - The
cmd/gointernal binary and test caching mechanism now can be implemented by child processes implementing a JSON protocol between thecmd/gotool and the child process named by theGOCACHEPROGenvironment variable. - An experimental
testing/synctestpackage supports testing concurrent code. - The
debug/elfpackage offers support for handling symbol versions in dynamic ELF (Executable and Linkable Format) files. - For Linux, Go 1.24 requires Linux kernel version 3.2 or later.
Go 1.24 follows Go 1.23, released in August 2024, featuring reduced build times for profile-guided optimization.
{kind=link}
Snowflake announces preview of Cortex Agent APIs to power enterprise data intelligence 12 Feb 2025, 3:05 pm
Snowflake on Wednesday announced the public preview of Cortex Agents, a set of APIs built on top of the Snowflake Intelligence platform, a low-code offering that was first launched in November at Build, the company’s annual developer conference.
Asked at a press and analyst briefing held earlier this week how the most recent launch differs from what was introduced at Build, Baris Gultekin, head of AI at Snowflake, responded, “it is not a repeat” and that the agents are what Software Intelligence, which will be in private preview soon, builds on.
Cortex Agents, he said, “plan and orchestrate tasks, use tools such as Cortex Analyst and Cortex Search to execute them, reflect on the results, and improve responses. As part of the planning, they explore options, split into smaller tasks, and overall provide a very highly accurate scalable system.”
The company, he said, believes “that AI agents will soon be essential to the enterprise workforce. They’ll enhance the productivity for many teams such as customer support, analytics, engineering, and they’ll free up employee time to focus on higher value things. Data agents, which is a specialized category of AI agents, will combine data and tools to deliver accurate grounded insights by effectively selecting the right data sources.”
The new agents will be powered by Anthropic’s Large Language Model (LLM), Claude 3.5 Sonnet, selected by the company, according to a blog post, for its “performance across reasoning and coding skills.”
In November, Snowflake and Anthropic announced a multi-year strategic partnership in which the LLM would be available to Snowflake’s users for a number of its agentic AI products, including Snowflake Intelligence and Snowflake Cortex AI, the company’s managed AI service.
Cortex agents, the blog stated, orchestrate across “structured and unstructured data sources, whether they’re Snowflake tables or PDF files stored in object storage, to deliver insights. They break down complex queries, retrieve relevant data, and generate precise answers, using Cortex Search, Cortex Analyst and LLMs.”
“Agents use Cortex Analyst (structured SQL) and Cortex Search (unstructured data) as tools, along with LLMs to analyze and generate answers,” it added.
Agentic outputs, the blog stated, “are only as good as the quality of the underlying data and the accuracy of the retrieval systems that help ground them. Yet organizations struggle to pave a path to production due to an AI and data mismatch. LLMs excel at unstructured data, but many organizations lack mature preparation practices for this type of data; meanwhile, structured data is better managed, but challenges remain in enabling LLMs to understand rows and columns.”
Robert Kramer, VP and principal analyst at Moor Insights & Strategy, said that Snowflake initially introduced Cortex Agents in November of last year at its Build developer conference as part of Snowflake Intelligence, “stressing the potential for agentic AI app development and multimodal conversational AI.”
The latest announcement, he said, “expands on this by introducing a public preview of Cortex Agents, focusing on improving the accuracy of multi-agent systems to help users complete complex tasks. One of the critical elements I like about this announcement is that these agents have the potential to process large volumes of structured and unstructured data, benefiting data teams and business analysts involved in planning, reasoning, and collaboration.”
“The jewel of this release could be Snowflake’s partnership with Anthropic’s Claude, which enhances text-to-SQL tasks with Cortex Analyst, allowing users to ask questions in plain language and making data more accessible to non-technical users,” Kramer said.
This partnership, he said “should help enterprises deploy AI applications faster, with better accuracy, and automate complex workflows with Anthropic’s Claude. Snowflake is also introducing Cortex Search for data retrieval, improving data access and analysis.”
Kramer added “I always come back to processes, change management, and data management, in order to maximize agentic AI capabilities; organizations should ensure their data is well categorized and accessible to allow for structured and unstructured data to be fully leveraged.”
All these features, combined with Snowflake’s built-in governance and security measures, should help organizations manage and utilize data more effectively, he said.
At the briefing, Christian Kleinerman, executive vice president of product at Snowflake, said, “even though we’ve said it many times, that there is no AI strategy without data strategy, it’s been increasingly clear how customer after customer has been validating this sentiment. They say, ‘OK, I have access to a great model. But if I don’t have my data in order, if I don’t know governance, and if I don’t know what data sets I have, it is difficult to get value out of AI.’”
At the end of the day, he said, “what organizations really want is to be able to break down silos, eliminate copies, and be able to get as much value as possible from their data. And a lot of what we have done at Snowflake building the AI Data Cloud is about providing the choices for customers to be able to pursue the data architecture that they want.”
Snowflake’s Gultekin said security played a big role in the decision to partner with Anthropic. “Snowflake prioritizes security and privacy, and Anthropic is dedicated to building safe and reliable AI,” he said. “Claude is now running inside the Snowflake security boundary, so Snowflake customers can build and deploy AI systems while keeping their data governed.”
{kind=link}
Keep your code open to possibilities 12 Feb 2025, 10:00 am
I’ve been developing software for many years now. Decades. I’ve learned a lot along the way, and I dare to think that I’ve collected some wisdom about software development worth sharing with others. At some point, you think “Yeah, I’ve got a grip on this thing.”
And every once in a while, you have some revelation that is the culmination of what you’ve learned along the way. I’ll never forget the moment I understood dependency injection. Of course you would want to pass in an abstraction rather than create an implementation!
I had a similar revelation this week. I’m sure there are plenty of sager developers among you who have already figured this out, but it struck me suddenly that really good software design is all about keeping your options open for as long as possible—that you should defer any decisions to the very last minute.
Now, this seems counter-intuitive. We’ve always been told to plan everything out ahead of time. That we shouldn’t start the project without having thought about every detail that can be thought about. That we need to figure it out now so there are no surprises.
I can just imagine the conversation:
Engineering director: “How’s the planning going on the new project?”
Development lead: “Great, we’re ready to get started.”
Engineering director: “What database did you pick?”
Development lead: “Haven’t decided yet.”
Engineering director: “Authentication?”
Development lead: “Not yet.”
Engineering director: “Wait… what?!”
But the engineering director should be happy with those answers.
Hold out for abstractions
Making decisions early locks you into those solutions, usually allowing the solutions to drive the implementation. Making decisions about implementations drives you away from abstractions. Why abstract something that already exists?
I propose that this is exactly the wrong solution. Instead, you should ask the question “What is the abstraction that we need for our solution?” This is the very essence of what I consider to be the single most important thing you can do in software development: Code against abstractions and not implementations. The corollary to this maxim is some advice I tweeted six years ago:

IDG
The revelation for me was that if you think in terms of abstractions, and code against abstractions, you can—and should—defer your decisions about the implementations. The longer you don’t have an implementation, the less likely you are to be limited or driven in a specific direction or decision by that implementation. And the longer you let abstractions drive your decisions, the more likely it is that your solution will be uncoupled. If all you have are abstractions, then you can’t couple to implementations.
If you decide early on a relational database, and then as the project goes on, it becomes obvious that a NoSQL database is what you need, well, that can be a problem.
Leave the doors open
The goal should be to not even care what database you end up using or which authentication solution you use for your website. Ultimately, it will be easier and more effective to fit your implementation to your abstraction than to try to make your implementation match what you actually want to get done with your project. If the decision becomes moot, then you have created a system that is well-abstracted and thus well-designed.
This also goes a long way towards solving the biggest bogeyman of software development—the unknown unknowns. As long as you don’t have an implementation, you have freedom. The longer you can wait to choose or build an implementation, the greater flexibility you have to adapt to the unforeseen hurdles that will always crop up as you build your solution.
Deciding early on what implementation to use is like locking a door behind you and throwing away the key. The best software is built by keeping as many doors open for as long as possible, and by allowing yourself to walk back through the door if what you see on the other side isn’t to your liking. Keeping doors open allows you to move forward with more information and less regret.
Now, I realize that the real world enters into this, and ultimately you do have to choose some way to store your data and do your encryption and authenticate and authorize users. This isn’t about avoiding decisions. It’s about making them at the right time—with the right information. The longer you wait to decide the nuts and bolts of those things, the “cleaner” and more decoupled your system will be, and thus the easier it will be to change and maintain down the road.
So if you ever find yourself feeling pressured to lock in an implementation too soon, stop and ask “What’s the abstraction I really need?”
The best software is built on possibilities, not premature decisions.
{kind=link}
Dynamic web apps with HTMX, Python, and Django 12 Feb 2025, 10:00 am
Python is one of the most popular programming language today, in part due to its large ecosystem of tools for data science and AI applications. But Python is also a popular choice for developing web apps, particularly using the Django web framework. I’ve written a few articles demonstrating how HTMX integrates with different technologies and stacks, including Java (via Spring Boot) and JavaScript (via Bun, a JavaScript runtime). Now let’s take Python, Django, and HTMX out for a spin.
Django is a mature framework that can be combined with HTMX to develop fully interactive web applications without directly coding in JavaScript. To start, you’ll need to install Python 3, then install the Django framework. Once you have those set up in your development environment, you can create a directory and start a new project using the django-admin command:
$ mkdir quoteproject
$ django-admin startproject quoteproject quoteproject/
$ cd quoteproject
It’s also a good practice to set up an alias so $ python refers to the python3 runtime:
$ alias python=python3
If you need to access the development server from outside of localhost, you can modify the allowed host settings at quoteproject/settings.py:
ALLOWED_HOSTS = ['*']
Note that this allows all incoming requests, so it’s not very secure. You can fine-tune the setting to accept only your client IP. Either way, we can now run the development server:
$ python manage.py runserver 3000
If you want to listen for external hosts, use: $ python manage.py runserver 0.0.0.0:3000.
If you check the host server, you should see a welcome screen like the one here:
The components
We’ll build an application that lets us list and create quotes. I’ve used this example in previous articles, as it’s useful for demonstrating server-side application capabilities. It consists of three primary components, which we’ll build with Django and a dash of HTMX:
- Models
- Views
- Routes
As a model-view-template (MVT) framework, Django is slightly different from MVC (model-view-controller) frameworks like Express and Spring. But the distinction isn’t hugely important. A Django application’s main jobs of routing requests, preparing a model, and rendering the responses are all handled by well-defined components.
Django also ships with built-in persistence, which makes saving data and managing a schema in an SQL database very simple. Our application includes an SQLite database instance, which we‘ll use for development.
Now let’s look at the main components.
Developing the model in Django
We only need a single model for this example, which will handle quotes:
// quoteapp/models.py
from django.db import models
class Quote(models.Model):
text = models.TextField()
author = models.CharField(max_length=255)
from django.db import models
This is Django’s ORM syntax for a persistent object called Quote. It contains two fields: a large TextField called text and a 255-length CharField called author. This gives us a lot of power, including the ability to list and perform CRUD operations on Quote objects.
Whenever we make changes to the database, we can use Django’s tooling to update the schema:
$ python manage.py makemigrations
$ python manage.py migrate
The makemigrations command creates a new migration file if any schema changes are detected. (These are found in quoteapp/migrations, but you won’t typically need to interact with them directly.) The migrate command applies the changes.
Constructing the view
Next up, let’s consider the view, which accepts a request and prepares the model (if necessary), and hands it off to be rendered as a response. We’ll only need one view, found at quoteapp/views.py:
// cat quoteapp/views.py
from django.shortcuts import render
from django.template.loader import render_to_string
from django.http import HttpResponse
from .models import Quote
def index(request):
if request.method == 'POST':
text = request.POST.get('text')
author = request.POST.get('author')
if text and author:
new_quote = Quote.objects.create(text=text, author=author)
# Render the new quote HTML
html = render_to_string('quoteapp/quote_item.html', {'quote': new_quote})
return HttpResponse(html)
quotes = Quote.objects.all()
return render(request, 'quoteapp/index.html', {'quotes': quotes})
In this view, we import the Quote model and use it to craft a response in the index function. The request argument gives us access to all the information we need coming from the client. If the method is POST, we assemble a new Quote object and use Quote.objects.create() to insert it into the database. As a response, we send back just the markup for the new quote, because HTMX will insert it into the list on the front end.
If the method is a GET, we can use Quote.objects.all() to recover the existing set of quotes and send the markup for the whole page at quoteapp/index.html.
Django templates with HTMX
Quote_item.html and index.html are both templates. They let us take the model provided by the view and construct markup. These reside in a special template path. Here’s the simple quote item template, which renders an item:
// quoteapp/templates/quoteapp/quote_item.html
{{ quote.text }} - {{ quote.author }}
And here’s the main index template:
// quoteapp/templates/quoteapp/index.html
Quotes
{% for quote in quotes %}
- {{ quote.text }} - {{ quote.author }}
{% endfor %}
{% csrf_token %}
/python-django-htmx/quoteproject$ cat quoteapp/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name='index'),
]
These templates use the Django template language, which works similarly to Pug or Thymeleaf. Django’s template language lets us use HTML with access to the exposed Quote model. We use the {{ }} and {% %} variables and tags to access variables in Python. For example, we could use {% for quote in quotes %} to set up a loop that iterates over the quotes, exposing a quote variable on each iteration.
Because HTMX is simply an extension of HTML, we can use its properties in the Django template just like any other HTML:
- hx-post indicates this form should be
POSTed, and where to send the data. In this case, we’re posting to the index endpoint inviews.py.
- hx-target indicates where to put the response from the server. In this case, we want to append it to the list, because the server will send the new quote item.
- hx-swap lets us fine-tune exactly how the response is handled. In this case, we stick it
beforeend, meaning we want it to be the final element in the list.
Routing requests
Now we need to tell Django what requests go where. Django uses a project and app concept, where a single project can contain many apps. The basic routing occurs in the project, which was generated by the project creator. Now we’ll add a new route for our application:
// quoteproject/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('quoteapp.urls'))
]
The one we’re interested in is routing the root path (‘’) to the included quoteapp.urls, which we define here:
// quoteapp/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name='index'),
]
This also tells us where the empty ‘’ path should go, which is to call the index function we saw earlier in views.py. The name argument provides a handle to the path that we can use in links in the project. There’s more information about the path function and URL handling in the Django docs.
Run the app
We’re almost ready to run and test the application. A final step is to tell Django the quoteapp is part of the quoteproject, which we do in settings.py:
// quoteproject/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'quoteapp'
]
In this case, we’ve added the quoteapp directory to the INSTALLED_APPS array.
Now if we run the app with $ python manage.py runserver 3000, we’ll see a simple but functional UI:
Conclusion
This article demonstrated the basic elements of building a web application using Python, Django, and HTMX. Without much more work, we could use the same routing and endpoint logic to build APIs (consider Django REST). Django is a well-designed and mature framework for Python; it works smoothly and rarely gets in your way. Django is geared toward SQL databases, so it may not be the best choice if you prefer to use a NoSQL database like MongoDB. On the other hand, it makes using SQL data stores very convenient.
If you’re a Python developer, Django is a clear winner for building SQL-based, data-driven web applications. For more straightforward RESTful APIs, you might want something more focused like Falcon or Flask.
Not surprisingly, the experience of using Python, Django, and HTMX together is comparable to using HTMX with Java and Spring Boot or JavaScript and Express, or C# and .Net. Regardless of the framework or stack you choose, it seems that HTMX serves its purpose well, in making everyday HTML UIs more powerful with a minimum of additional coding.
{kind=link}
Rust memory management explained 12 Feb 2025, 10:00 am
The Rust programming language shares many concepts with other languages intended for systems programming. For instance, Rust distinguishes between memory allocated from the stack and memory allocated from the heap. It also ensures that variables declared within a scope are unavailable outside of that scope.
But Rust implements these behaviors in its own way, with significant implications for how memory management works. Rust uses a variety of ownership metaphors to describe how resources are created, retained, and disposed of during a program’s lifetime. Learning how to work with Rust’s concept of ownership is an important rite of initiation for Rust programmers. This quick guide will help you get started.
How Rust manages scope
In C++ and other languages, there’s a rule called RAII: Resource acquisition is initialization. The resources for an object (like memory) are tied to how long it lives in a program. Rust also employs this rule, which prevents resources from being freed more than once, or used after being deallocated.
In Rust, as in other languages, all objects have a scope, such as the body of a function or a manually declared scope. An object’s scope is the duration for which it’s considered valid. Outside of that scope, the object doesn’t exist—it can’t be referenced, and its memory is automatically disposed of. Anything declared inside a given scope only “lives” as long as that scope does.
In the following example, data will live throughout main(), including in the inner scope where other_data is declared. But other_data is only available in the smaller scope:
fn main() {
let mut data = 1;
{
data = 3;
let mut other_data = 2;
}
other_data=4;
}
Compiling this code generates the error: cannot find value `other_data` in this scope on the next-to-last line.
When something falls out of scope, it is not only inaccessible but its memory is automatically freed. What’s more, the compiler tracks the availability of an object through the course of a program, so attempting to access something after it has fallen out of scope triggers a compiler error.
The previous example uses stack-allocated variables for all its variables, which are fixed in size. However, we can use the Box type to get heap-allocated variables, where the size may vary and there is more flexibility of use.
fn main() {
let mut data = Box::new(1);
{
data = 3;
let mut other_data = Box::new(2);
}
other_data=4;
}
This code also won’t compile at first, for the same reasons. But if we modify it slightly, it will:
fn main() {
let mut data = Box::new(1);
{
data = 3;
let mut other_data = Box::new(2);
}
}
When this code runs, other_data will be heap-allocated inside the scope, and then automatically deallocated when it leaves. The same goes for data: it will be created inside the scope of the main() function, and automatically disposed of when main() ends. All of this is visible to the compiler at compile time, so mistakes involving scope don’t compile.
Ownership in Rust
Rust adds another key idea to scoping and RAII: the notion of ownership. Objects can have only one owner, or live reference, at a time. You can move the ownership of an object between variables, but you can’t refer to an object mutably in more than one place at a time.
fn main() {
let a = Box::new(5);
let _b = a;
drop(a);
}
In this example, we create the value in a with a heap allocation, then assign _b to a. By doing this, we’ve moved the value out of a. So, if we try to manually deallocate the value with drop(), we get an error: use of moved value: `a`. Change the last line to drop(_b), though, and everything is fine. In this case, we’re manipulating that value by way of its current, valid owner.
A function call can also take ownership of what is passed to it. Consider the following, adapted slightly from Rust By Example:
fn bye(v:Box){
println!("{} is not being returned", v);
}
fn main() {
let a = Box::new(5);
let _b = a;
bye(_b);
drop(_b);
}
If we try to compile this code, we’ll get the error use of moved value: `_b` at the line drop(_b).
When we call bye(), the variable passed into it gets owned by bye(). And since that function never returns a value, that effectively ends the lifetime of _b and deallocates it. The drop() would have no effect even if it were called. On the other hand, this would work:
fn bye(v:Box)-> Box{
println!("{} is being returned", v);
return v;
}
fn main() {
let a = Box::new(5);
let _b = a;
let mut c = bye(_b);
c = 32;
drop(c);
}
Here, we return a value from bye(), which is received into an entirely new owner, c. We can then do whatever we like with c, including manually deallocating it.
Something else we can do when we change owners is alter the mutability rules. An immutable object can be made mutable and vice versa:
fn bye(v:Box)-> Box{
println!("{} is being returned", v);
return v;
}
fn main() {
let a = Box::new(5);
let _b = a;
let mut c = bye(_b);
*c = 32;
drop(c);
}
In this example, a and _b are both immutable. But c is mutable, and once it takes ownership of what a and _b referred to, we can reassign it (although we need to refer to it as *c to indicate the value contained in the Box).
It’s important to note that Rust enforces all of these rules ahead of time. If your code doesn’t honor how borrowing and scope work, it simply won’t compile. This ensures that whole classes of memory bugs will never make it to production. But it requires programmers to be scrupulous about what gets used where.
Automatic memory management and Rust types
I’ve mentioned using the Box type to heap-allocate memory and automatically dispose of it when it goes out of scope. Rust has a few other types that can be used to automatically manage memory in different scenarios.
An Rc, or “reference counted” object, keeps track of how many clones are made of the object. When a new clone is made, the reference count goes up by 1; when a clone goes out of its scope, the reference count drops by 1. When the reference count reaches zero, the Rc object is dropped. Likewise, the Arc type (atomic reference count) allows for this same behavior but across threads.
A key difference between Rc/Arc and Box is that a Box lets you take exclusive ownership of an object and make changes to it, while Rc and Arc share ownership, so the object can only be read-only.
The Rc/Arc objects follow the same rules as Boxes: they’re bound by Rust’s larger dictates around lifetimes and borrowing. You can’t use them to perform an end-run around those checks. Do use them when the structure of a program makes it hard to tell how many readers will exist for a given piece of data.
One more type used for mutable memory management is RefCell. This type lets you also have a single mutable reference or multiple immutable references, but the rules about such use are enforced at run time, not compile time. However, RefCell has two strong rules: it can only be used in single-threaded code, and if you break the borrowing rules of a RefCell at run time, the program will panic. Thus a RefCell works only for a narrow range of problems that are exclusively solved at run time.
Rust memory management vs. garbage collection
Even though Rust has types that allow reference counting, a mechanism also used in garbage-collected, memory-managed languages like Java, C#, and Python, Rust is generally not thought of as a “garbage-collected” or “memory-managed” language. Memory management in Rust is planned deterministically at compile time, rather than handled at run time. Even reference-counted types have to obey Rust’s rules for object lifetimes, scoping, and ownership—all of which must be confirmed at compile time.
Also, languages with runtime memory management generally don’t offer direct control of when or how memory is allocated and reclaimed. They may give you some high-level knobs to tune, but you don’t get the granular control you do in Rust (or C, or C++). It’s a tradeoff: Rust requires more work ahead of time to ensure every use of memory is accounted for, but it pays off at run time with faster execution and more predictable and reliable memory management.
{kind=link}
Don’t use public ASP.NET keys (duh), Microsoft warns 12 Feb 2025, 3:50 am
Microsoft Threat Intelligence in December observed a “threat actor” using a publicly available ASP.NET machine key to inject malicious code and fetch the Godzilla post-exploitation framework, a “backdoor” web shell used by intruders to execute commands and manipulate files. The company then identified more than 3,000 publicly disclosed ASP.NET machine keys—i.e., keys that were disclosed in code documentation and repositories—that could be used in these types of attacks, called ViewState code injection attacks.
In response, Microsoft Threat Intelligence is warning organizations not to copy keys from publicly available sources and urging them to regularly rotate keys. In a February 6 bulletin, Microsoft Threat Intelligence said that in investigating and protecting against this activity, it has observed an insecure practice whereby developers used publicly disclosed ASP.NET machine keys from code documentation, repositories, and other public sources that were then used by threat actors to perform malicious actions on target servers. While many previously known ViewState code injection attacks used compromised or stolen keys that were sold on dark web forums, these publicly disclosed keys could pose a higher risk because they are available in multiple code repositories and could have been pushed into development code without modification, Microsoft said. The limited malicious activity Microsoft observed in December included the use of one publicly disclosed key to inject malicious code. Microsoft Threat Intelligence continues to monitor the additional use of this attack technique, Microsoft said.
ViewState is the method by which ASP.NET web forms preserve page and control between postbacks, Microsoft Threat Intelligence said. Data for ViewState is stored in a hidden field on the page and is encoded. To protect ViewState against tampering and disclosure, the ASP.NET page framework uses machine keys. “If these keys are stolen or made accessible to threat actors, these threat actors can craft a malicious ViewState using the stolen keys and send it to the website via a POST request,” Microsoft Threat Intelligence said in the bulletin. “When the request is processed by ASP.NET Runtime on the targeted server, the ViewState is decrypted and validated successfully because the right keys are used. The malicious code is then loaded into the worker process memory and executed, providing the threat actor remote code execution capabilities on the target IIS web server.”
{kind=link}
Page processed in 0.579 seconds.
Powered by SimplePie 1.3.1, Build 20121030095402. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.